作者:京东科技 孙凯
一、前言
对前端开发者来说,Vite 应该不算陌生了,它是一款基于 nobundle 和 bundleless 思想诞生的前端开发与构建工具,官网对它的概括和期待只有一句话:“下一代的前端工具链”。
Vite 最早的版本由尤雨溪发布于3年前,经历了3年多的发展,Vite 也已逐渐迭代成熟,它的稳定性、扩展性、周边生态足以在生产环境中支撑各种业务场景的落地。但是关于Vite的优劣势分析我们就戛然而止,不在深入展开了,这不是本文的重点。
本文的重点在于探究 Vite 如何实现兼容低版本浏览器,这一切还得从那个阳光明媚的午后说起🤔。
二、那个午后
本着尝鲜的态度,我在某一个项目中用了 Vite,当时还是3.x.x的版本,跟着文档配置,从项目启动到项目构建,一路都很“德芙”(纵享丝滑),在经历了 Vite 带来的短暂新鲜感后,就一直沉浸在业务模块的开发中了,因为在 Vite 刚发布后的那段时间曾看过相关原理解析,是基于浏览器原生的模块化能力按需构建BALABALA等,所以后来 Vite 的这种新鲜感对我而言并没有保持多久。
但直到有天下午我开始打包提测,审查页面元素后发现构建产物居然跟以往 webpack 的产物竟然有点不一样,在好奇心的驱使下,于是我开始尝试解谜。
三、跟webpack构建产物到底哪里不一样?
1. 准备工作
为了能更好的对比两者产物究竟有什么区别,我们首先要确保我们的业务代码基本一致,不一致的地方仅仅是使用不同工具( vite 和 webpack)进行构建,这样才能排除最大干扰因素。
于是我们分别使用最新版的 Vite 和 webpack 初始化了两个页面,为了做作区分,两个页面的仅标题和标题背景不一致,他们在浏览器中渲染后的分别长这个样子:
2. 构建工具版本说明
• Vite:v4.1.4
• webpack:v5.75.0
3. 构建工具配置项说明
• Vite (非常简单,啥也没有)
// vite.config.js
import { defineConfig } from 'vite'
import legacy from '@vitejs/plugin-legacy'
import vue from '@vitejs/plugin-vue'
export default defineConfig({
plugins: [
vue(),
legacy({
targets: ['ios >= 9', 'android >= 4.2', '> 1%']
})
],
server: {
host: '127.0.0.1'
},
build: {
minify: false
}
})
• webpack(太多了,也比较常规,就不在这里贴出来全部配置项了,仅在这里配置好跟 Vite 一样的需要兼容到最低的浏览器版本)
// .browserslistrc
ios >= 9
android >= 4.2
> 1%
至此,准备工作完毕,让我们看看两者的构建产物吧。
4. 构建产物
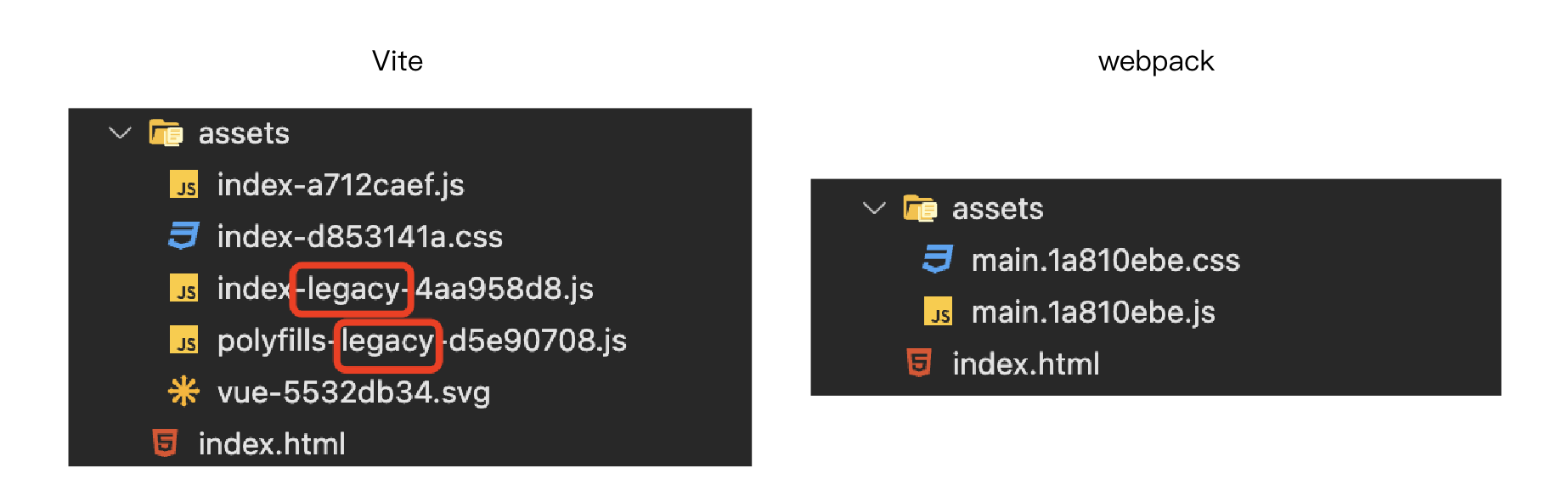
从产物的命名中,我们就能多少看出些许区别,webpack的产物比较简单,中规中矩,而 Vite 的 JS 文件不但比 webpack 多,而且部分文件命名中还多了一个单词:legacy,百度翻译对它的解释是:遗产;遗赠财物;遗留;后遗症;(计算机系统或产品)已停产的,通过翻译,或许你可以猜出来,名字中带 legacy 的文件大概率就是浏览器的兼容文件,那么事实到底是不是这样呢?
如果你足够细心,其实你应该可以从上面 Vite 的配置项代码中嗅到一丝端倪,在 Vite 的配置文件中,有一个名为 @vitejs/plugin-legacy 的插件,它的名字也包含 legacy,Vite 官网中对这个插件的解释是这样的:
“传统浏览器可以通过插件 @vitejs/plugin-legacy 来支持,它将自动生成传统版本的 chunk 及与其相对应 ES 语言特性方面的 polyfill。兼容版的 chunk 只会在不支持原生 ESM 的浏览器中进行按需加载。”
也就是说,这个插件它不但提供了低版本浏览器的兼容能力,还提供了检测是否支持原生 ESM 的能力。那么这个插件都做了哪些事?
主要是以下三点:
1. 为最每个生成的 ESM 模块化方式的 chunk 也对应生成一个 legacy chunk,同时使用 @babel/preset-env 转换(没错,Vite 的内部集成了 Babel),生成一个 SystemJS 模块,关于 SystemJS 可以看点击这里查看,它在浏览器中实现了模块化,用来加载有依赖关系的各个 chunk。
2. 生成 polyfill 包,包含 SystemJS 的运行时,同时包含由要兼容的目标浏览器版本和代码中的高级语法产生的 polyfill。
3. 生成 <script nomodule> 标签,并注入到 HTML 文件中,用来在不兼容 ESM 的老旧浏览器中加载 polyfill 和 legacy chunk。
如此可见,Vite 兼容低版本浏览器的能力就是来自于 @babel/preset-env 无疑了,都是生成 polyfill 和语法转换, 但是这不就和 webpack 一样了么,事实是 Vite 又帮我们多做了一层,那就是上面反复提到的原生浏览器模块化能力 ESM。
5. Vite 的原生模块化能力
我们看看 Vite 打包后HTML中的内容,内容较多,我分开讲,先看 head 标签中的内容
<head>
<script type="module" crossorigin src="/assets/index-a712caef.js"></script>
<link rel="stylesheet" href="/assets/index-d853141a.css" />
<script type="module">
import.meta.url;
import("_").catch(() => 1);
async function* g() { }
window.__vite_is_modern_browser = true;
</script>
<script type="module">
!(function () {
if (window.__vite_is_modern_browser) return;
console.warn(
"vite: loading legacy chunks, syntax error above and the same error below should be ignored"
);
var e = document.getElementById("vite-legacy-polyfill"),
n = document.createElement("script");
(n.src = e.src),
(n.onload = function () {
System.import(
document
.getElementById("vite-legacy-entry")
.getAttribute("data-src")
);
}),
document.body.appendChild(n);
})();
</script>
</head>
代码的前两行加载了入口 JS (index-a712caef.js,记住这个文件名,后面会用到)和 CSS,JS资源使用了 ESM 的模块化方式加载,等等,嗯?JS 居然使用了 ESM ?如果当前浏览器不兼容 ESM,那这段 JS岂不是永远不会执行?
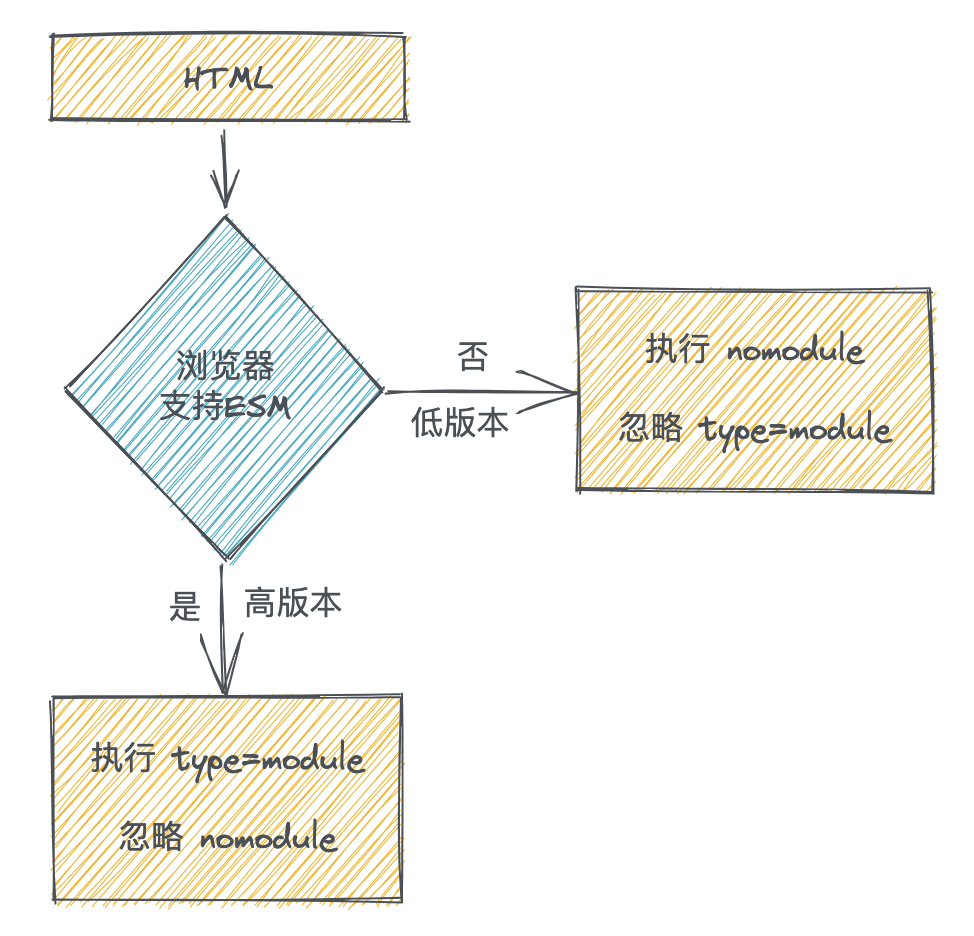
其实这就是 ESM 模块化的能力之一,对于携带 type="module" 这个属性的 script 标签,不支持 ESM 的浏览器不会执行内部代码,所以报错也就不存在了,与之对应的 script 上还有 nomodule 这个属性,支持ESM的浏览器会忽略携带这个属性的 script,可以防止某些兼容逻辑在高版本浏览器执行,这两个属性组合使用就是为了决定浏览器在面对未知版本浏览器时的代码执行策略,我们画个简易流程图理解一下:
继续往下看。
接下来的两段内联 script 标签中的内容很关键,我们先看第一段代码,这段代码暂且命名为代码A:
<script type="module">
import.meta.url;
import("_").catch(() => 1);
async function* g() { }
window.__vite_is_modern_browser = true;
</script>
期初我看上面这段代码的时候,我就想:这写的都是些个什么东西!前三行都是高级ES语法,部分浏览器根本不兼容好嘛,这都能写上去,真不怕报错和白屏?
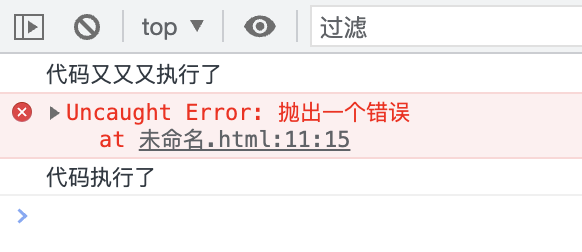
其实要注意 script 标签上 type="module" 这个属性,ESM模块化的好处之一就是,它在处理报错信息的时候,不像普通 script 一样会把错误抛到模块外部,内部出错也不会阻塞后续逻辑的执行和页面渲染,接下来我们验证一下这个观点,直接上代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>title</title>
</head>
<body>
<script type="module">
throw new Error('抛出一个错误')
console.log('这段代码执行了没')
</script>
<script type="module">
console.log('代码执行了')
</script>
<script>
console.log('代码又又又执行了')
</script>
</body>
</html>
执行结果如下:
先不管代码结果的输出顺序,我们在这只看输出结果,与上述结论一致的,即错误影响了内部模块,并中断了后续的代码逻辑,而外部不受影响。
在 Vite 生成的 HTML 中这样做的好处就是为了检测浏览器对相关语法的支持程度,如果模块中的语法不支持,就会停止执行;如果支持,那么同时打上一个标记,也就是上述示例代码A的倒数第二行——通过在 window 上设置全局变量(因为ESM模块中的变量影响不到外部)window.__vite_is_modern_browser = true,来标识当前浏览器是否为一个“现代浏览器”,是否支持的某些语法特性(import.meta、动态导入、异步生成器),这样可以使 Vite 后续更准确的判断该加载那些 JS。
于是接下来我们就看到了下面这段代码:
<script type="module">
!(function () {
if (window.__vite_is_modern_browser) return;
console.warn(
"vite: loading legacy chunks, syntax error above and the same error below should be ignored"
);
var e = document.getElementById("vite-legacy-polyfill"),
n = document.createElement("script");
(n.src = e.src),
(n.onload = function () {
System.import(
document
.getElementById("vite-legacy-entry")
.getAttribute("data-src")
);
}),
document.body.appendChild(n);
})();
</script>
它内部判断了 window.__vite_is_modern_browser 这个全局标识是否存在,如果存在,说明上一个模块中的代码执行没有问题,直接退出;如果不存在,说明当前浏览器不是一个“现代浏览器”,那就该加载和执行兼容文件了,于是可以看到这段代码的后半段,Vite 使用 SystemJs 加载了带有 legacy 标记的文件。
到了这里还没有结束, 虽然 Vite 在个别情况下加载了兼容文件,但如果你仔细看上述代码,会发现整个加载逻辑是放在拥有 type="module" 这个属性的 script 中的,在前面已经阐述过了, type="module" 在低版本浏览器是不会执行的,换句话说就是,低版本浏览器的兼容文件并不会被加载。于是 Vite 为了低版本浏览器能正常执行业务逻辑,又做了如下操作——
以下代码来自 VIte 打包后 body 标签中的内容:
<script nomodule crossorigin id="vite-legacy-polyfill" src="/assets/polyfills-legacy-d5e90708.js"></script>
<script nomodule crossorigin id="vite-legacy-entry" data-src="/assets/index-legacy-4aa958d8.js">
System.import(
document.getElementById("vite-legacy-entry").getAttribute("data-src")
);
</script>
可以看到,在低版本浏览器中 Vite 使用了带有 nomodule 属性的 script 标签,先加载了 polyfills 文件,确保后续代码中使用的API能正确执行,再通过 SystemJs 加载入口文件执行后续逻辑,至此, Vite 兼容旧版本浏览器的逻辑算是基本讲述完毕了。
6. “魔鬼藏在细节中”
纵观Vite的整个加载流程,粗一看没有什么大问题,但是经不起推敲,我们再来捋一捋,看看还发生了什么。
第一步,Vite 在页面最开始加载了 CSS 和 JS,加载 JS 的方式是使用 ESM
第二步,Vite 判断了现代浏览器的兼容性,如果是现代浏览器,则不执行 nomodule 中的代码,也不会使用 SystemJs 加载 legacy 文件,反之亦然。
第三部,Vite 对低版本浏览器使用 nomodule 的 script 标签,加载和执行 legacy 文件。
等等,你有没有发现,第一步和第二步有些问题?
我们前面已经说过了,在第二步中,Vite 根据 window.__vite_is_modern_browser 处理了是否加载 legacy 文件的逻辑,但是这里的代码是包裹在 type="module" 这个属性的 script 中的!问题就出现在这里!
我们想象一个场景:总有那么一部分浏览器支持 ESM 的同时,又不支持 import.meta.url; import("_").catch(() => 1); async function* g() { } 这三种语法之一,这是必然的,因为语法诞生的时间不一致。
这也就导致了一个 Vite 的行为:在支持 ESM、同时不支持高级上述三种语法任意一种的时候,window.__vite_is_modern_browser 为 false,Vite 通过 SystemJs 加载了 legacy 文件,但也因为当前浏览器支持 ESM,致使 Vite 在第一步中通过 ESM 加载的 JS 是重复加载!
也就是说,Vite 在这种情况下同时加载了原生模块化的文件和兼容文件!
但更值得思考的还在后面:不管是原生模块化的文件,还是兼容文件,他们对页面的处理逻辑是一致的,因为文件的同时加载,这会不会导致页面执行两次相同的逻辑?
答案是:不会。
Vite 是知道这种情况的,并且已经处理过了,它处理的手段你肯定会觉得很眼熟,就在整个 ESM 文件入口的前几行(也就是本文构建产物中的 index-a712caef.js )——
function __vite_legacy_guard() {
import.meta.url;
import("_").catch(() => 1);
async function* g() {};
};
(function polyfill() {
// 后续其他逻辑不在这里贴了,可以使用 Vite 自行打包查看
...
})();
...
它声明了一个函数,函数内部包含了高版本的语法,Vite 充分利用了 JS 语法边解析边执行的特性:如果当前环境不支持高版本语法,那就在语法解析阶段报错就好了,直接暴力阻止后续逻辑的执行,因为使用了原生模块化的能力,反正错误也不会抛给外面,对页面没有什么影响!
怎么样,这才是完整的 Vite 兼容方案,不得不说,真是有很多细节值得学习和思考。
对于重复加载 ESM 文件, @vitejs/plugin-legacy 是承认缺点存在的,这个插件在 README 中原文是这样解释的:
The legacy plugin offers a way to use widely-available features natively in the modern build, while falling back to the legacy build in browsers with native ESM but without those features supported (e.g. Legacy Edge). This feature works by injecting a runtime check and loading the legacy bundle with SystemJs runtime if needed. There are the following drawbacks:
Modern bundle is downloaded in all ESM browsers
Modern bundle throws SyntaxError in browsers without those features support
The following syntax are considered as widely-available:
dynamic import
import.meta
async generator
大概意思就是:它认为主流浏览器对这三种语法是广泛认可的,换句话也就是说,Vite 的目标其实还是绝大部分现代浏览器,太过低端的已经不考虑了。。。
最后放出 @vitejs/plugin-legacy 的 README 地址: https://github.com/vitejs/vite/tree/main/packages/plugin-legacy#readme
四、总结
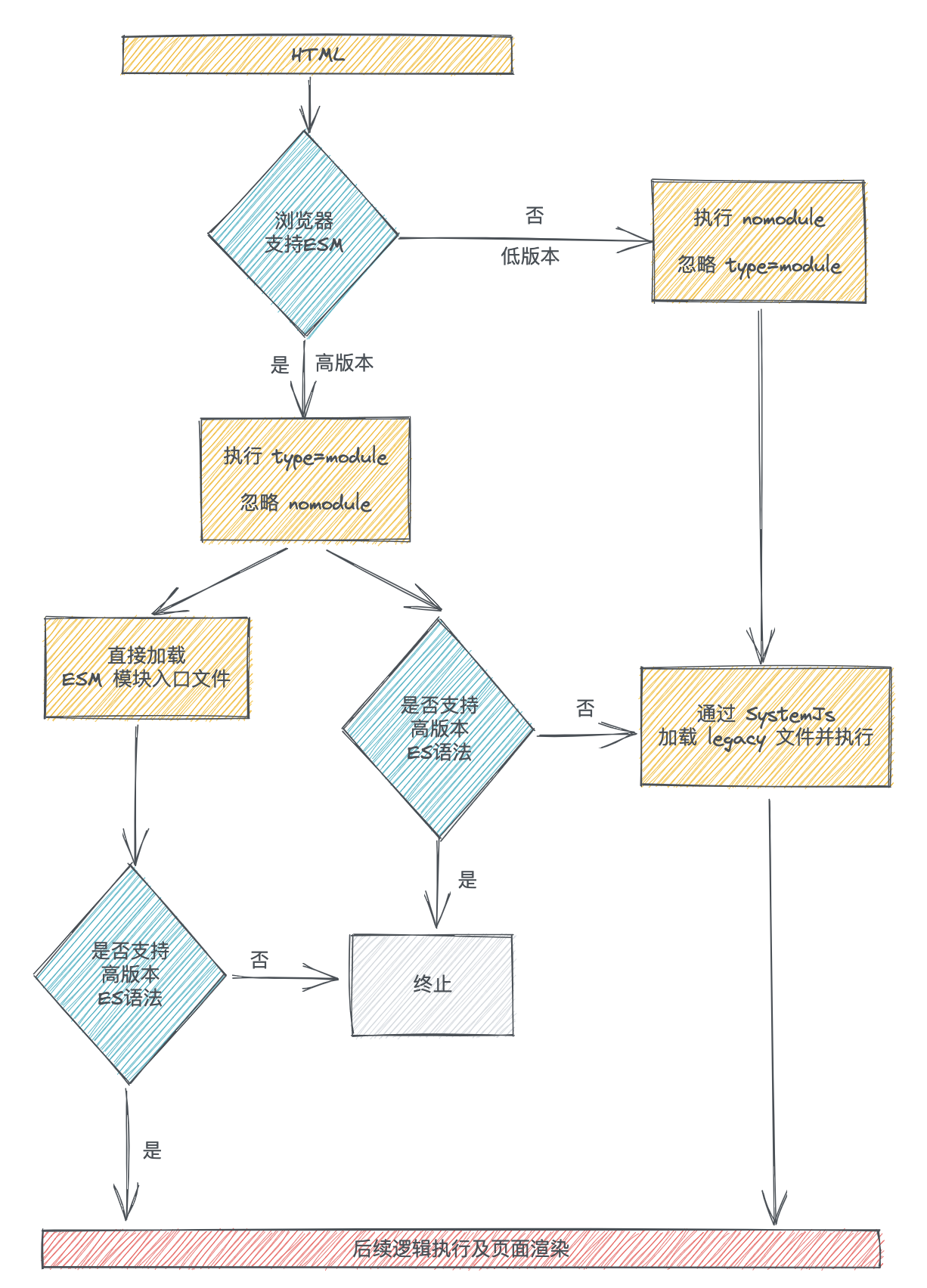
不啰嗦,直接上加载过程完整的流程图,一百句话也不如一张图直观。
最后,实名感谢各位小伙伴的观看,如果能点个赞就更好了 🙌。