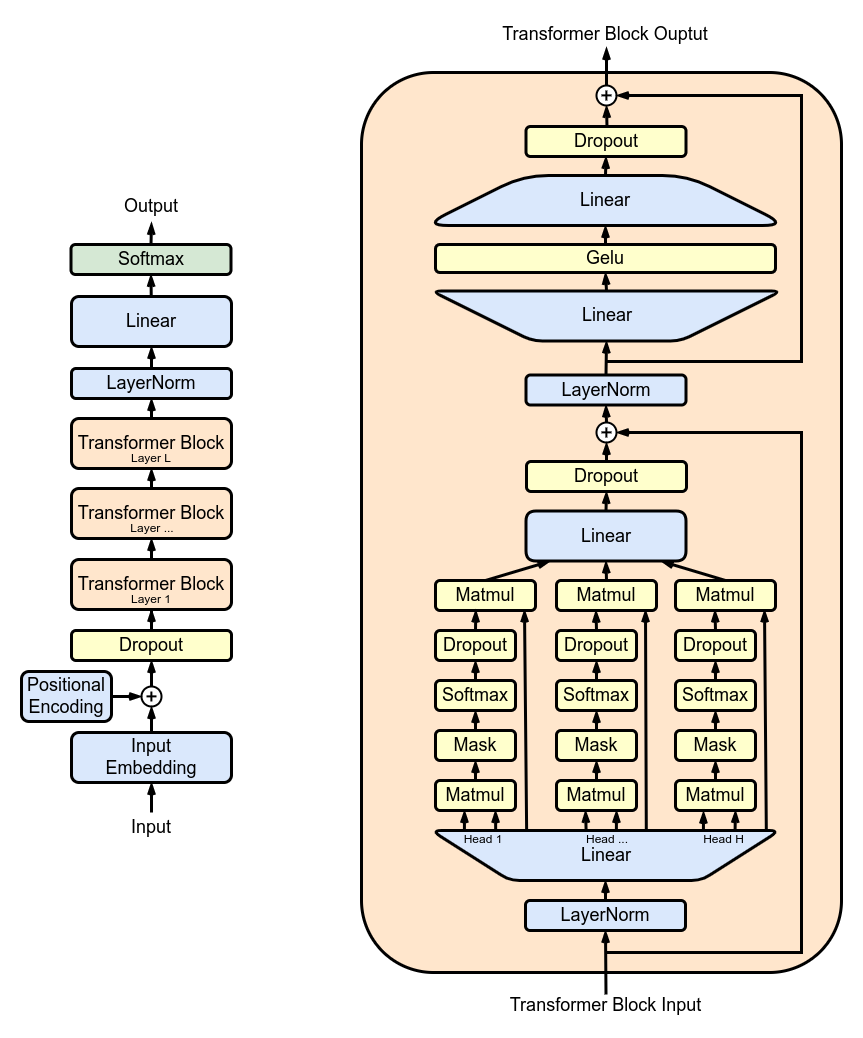
classSingleHeadAttention(QGPT2): """Class representing a single attention head implemented with quantization methods."""
defrun_numpy(self, q_hidden_states: np.ndarray):
# Convert the input to a DualArray instance q_x = DualArray( float_array=self.x_calib, int_array=q_hidden_states, quantizer=self.quantizer )
# Extract the attention base module name mha_weights_name = f"transformer.h.{self.layer}.attn."
# Extract the query, key and value weight and bias values using the proper indices head_0_indices = [ list(range(i * self.n_embd, i * self.n_embd + self.head_dim)) for i in range(3) ] q_qkv_weights = ... q_qkv_bias = ...
# Apply the first projection in order to extract Q, K and V as a single array q_qkv = q_x.linear( weight=q_qkv_weights, bias=q_qkv_bias, key=f"attention_qkv_proj_layer_{self.layer}", )
# Extract the queries, keys and vales q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}") q_q, q_k, q_v = q_qkv.enc_split( 3, axis=-1, key=f"qkv_split_layer_{self.layer}" )
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。