应用简览
Memos 是一个开源的轻量级笔记服务应用,它为用户提供了一个随时记录思绪和想法的私密空间,同时它支持私有化部署,这意味你可以完全掌控你的数据和隐私,同时它还提供了直观的分享功能,让你可以轻松地与他人协作和分享笔记。
主要特性
-
开源且永久免费:Memos 是一款开源的应用,永久免费使用。它鼓励创造力,让您的想法得以充分发挥,不受任何限制。
-
自托管部署:使用 Docker,可以在几秒钟内设置好 Memos,获得数据和隐私的完全控制权,提供了极大的灵活性和可扩展性。
-
纯文本与 Markdown 支持:Memos 坚持采用纯文本格式,摒弃了繁琐的富文本编辑,同时支持 Markdown,让您以极简主义的方式记录和分享笔记。
-
自定义与轻松分享:Memos 提供直观的自定义和分享功能,使你能够轻松地与他人合作和分享笔记,促进信息交流。
-
RESTful API支持:Memos 还提供了强大的 RESTful API,让您能够与第三方服务进行集成,开启全新的应用可能性。
应用特色
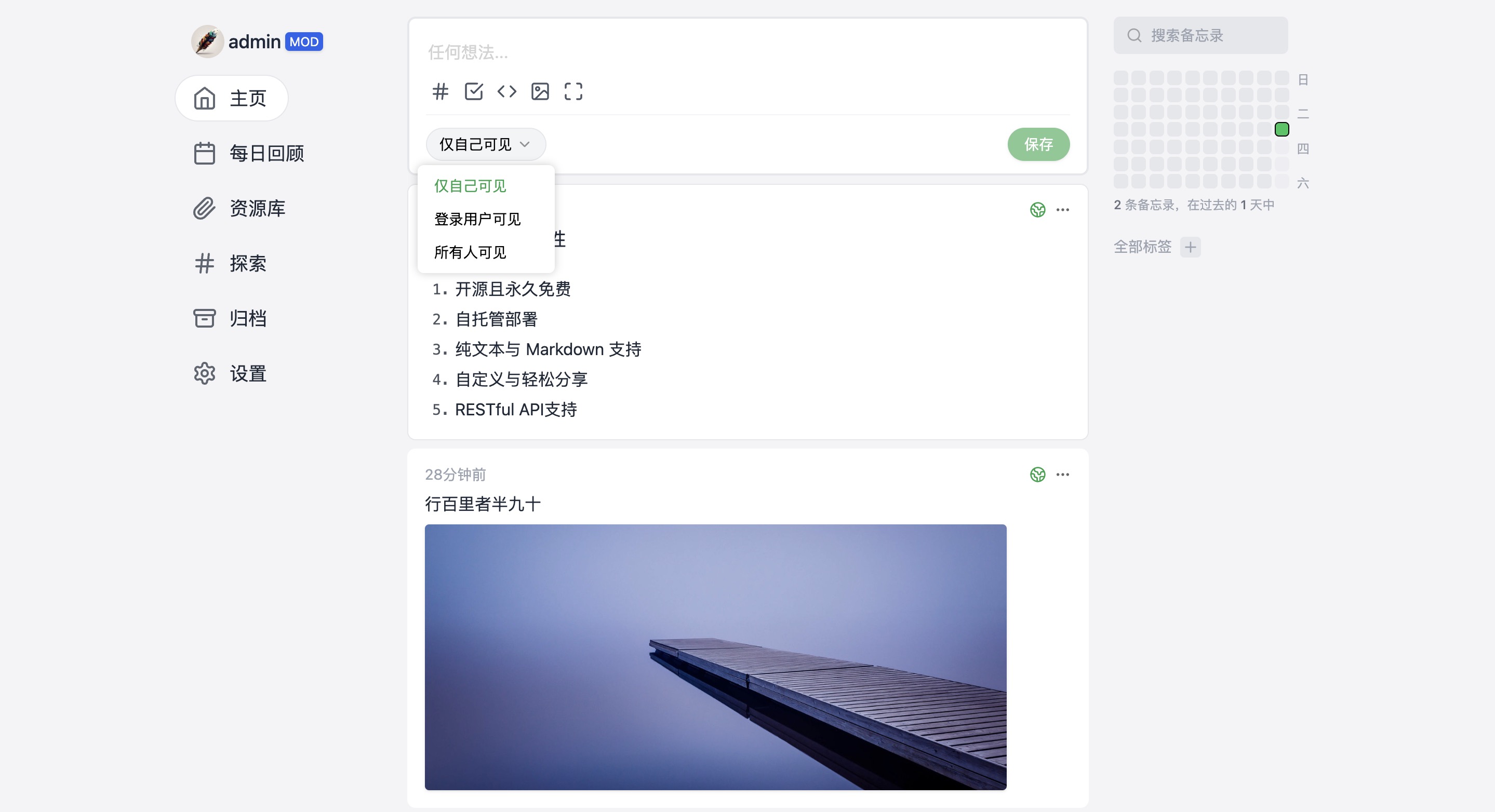
一、支持多用户,且允许设置可见范围
Memos 提供了多用户支持,这意味着可以与团队成员或朋友共享笔记,并轻松地管理多个用户帐户。而且,Memos 允许设置笔记可见范围,确保您的笔记只对登录用户、自己或全部可见。这一功能极大地增强了协作和隐私保护的灵活性。
![]()
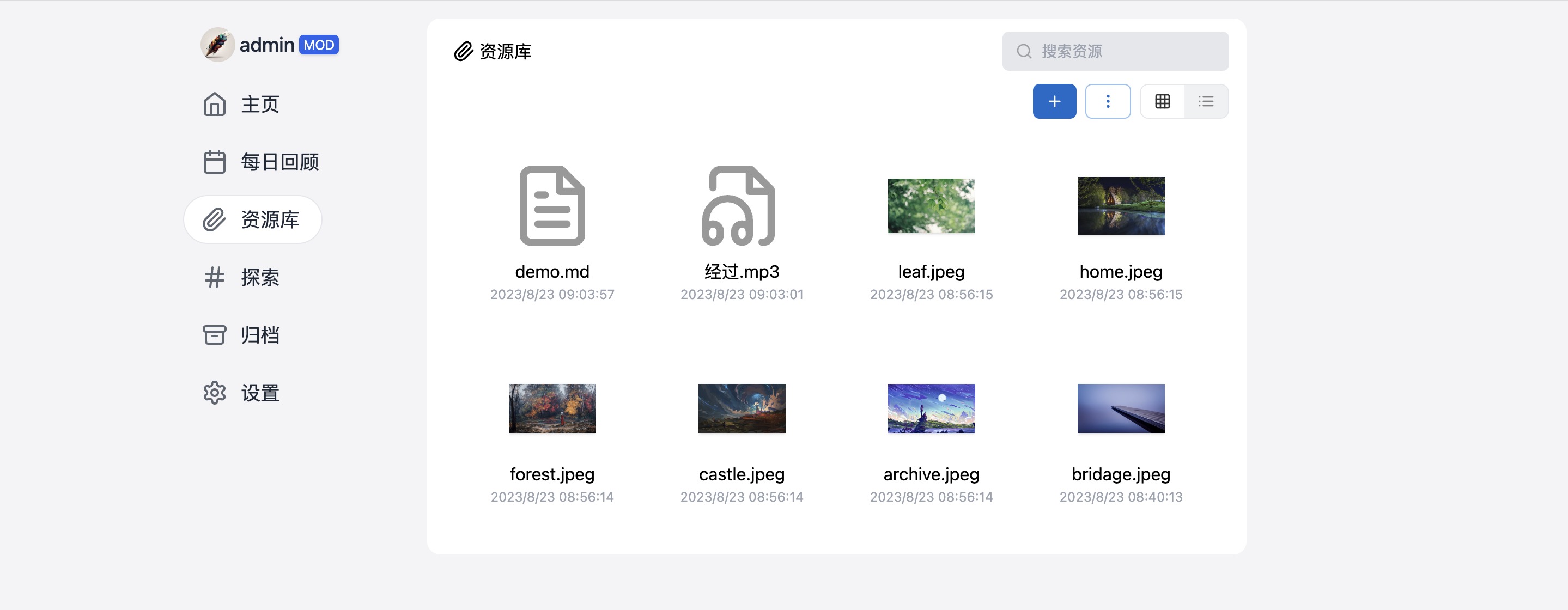
二、支持资源库的形式存储各类文件
除了纯文本笔记,Memos 还支持资源库的形式存储各类文件。这意味着您不仅可以记录文字内容,还可以轻松地上传、存储和共享图片、音频、文档等多种文件类型。无论是项目资料、创意灵感还是照片集,Memos 都能满足你的多样化需求。
![]()
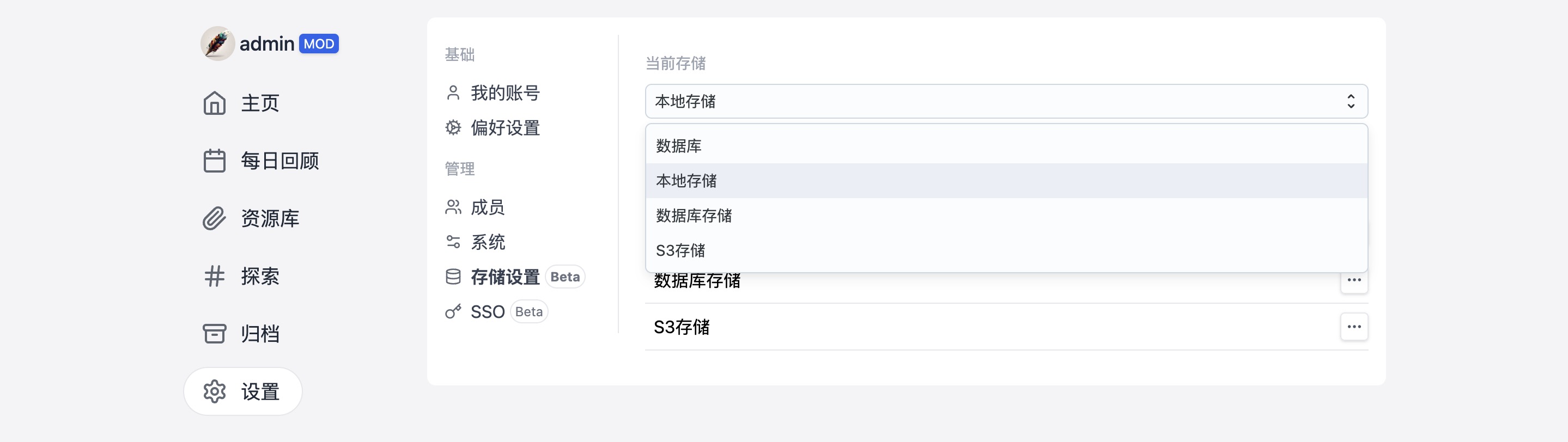
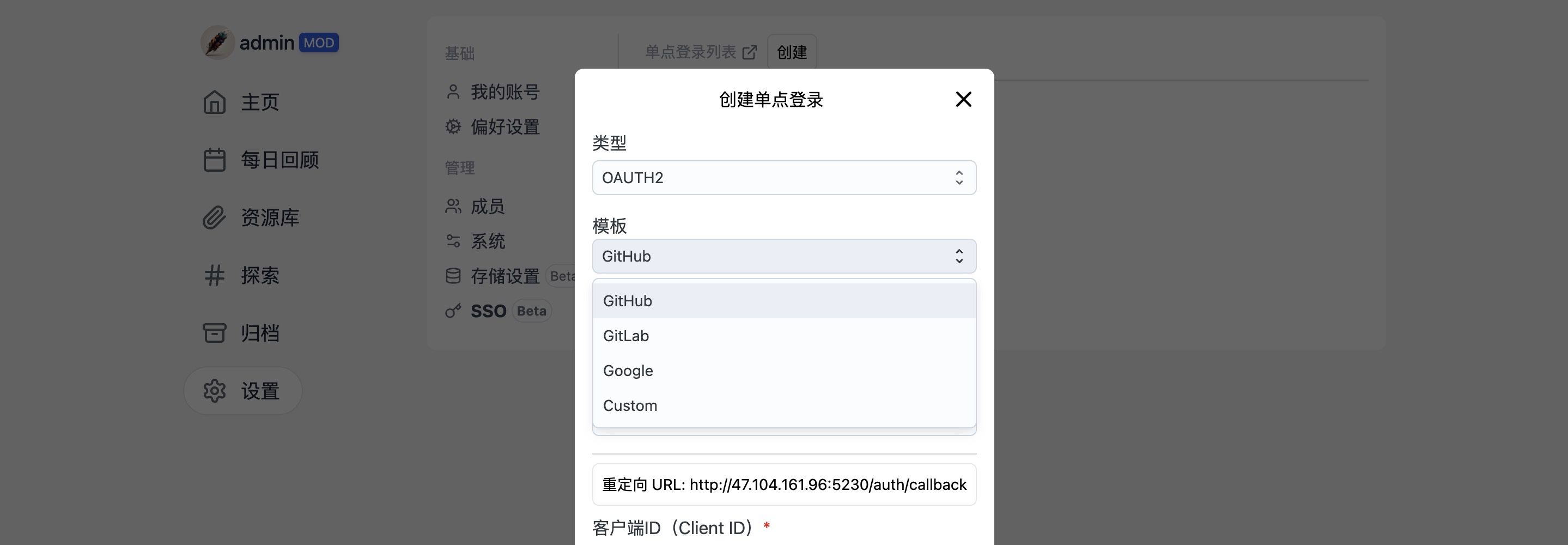
三、支持多种存储,以及多种类型的单点登录
Memos 提供多样化的后端存储选项,包括数据库、S3 和本地存储,确保您能够根据需求选择最适合的存储方式,为您的数据提供灵活性和可扩展性。此外,Memos 还支持多种类型的单点登录,如 Github、Gitlab、Google 等,同时还允许您自定义其他认证方式,为用户提供了便捷的登录和身份验证方式,从而平衡了安全性和便利性的需求。
![]()
![]()
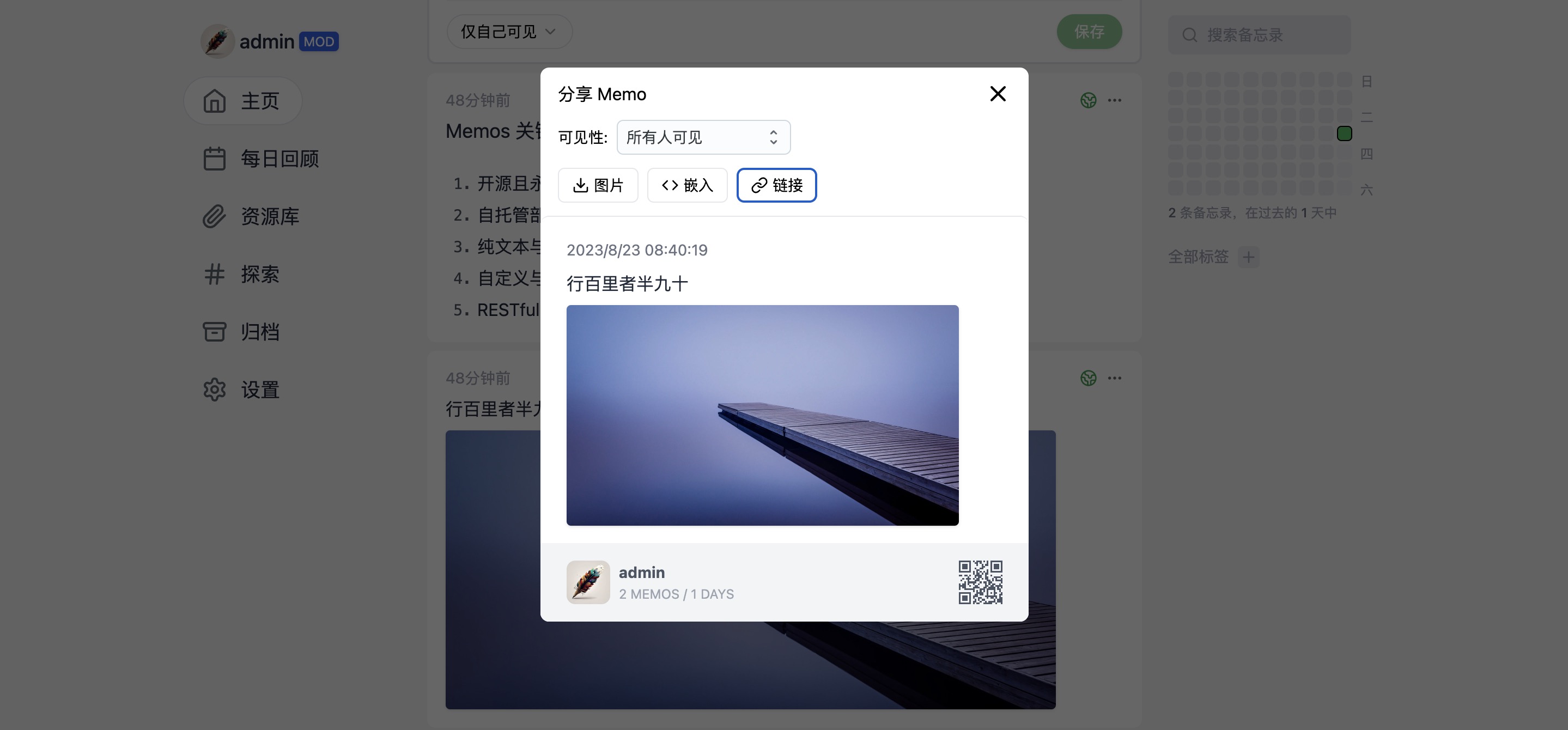
四、支持图片、链接、嵌入式代码等方式分享笔记
Memos 提供了多种富有创意的笔记分享方式,包括图片、链接以及嵌入式代码等。这意味着您可以以更生动和多样的方式分享您的笔记内容。无论是展示精美图片、分享有用链接,还是嵌入代码示例以便他人参考,Memos 都为分享增添了更多的生动性和趣味性。
![]()
安装指南
- 进入云原生应用商店
- 搜索 Memos
- 进入详情,选择包类型(本应用支持,docker安装,ram安装)
- 点击安装,执行相应命令即可。如有疑问可参阅使用文档或加入社区
关于云原生应用市场
云原生应用市场是一个汇聚了各类开源软件的应用市场,不仅可以作为你自己的 Helm Chart 仓库,提供丰富多样的Helm应用,还有 Docker 应用、Rainbond 应用模板、信创应用等多种选择。
官网:https://hub.grapps.cn/
微信群:关注 云原生应用市场 公众号加入技术交流群