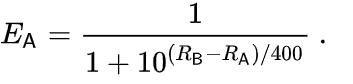LMSYS ORG (Large Model Systems Organization) 最新推出了一个大语言模型 (LLM) 基准平台 Chatbot Arena,旨在对目前市场上的大语言模型进行基准测试。具体表现为,通过在大语言模型间进行随机匿名的 1V1 battle 方式,并基于 Elo 评级系统得出排名。
LMSYS ORG 是一个开放的研究组织,由加州大学伯克利分校的学生和教师与加州大学圣地亚哥分校和卡内基梅隆大学合作创立。Elo 评分系统统是指由匈牙利裔美国物理学家 Arpad Elo 创建的一个衡量各类对弈活动水平的评价方法,是当今对弈水平评估的公认的权威方法。被广泛用于国际象棋、围棋、足球、篮球、电子竞技等运动;Elo 评分越高,越厉害。
具体来说,如果玩家 A 的评分为 Ra,玩家 B 的评分为 Rb,则玩家 A 获胜概率的确切公式(使用以 10 为底的 logistic 曲线)为:
![]()
玩家的评分可以在每场战斗后线性更新。假设玩家 A(评分为 Ra)预计得 分Ea,但实际得分为Sa。更新该玩家评分的公式为:
![]()
LMSYS ORG 团队首先选择了当下比较出名的 9 个开源聊天机器人进行了评估。在 1v1 对战过程中,用户可以与两个匿名模型并排聊天。在得到两个模型的响应后,用户可以继续聊天或投票给他们认为更好的模型。提交投票后将显示模型名称,用户可以选择与两个随机选择的新匿名模型继续聊天,或重新开始新的 PK。该平台会记录所有的用户交互,但团队在分析时只会采用隐藏模型名称时的投票结果。
![]()
而在此比拼开始之前,团队已经先根据基准测试的结果掌握了各个模型可能的排名;并选择根据这个排名来配对模型,优先选择更匹配的对手。然后再改用均匀采样,以获得更好的整体排名覆盖。在赛程接近尾声时,团队还引入了一种新模型 fastchat-t5-3b。以上所有的操作最终导致了非均匀的模型频率。
![]()
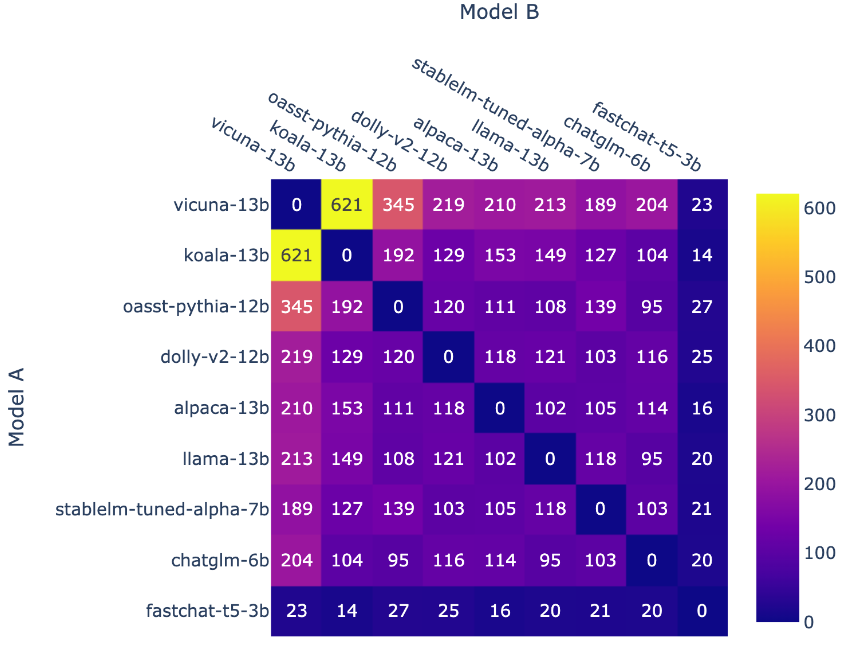
🔼 每个模型组合的对战次数
![]()
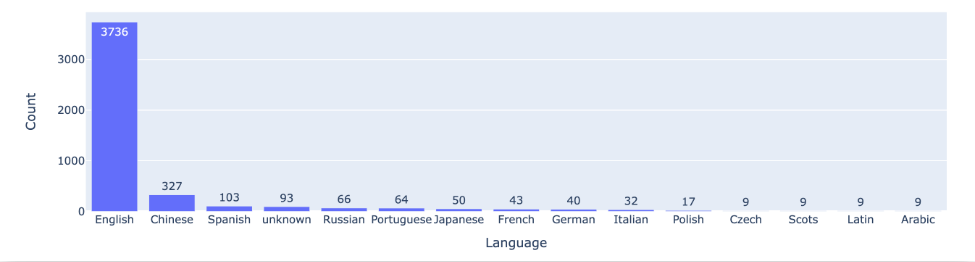
🔼 前 15 种语言的对战次数
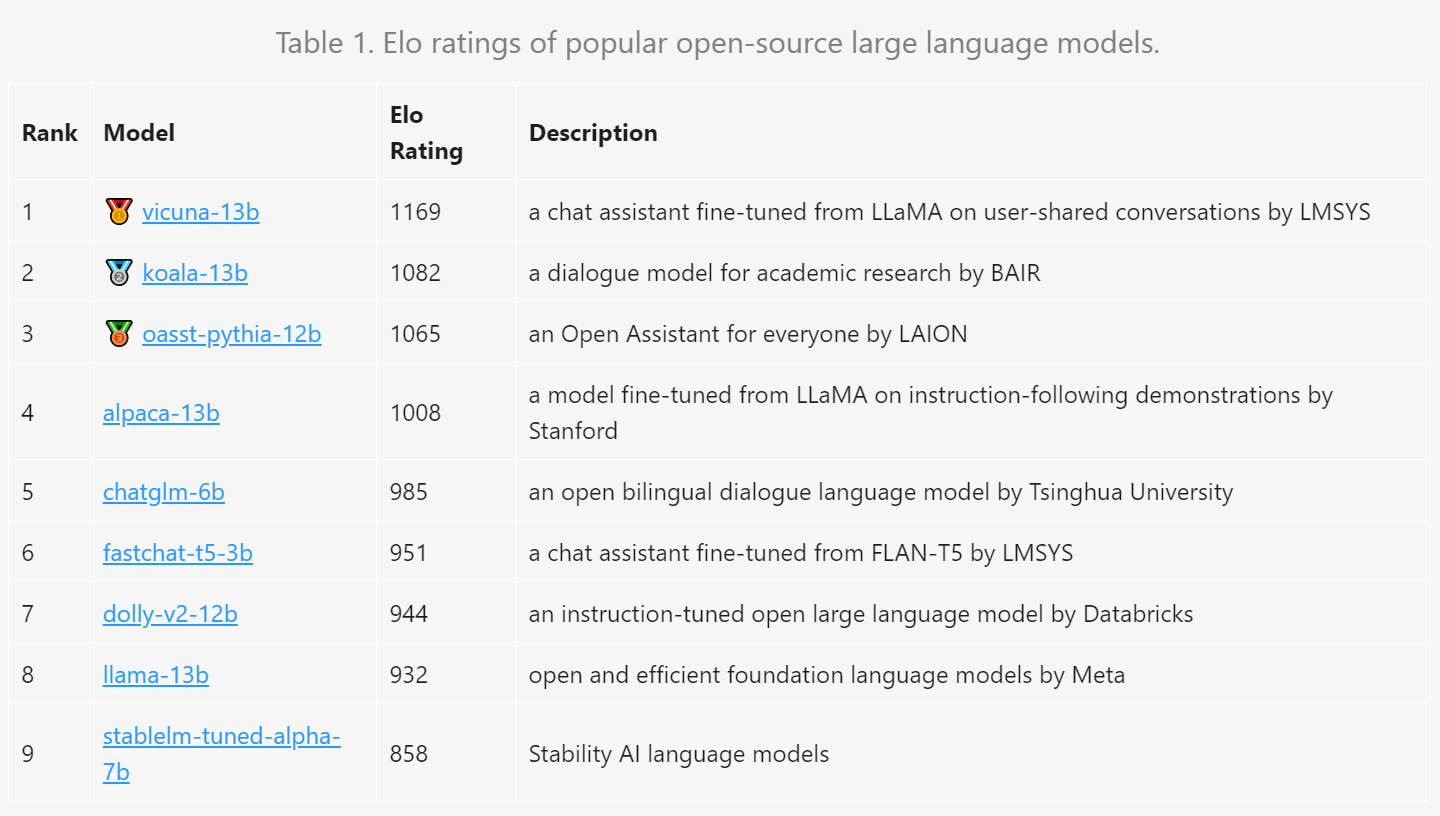
在经过一周左右时间的数据收集后,团队基于 4.7K 的有效匿名投票数据和计算结果得出了具体评分结果。
![]()
结果表明,130 亿参数的 Vicuna 以 1169 分夺得榜首。其次分别是同样 130 亿参数的 Koala、以及 LAION 的 Open Assistant;清华大学开源的中英双语对话模型 ChatGLM-6B 以 985 的 Elo 得分排名第 5。而 Meta 的 LLaMa 则排在了倒数第二,Stability AI 的 StableLM 以 858 分排名倒数第一。
更多详细信息可查看官方公布的数据。
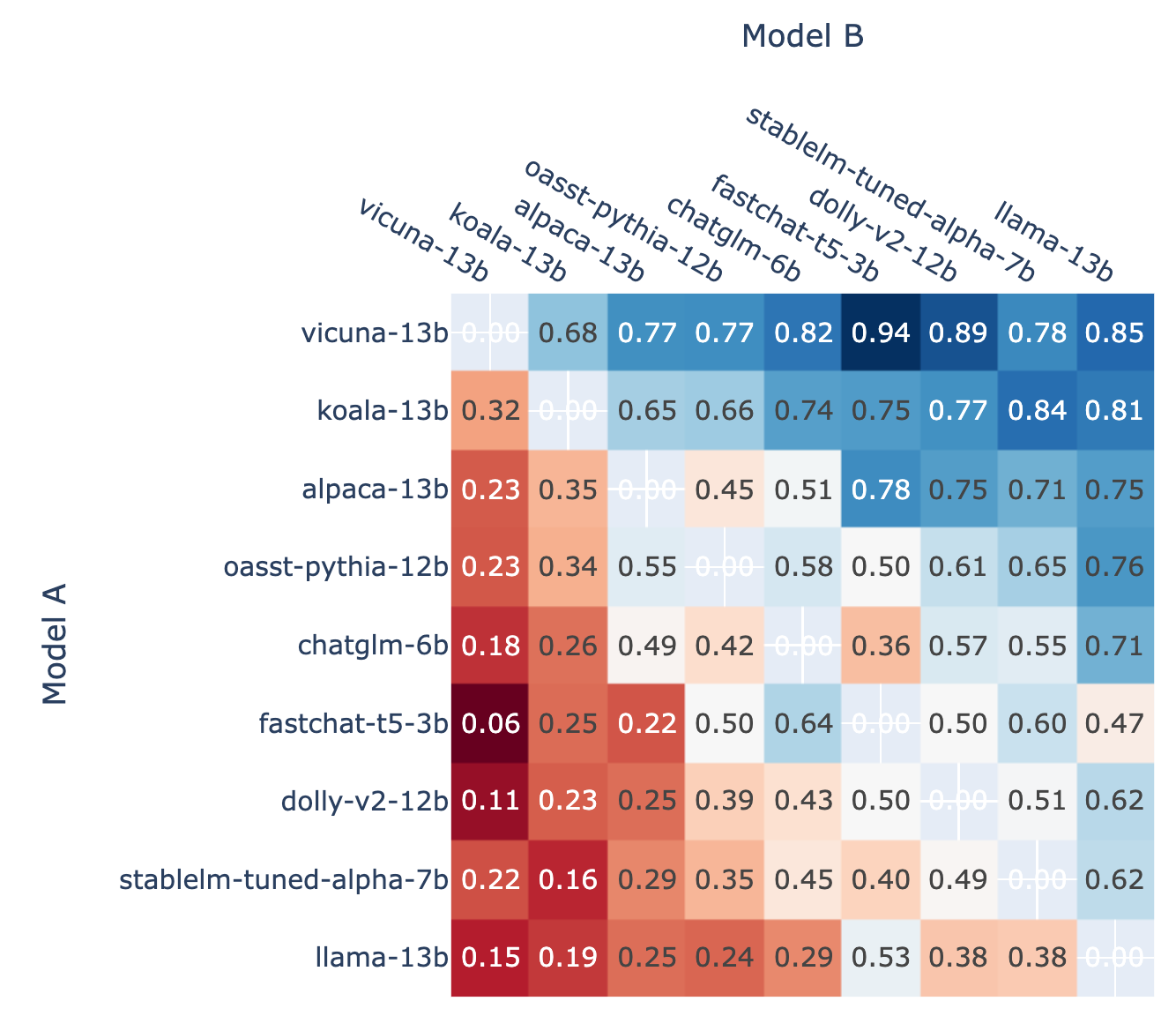
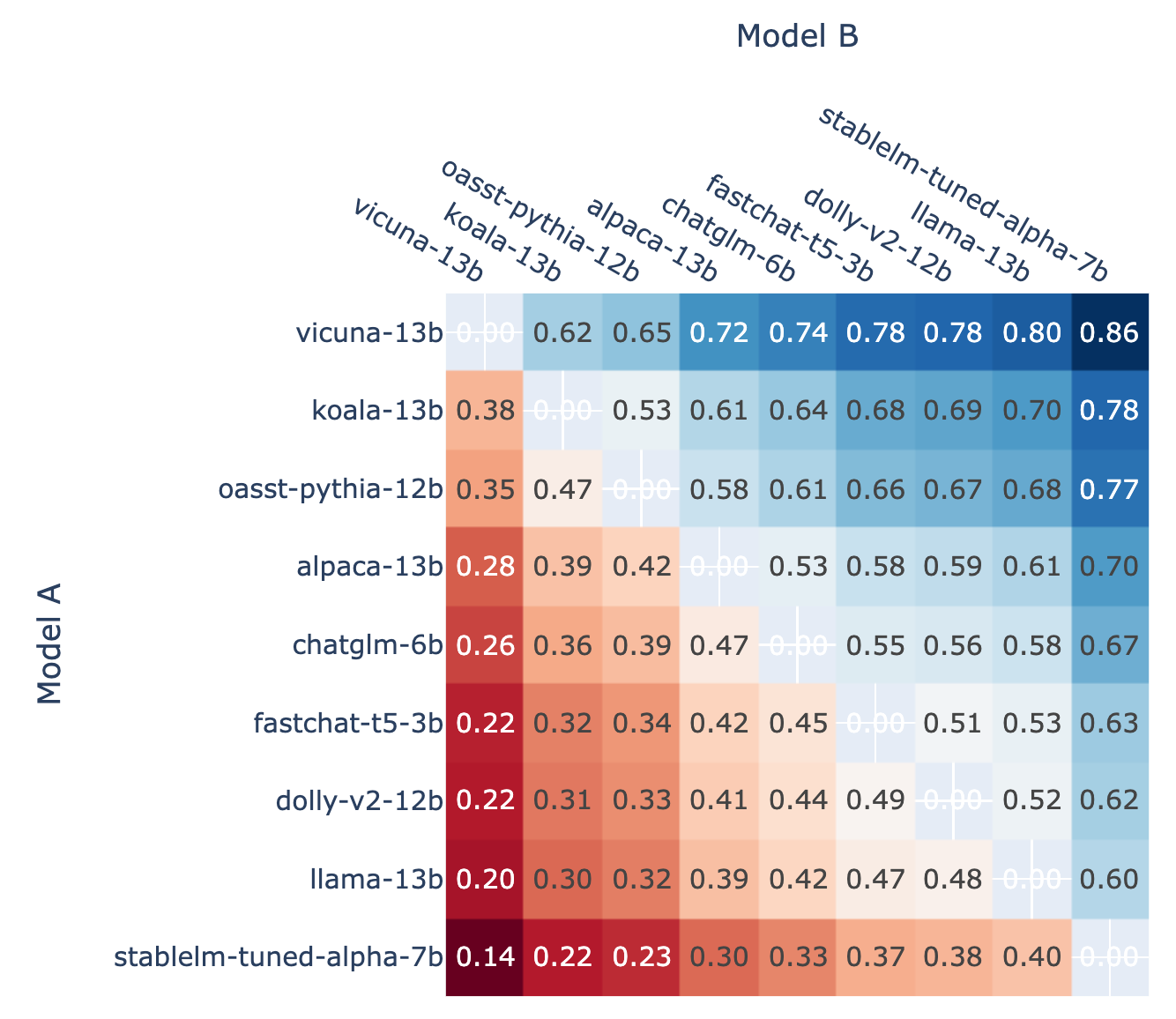
此外,作为校准的基础,LMSYS ORG 还展示了对战中每个模型的对战获胜率以及使用 Elo 评分估算的预测对战胜率。通过比较数据,他们认为 Elo 评分确实可以相对较好地预测胜率。
![]()
🔼 模型 A 在所有非平局 A 与 B 战斗中获胜的比例
![]()
🔼 在 A 对 B 战斗中,使用 Elo 评分预测的模型 A 的胜率
展望未来,LMSYS ORG 计划在该匿名竞技场内添加更多的开源/闭源模型(ChatGPT-3.5 现已可用);发布定期更新的排行榜;优化采样算法、锦标赛机制和服务系统以支持更多模型;以及根据不同的任务类型提供更加细化的排名。
延伸阅读: