作者:郑增权
爱可生南区数据库工程师,爱可生 DBA 团队成员,负责数据库相关技术支持。爱好:桌球、羽毛球、咖啡、电影。
本文来源:原创投稿
- 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
背景
客户想在业务上线前记录现有 OceanBase 集群的 Parameters、Variables、ProxyCofnig 参数值。然后,将其与“默认值”或“DBA 主动刷的调优参数”进行对比,若是“默认值”或“DBA 主动刷的调优参数”则符合预期,否则认为其是不符合预期的值。最后,生成一份报表文件,标记出非预期的值,再由人工确认其合理性。
客户所用的 OceanBase 版本还没有提供追溯所有参数修改记录的方法,作者提供了利用 Shell 脚本 + Excel VLOOKUP 函数,快速采集 OB 参数,并生成参数存档文件 的方法来实现该需求。 下面将展示该方法的实现步骤。
实现
2.1 准备脚本和模板文件
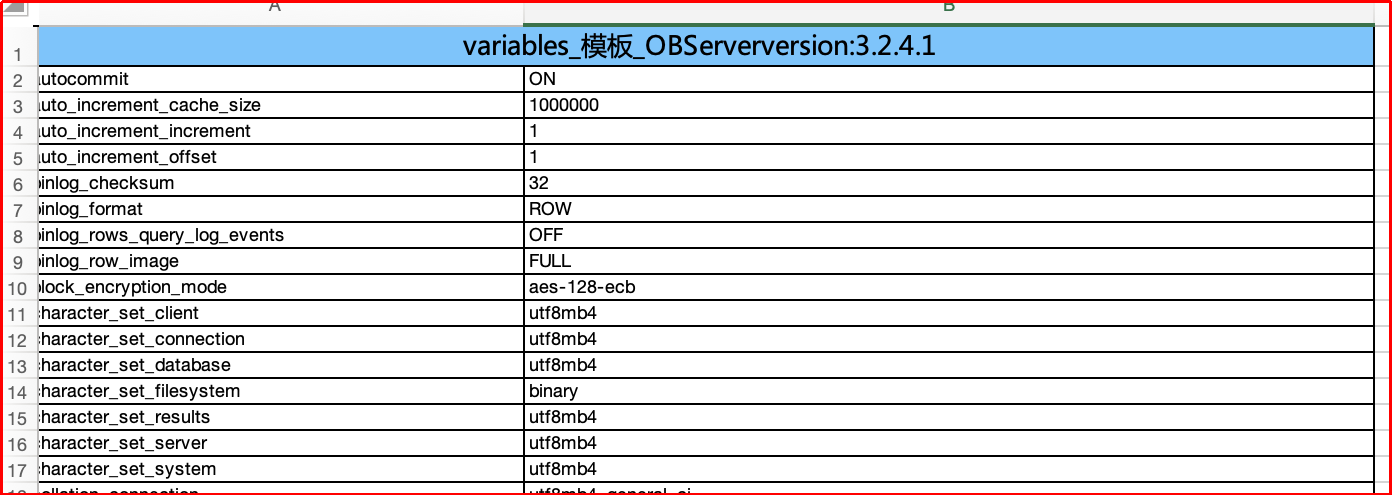
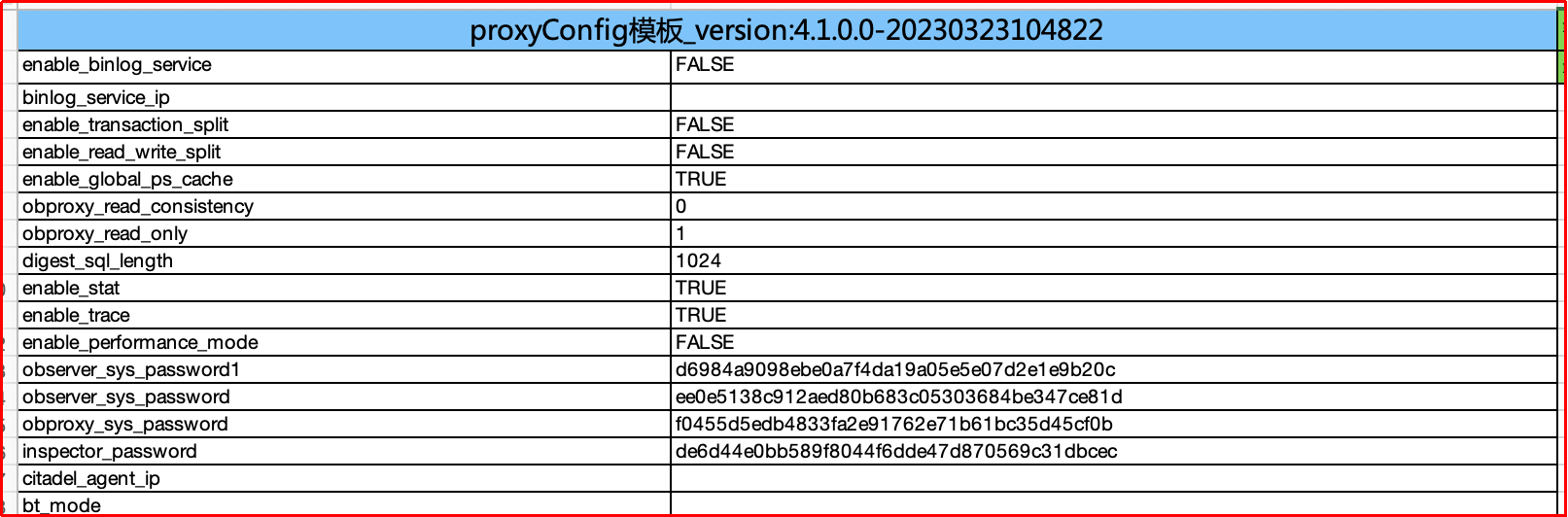
测试环境安装同版本的 OBServer、OBproxy,编写 Shell 脚本用于获取默认的 Parameters、Variables、ProxyCofnig 参数值,并将其提取出来,放至 Excel 作为“默认值模板”。
主备集群模式,主集群和备集群需分别执行脚本获取参数文件:
| 参数 |
级别 |
说明 |
| Parameters |
集群级 |
每个集群获取一份参数 |
| Variables |
租户级 |
每个租户获取一份参数 |
| ProxyConfig |
节点级 |
每个 OBProxy 节点获取一份参数 |
三个脚本在文末呈现并已传至 GIthub。
运行三个脚本,并下载结果文件。
![]()
整理下载的文件,形成三个汇总文件。
![]()
![]()
![]()
![]()
2.2 提取参数
将 DBA 主动刷的参数提取出来,仿照“默认值模板”放至 Excel 作为“刷参数默认值模板”sheet。
2.3 获取对比参数
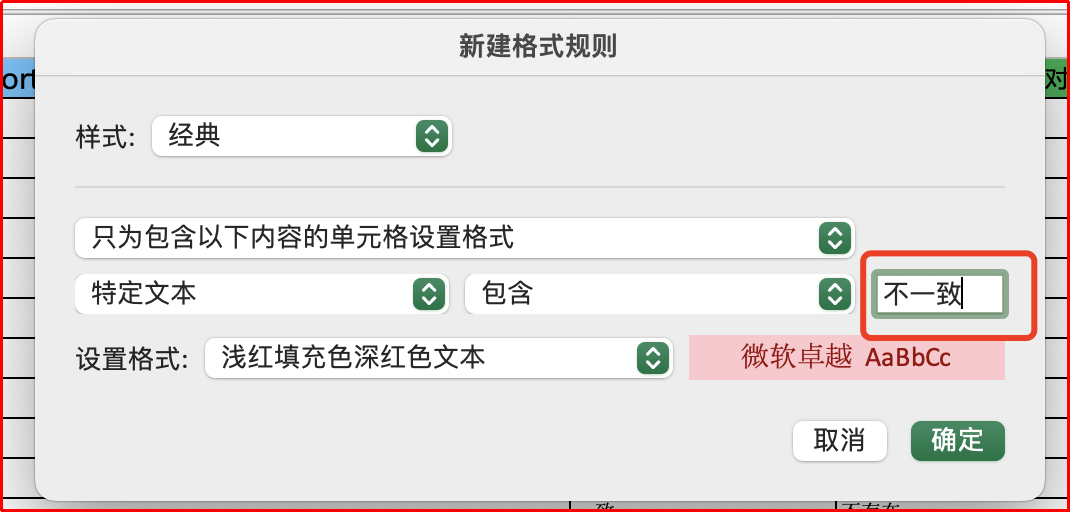
在生产环境运行 Shell 脚本获取参数,将参数放至 Excel,基于 vlookup 进行跨 sheet 对比,将不符合预期的参数值以红色底纹展示。
下面以 Variables 为例进行展示,Parameters 和 ProxyConfig 与其类似。
![]()
=IFERROR(IF(B2=VLOOKUP(A2,variables模板!A:B,2,FALSE),"一致","不一致"),"不存在")
![]()
=IFERROR(IF(B2=VLOOKUP(A2,刷参数默认值模板!A:B,2,FALSE),"一致","不一致"),"不存在")
![]()
![]()
![]()
2.4 人工确认
将不符合预期的参数与客户进行确认,不符合要求的需择期整改。
总结
- OceanBase 当前版本尚未提供追溯所有参数修改记录的方法,本文为记录参数修改记录提供一种思路。
- 基于本文方法进行参数对比,在参数有更新时需在 Excel 中同步更新。
- 当项目上线后,若有参数被违规修改,基于此存档文件可进行追溯对比。 更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
爱可生开源社区的 SQLE 是一款面向数据库使用者和管理者,支持多场景审核,支持标准化上线流程,原生支持 MySQL 审核且数据库类型可扩展的 SQL 审核工具。
SQLE 获取