本文将从 e2e 的基本介绍,e2e 的使用与扩展,session 日志隔离三个维度为大家带来 ChunJun e2e & session 日志隔离的分享。
大量具体代码和演示请看视频教程⬇️
视频课程:
https://www.bilibili.com/video/BV1ru411P7oZ/?spm_id_from=333.999.0.0
课件获取:
https://www.dtstack.com/resources/1052?src=szsm
ChunJun 为何选择 e2e 测试
ChunJun 项目是基于 Flink 进行扩展,并开发了大量插件来支持数据同步和 SQL 执行,当前支持的数据源插件已经超过50个,所以如何保证各个插件的质量是 ChunJun 非常迫切的需求。以下是两种测试方式:
● 单元测试
· 目的:测试代码的单个部分(例如函数、方法或类)以确保它们按预期工作
· 速度:通常非常快,因为它们只测试小的代码片段,并且经常在隔离的环境中运行,不依赖外部资源
· 范围:覆盖范围有限,虽然单元测试可以高效得捕获代码的逻辑错误,但它们不能检测集成错误或复杂的交互问题
● 端到端测试(e2e测试)
· 目的:模拟真实场景来验证整个系统的行为,它从用户的角度测试应用程序,确保所有组件(前端、后端、数据库、其他服务等)一起工作
· 速度:相对较慢,因为它们经常需要启动整个应用程序,与真实的数据库或外部服务进行交互
· 范围:更全面地测试整个应用程序的工作流程,它们可以捕获在单元测试中可能被遗漏的错误,如集成问题、配置错误、网络问题等
使用单元测试,大量历史插件的单测补充,成本太大,且单测的质量以及范围等都很难把控。而 e2e 测试只需要编写各种插件的脚本并直接运行,并根据任务结果来判断对应插件的可用性,这是一种比较方便并且更加全面的测试方法,所以我们选择了增加 e2e 模块来验证各个插件。
e2e 的使用与扩展
e2e 使用-模块介绍
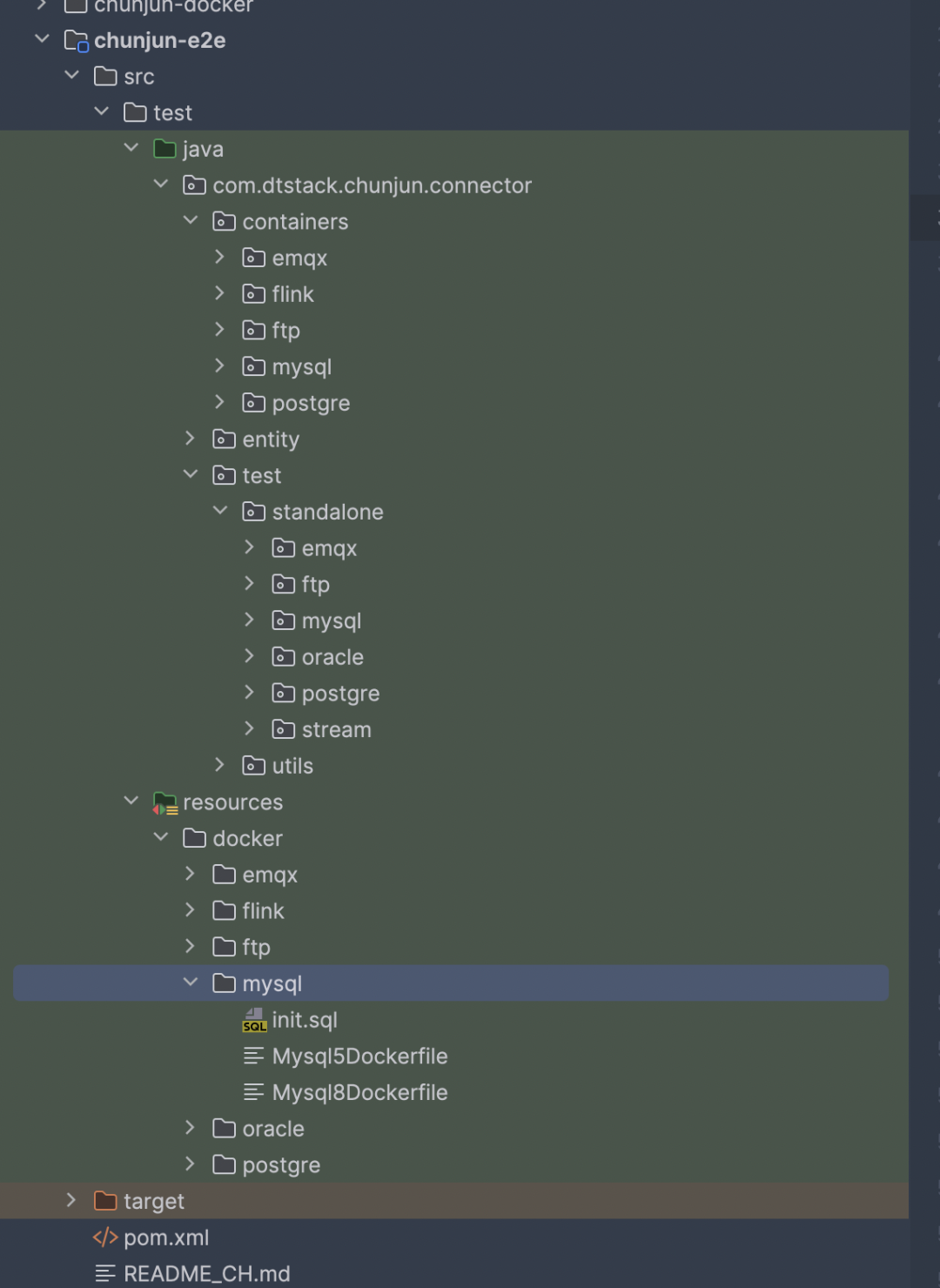
ChunJun-e2e 模块如下图所示:
![file]()
e2e 模块主要分为3部分:
· containers 模块:基于 TestContainer 扩展的各个数据源 container
· test 模块:e2e 测试的各个插件入口
· resources 里的 docker 模块: 各个数据源的 DockFile
ChunJun-e2e 模块整合了 ChunJun-client 模块,主要是借助 TestContainer 在 Docker 环境中启动 Flink 的 standlone 环境以及各个数据源。因此只需要编写需要测试的 json 文件之后,通过 ChunJun-client 模块快速提交任务到 standalone 集群中进行任务的运行,并根据任务运行结果等信息来判断任务是否通过。
当前 ChunJun-e2e 模块已经支持了 MySQL、PgSQL、Oracle、FTP、EMQX 的测试,后续社区会持续性的补充 e2e 测试的插件。
e2e 使用-代码分析
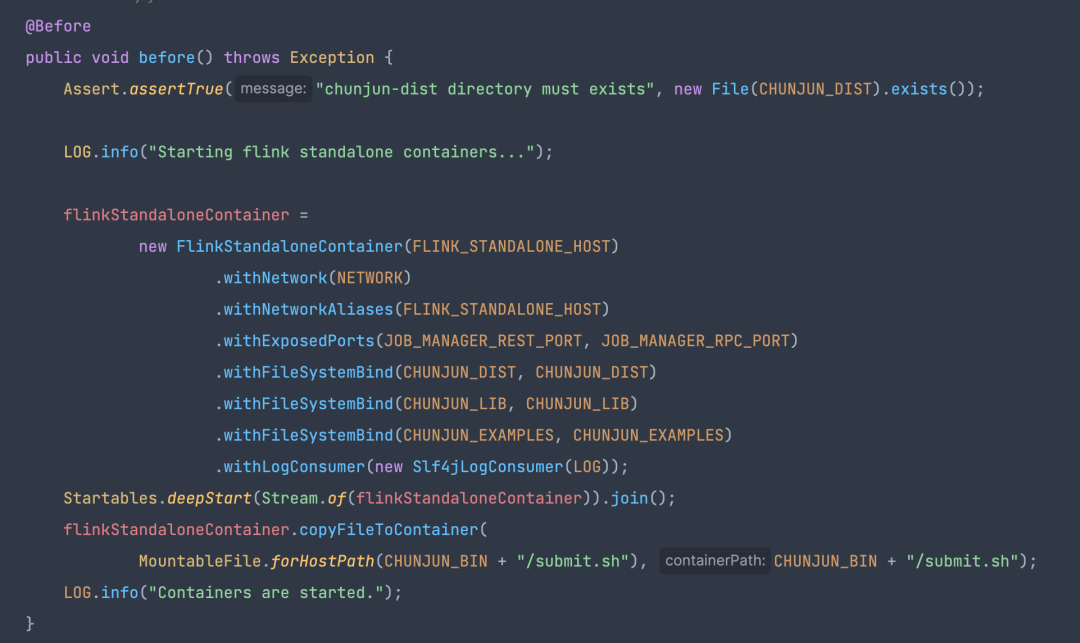
● ChunJunFlinkStandaloneTestEnvironment
· 内部封装了一个 Flink 环境
· 提交任务和等待任务结束的方法
内置的 flinkStandaloneContainer 即为任务运行时所在的 flink standlone 集群。
![file]()
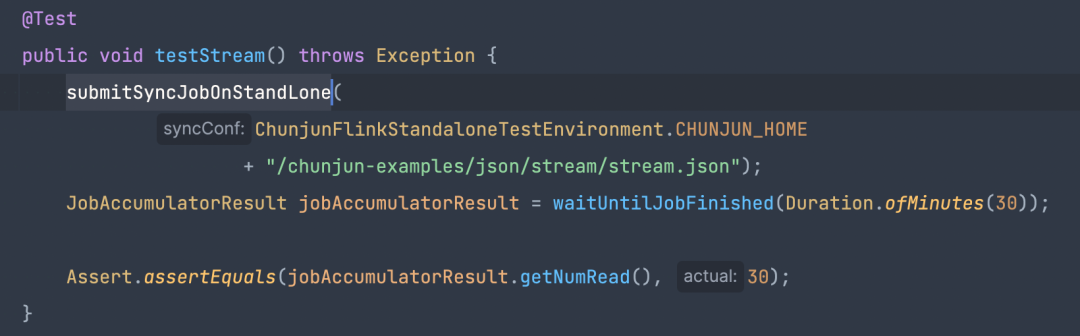
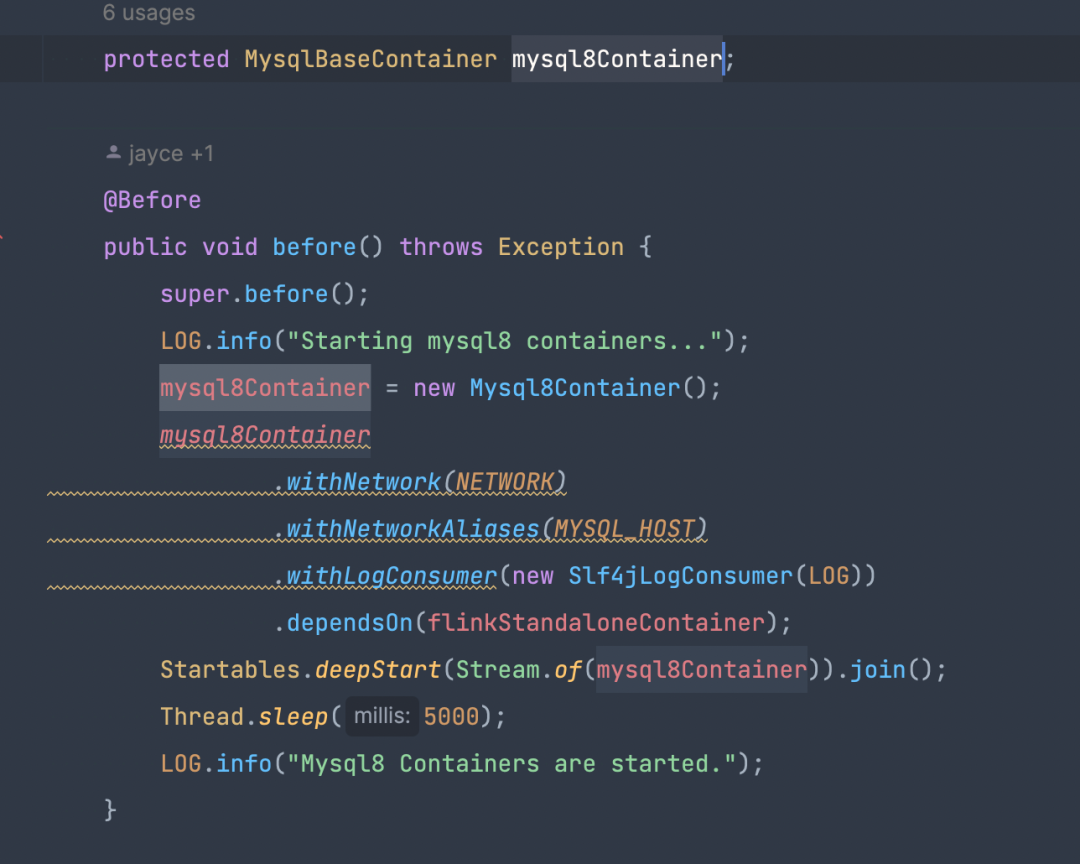
● 对 stream 插件的测试用例
test 方法里只需要 submitSyncJobOnStandLone 提交 json 脚本到 Flink 的 stabdlone 集群里,通过 waitUntilJobFinished 获取任务结果并进行判断。
![file]()
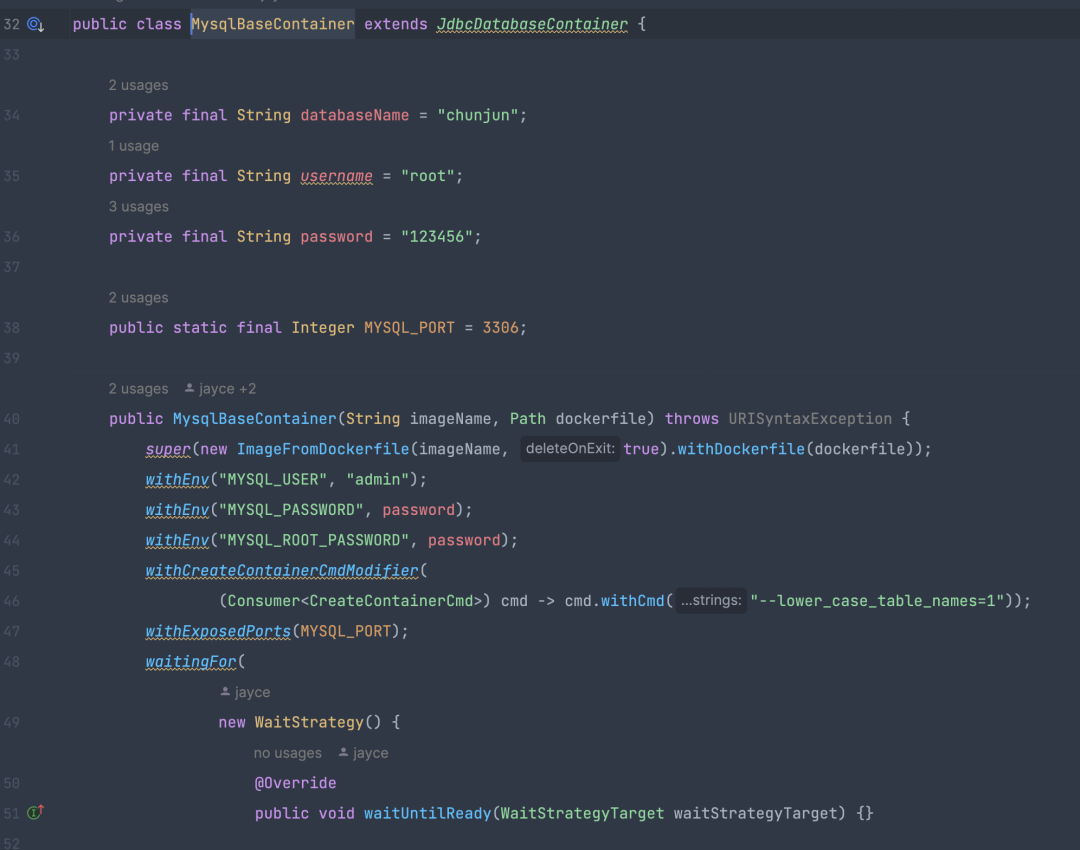
e2e 使用-贡献 e2e 插件
贡献贡献 e2e 插件的简单流程:
· 编写所需数据源的 DockerFile 文件
· 基于 TestContainer 和第一步的 DockerFile 创建对应的数据源 container
· 编写插件任务 json 脚本
· 继承 ChunjunFlinkStandaloneTestEnvironment,通过内置的提交方法提交任务即可
![file]()
基于 TestContainer 进行扩展也是很简单的,只需要继承 GenericContainer 类,传递 DockerFile 文件路径即可,TestContainer 对于 JDBC 类型数据源提供了 JdbcDatabaseContainer 抽象类。
框架所需要的环境 提交等接口都已经在 ChunJunFlinkStandaloneTestEnvironment 提供了,只需要编写对应的数据源 DockerFile 和 json 脚本即可。
![file]()
session 日志隔离
session 日志隔离-介绍
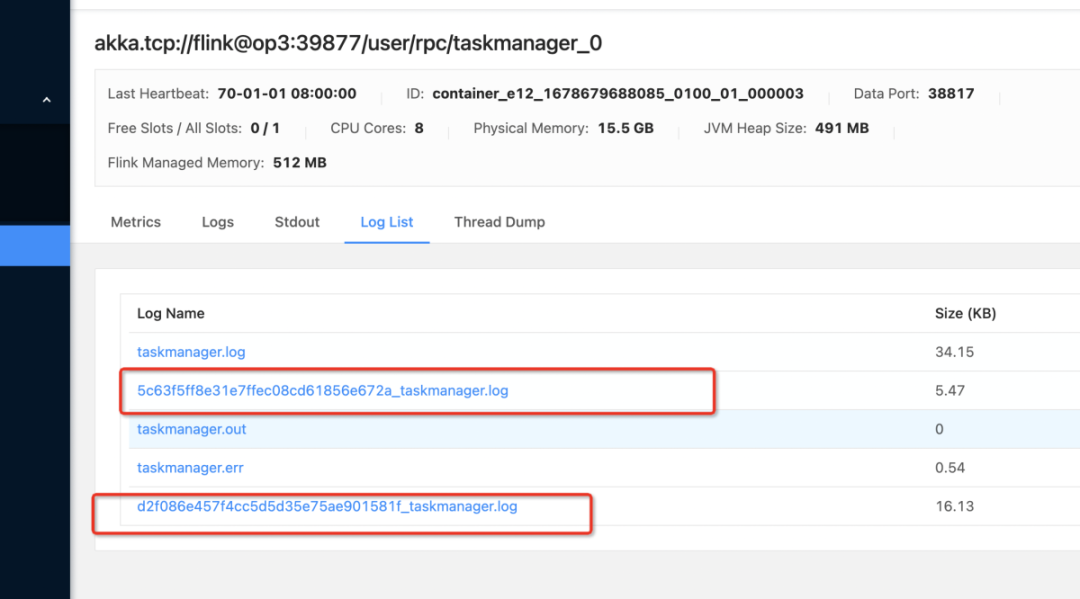
Flink on session 场景下,如果 TaskManager 不关闭,那么这个 TaskManager 里的所有任务都会写入同一个日志文件中,导致需要查看任务日志排查问题时,比较难查找到具体的每个任务日志。
如果 TaskManager 里的每个任务的日志都在不同的日志文件里,每个日志文件的名称就是 jobid,那么在查看任务日志时只需要查看 jobid 的日志文件即可。
为了解决这个问题,袋鼠云内部通过修改 Flink 源码以及 Log4j 的扩展,实现了 Flink on session 场景下,TaskManager 里每个任务的日志会写入对应的 jobid 日志文件里。
![file]()
Flink 源码改动
TaskExecutor 在接受到任务之后,会转为 Task 对象。Task 对象是一个 Runnable 实现,内部持有一个线程,然后通过其内部线程执行客户代码逻辑。
因此每个 Task 都由一个 Thread 对应,在 Task 整个生命周期里,其 Thread 和 Task 都是绑定的。因此在 Run 的时候,将 jobId 放入 ThreadLocal 里即可。
之后,我们需要在Flink 源码中的org.apache.flink.runtime.taskmanager.Task#run里加上 MDC.put("jobId", jobId.toString()); 即可。
父子线程场景下需要加上下述参数:
env.java.opts.taskmanager: "-DisThreadContextMapInheritable=true" ![file]()
Log4j 扩展
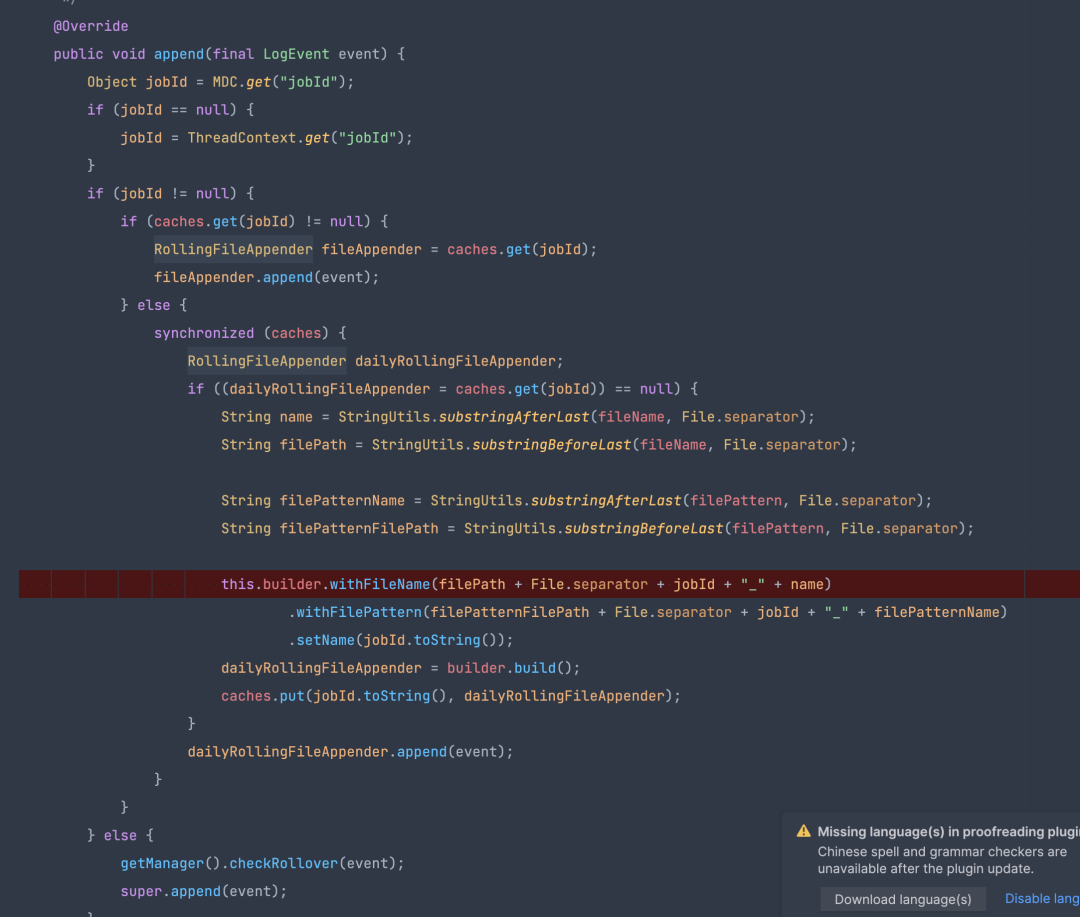
Flink1.12 支持 Log4j2 进行日志输出,在日志隔离方案中通过扩展 Log4j2 的 AbstractOutputStreamAppender,实现了通过一个自定义的 appender 来完成日志输出。
自定义的 appender 可以根据 MDC 里的 jobid 输出到对应的日志文件,因此其扩展逻辑为根据 MDC 里的 jobid 是否为空。如果不为空,则输出到 jobid 对应的文件,否则就是默认的 taskmanager.log。
![file]()
最终日志隔离方案流程如下:
· 修改 Flink 源码,增加 MDC.put("jobId", jobId.toString())
· 打包 Flink 源码,将 Flink-dist 替换开源的 Flink-dist
· 基于 Log4j2 扩展 appender,并打包后的 jar 放入 Flink 的 lib 目录下
· 修改 Flink conf 目录下的 log4j.properties 文件,将 RollingFileAppender 替换为自定义的扩展 apped 类即可
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack