本文分享自华为云社区《【干货】华为云图数据库GES技术演进》,作者: Chenyi。
1 背景
大规模图数据无处不在,图查询、分析和表示学习已成为大数据和AI的核心部分之一。特别是知识图谱和图神经网络的发展,Graph已成为未来AI的基础。
各式各样的图数据
![]()
面向未来,图数据库在数据规模、多维关系、时空动态性、异构计算体现上面临着新挑战:
1、图数据规模不断增长,万亿边超大规模图普遍存在,对产品性能和可扩展性提出新的需求。
2、时空图、异质和多关系图在政务、安平、金融、知识图谱等领域越来越普遍,对产品的图数据模型和存储带来新的需求。
3、图神经网络等图表示学习的兴起,需要新的计算框架支持,为传统深度学习框架和图计算框架的融合带来新的机会。
4、GPU、FPGA和图加速器异构计算系统为图引擎带来新的需求和机会。
![]()
Graph是大数据分析平台的重要组成部分,在传统批流分析之外提供更多的高级分析能力;主要分为图数据库和图计算引擎两大能力:
- 图数据库,具备图存储和计算能力,支持事务、数据更新、查询语言,偏TP类场景,用于实时要求高、逻辑相对简单的场景。例如:寻找两商户间最短路径;查找疑似洗钱卡的转账路径。
- 图计算引擎,侧重复杂查询和全局计算,使用图分析算法,偏AP类场景,用于实时要求不高、数据量大的场景。例:生成持卡人关系网络,根据套现模型批量输出套现卡。
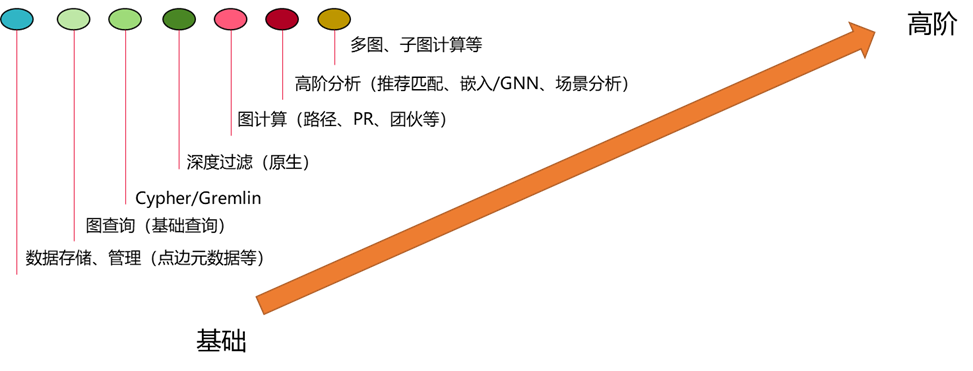
概况说来,Graph的核心能力是:“深度关系挖掘”、“关系高效查询”、“高效社团分析”、“路径直观显示”。
![]()
一个用Graph来分析【疫情传播】的例子
1.1 趋势1:面对海量多样化数据,数据分析变得更复杂,图相关技术迅速普及
Gartner曾在多次分析师报告中提及图技术的重要性:
- Gartner把Graph以及相关的技术列为2021数据以及分析技术相关10大趋势之中。
- Gartner预测到2025年, 图相关技术使用率会从10%(2021)增长到80%。
- “到2023年,图计算将促进全球30%企业的快速决策场景化。需要图还是不需要?这已不再是个问题,一定是需要。”
![]()
1.2 趋势2: 各家查询语言不一,有碍图数据库普及,GQL有望成为统一语言
历史上,图数据库并没有标准的查询语言,只有Cypher和Gremlin这种事实标准(即使用的比较广泛产品的查询语言),且新产品也不断衍生各自的查询语言,语法的不统一令使用门槛增高,对本领域的普及造成了不利影响。
GQL由WG3主导(WG3 从1987年起负责SQL标准的制定)。GQL 将建立在 openCypher Morpheus 的基础上(它将 Cypher 引入到 Apache Spark),并结合来自 LDBC 的 G-CORE 的灵感,为用户提供了一种组合图查询语言,支持所有那些功能,这将使 GQL 在概念上等同于 SQL。
![]()
2 技术洞察
2.1 图数据库主流系统技术分析
![]()
上表列举了主流图数据库系统的分析情况,我们的观点是:
- 图数据库相比于关系型数据库发展落后(多租户和云原生能力匮乏,查询优化能力普遍不足)
- 主流图数据库高并发混合负载差
- 不支持高并发下混合负载查询性能隔离
- 不支持多查询查询QoS(Quality of Service)
- 对于混合型负载(大小graph query混合)几乎没有针对性优化
- 主流图数据库对于融合数据分析(query类型混合)几乎不提供任何优化
- 绝大多数系统不具备融合分析能力
- 少数系统具体初级的融合分析能力, 但是不具备对于融合查询进行整体优化
- 主流图数据库对云原生的支持差
2.2 图分析、图学习主流系统技术分析
![]()
上表列举了主流图分析、图学习系统的分析情况,我们的观点是:
- 主流图分析系统面向大规模图场景,以分布式内存架构为主,多定位离线图计算,不支持实时数据更新,对复杂OLAP类的交互式查询支持较弱。
- 主流图学习系统构建于现有的深度学习系统,以PyTorch为主,分布式训练的性能一般。
- 主流图分析系统和图学习系统是割裂的,一般通过文件来交互,在统一图采样、图与NN融合调度上可以进一步优化。
- GPU、FPGA等异构体系探索还比较初级。
![]()
总结来说,图数据库和图引擎面向广泛的使用场景,提供的能力一定也是从基础往高阶发展的,技术洞察中标识为红色的部分,也是我们认为提供高阶能力所必备的差异化竞争力。
3 华为云图数据库技术演进
华为云图数据库(GES)自2018年上线以来,经历过3个时期,从18年到21年为1.0时代,从22年到现在为2.0时代,未来将会往3.0时代演进。
![]()
下图展示GES各个版本的技术架构以及相对应的特点,在后面的部分会详细展开分析。
![]()
3.1 GES 1.0:查询分析一体化、高性能
GES 1.0是基于分布式内存架构的,主打查询分析一体化和高性能的查询和分析。通过只存一份数据,可以较好的兼顾了图查询任务和图分析任务,比如数据增删改能够立马被查询到,快速参与后续的计算任务,省去了不同系统的数据同步。当然,该架构由于采用分布式内存的方式来存储全量数据,相较于持久化方案来说成本会较高,极端情况下的故障恢复较长。但总体来说,应对百亿规模的图数据处理和分析还是能够轻松应对的。
![]()
3.2 GES 2.0:大规模、持久化、DSL、动态图
GES 2.0是当前产品重点发展的技术路径,核心是面向千亿到万亿的图数据规模,通过持久化存储来降低成本,同时兼顾查询效率、计算性能和使用上的便捷性。这里,我们将图数据库和图计算引擎解耦开了,各个组件直接独立演进,同时统一存储里的数据同步是由系统内置的,用户无需感知,保证了从1.0往2.0迁移时使用体验的一致性。
![]()
另外,我们将DSL和动态图作为关键特性来进行演进。其中DSL提供了自定义算法的能力,动态图则提供了时序分析的能力。
DSL:提供灵活、可控的GraphDSL帮助用户低成本设计并运行算法/查询。特别是复杂查询和定制的计算任务,如,定制化pagerank,repeat query等。过程中无需安装编译,无需更新版本,且兼顾了原有的使用习惯,将Cypher与Gremlin的写法与计算模式结合起来。
![]()
【定制化PageRank样例】
动态图:世界是千变万化的,这些变化的背后蕴含着重要信息(如疫情传播的时序影响、转账关系的先后顺序等),传统图分析主要采用静态的、单一视角的分析方法,仅考虑静态结构,忽略变化,难以辅助更精准的推理决策。动态图分析:考虑时间维度变化,全方位建模和分析动、静态信息影响,辅助精准决策。
![]()
【动态图示意:建模、动态图算法、可视化】
3.3 GES 3.0:拥抱大模型,构建Graph+AI引擎
面向未来,GES 3.0会往Graph+AI引擎方向构建。一方面结合大模型,提升AI方面的能力;另一方面,整合多源数据,更好的融入大数据生态。同步的,易用性、生态兼容(GQL)也是贯穿其中的。
GES 3.0的核心理念:
- Composable: 系统各个部件可组合, 可替换, 实现长期可升级性
- Unified: 针对多种数据类型(Table, Graph)提供查询能力
- AI-Centric: 深度结合大模型, 以AI为中心, 赋能GES
![]()
- 融合大模型,自动化捕捉实体关系来创建知识图谱
- 图查询中支持LLM, GNN和DL的联合推理
- 利用Graph的强大的Multi-Hop的推理能力和对实时性数据/事件的存储能力,帮助纠正LLM的幻觉和实时性问题
点击关注,第一时间了解华为云新鲜技术~