日常生产中 HDFS 上小文件产生是一个很正常的事情,同时小文件也是 Hadoop 集群运维中的常见挑战,尤其对于大规模运行的集群来说可谓至关重要。
![file]()
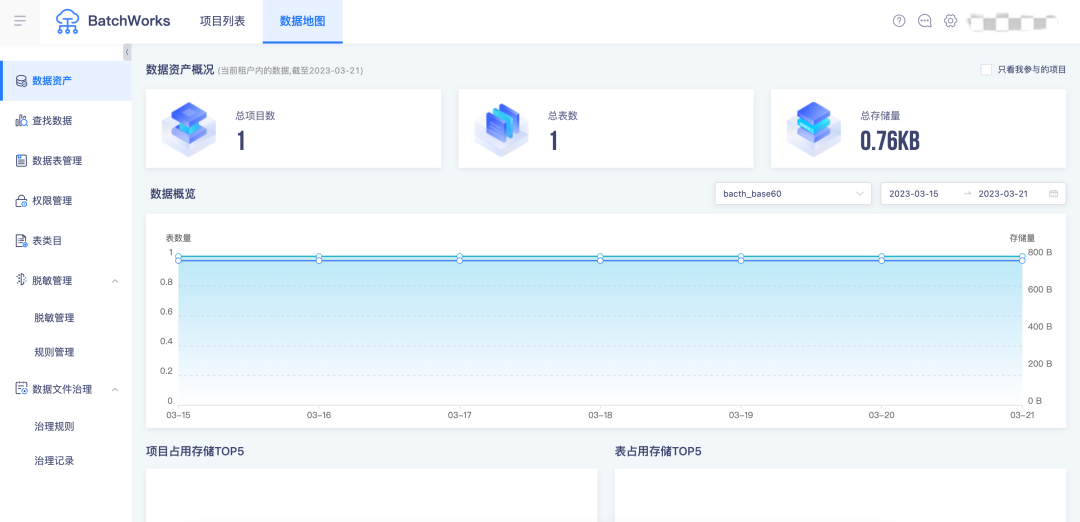
数据地图是离线开发产品的基本使用单位,包含全部表和项目的相关信息,可以对表做相关的权限管理和脱敏管理操作,以及可以展示对应项目占用情况和其表的占用情况。数据地图可以帮助用户更好地查找、理解和使用数据。
本文将结合两者,和大家聊聊数据地图中的小文件治理应该怎么做。
小文件的危害
小文件通常指文件大小要比 HDFS 块大小还要小很多的文件,大量的小文件会给 Hadoop 集群的扩展性和性能带来严重的影响。
NameNode 在内存中维护整个文件系统的元数据镜像、用户 HDFS 的管理,其中每个 HDFS 文件元信息(位置、大小、分块等)对象约占150字节,如果小文件过多,会占用大量内存,直接影响 NameNode 的性能。相对地,HDFS 读写小文件也会更加耗时,因为每次都需要从 NameNode 获取元信息,并与对应的 DataNode 建立连接。如果 NameNode 在宕机中恢复,也需要更多的时间从元数据文件中加载。
同时,小文件会给 Spark SQL 等查询引擎造成查询性能的损耗,大量的数据分片信息以及对应产生的 Task 元信息也会给 Spark Driver 的内存造成压力,带来单点问题。此外,入库操作最后的 commit job 操作,在 Spark Driver 端单点做,很容易出现单点的性能问题。
数据地图中小文件治理的做法
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode),块的大小默认为128MB,当文件大小为128时,Hadoop 集群的计算效率最高。因此对非分区表按表进行数据文件合并,使表/分区数据文件的大小接近128M,以此进行小文件的优化。
具体到数据地图中是怎么做的呢?
在离线开发平台中创建出来的表或者底层表都可以通过数据地图功能维护,我们每天会定时更新这些表的基本信息进行统一维护管理。
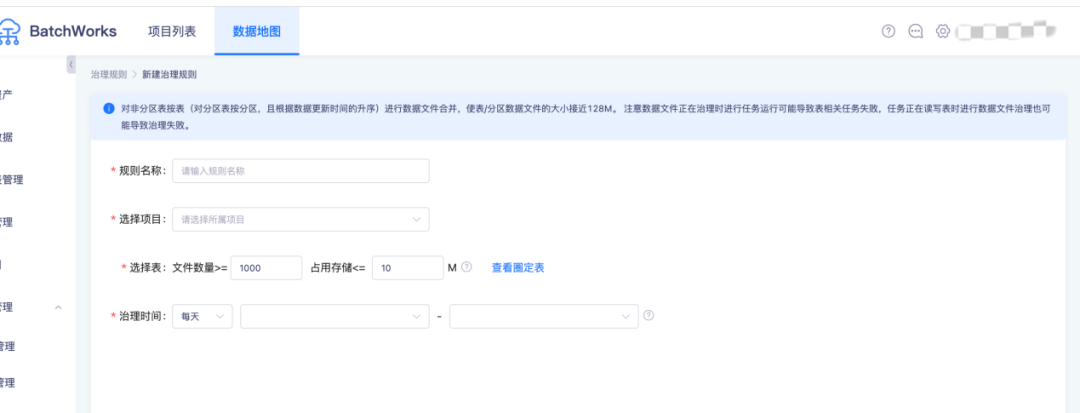
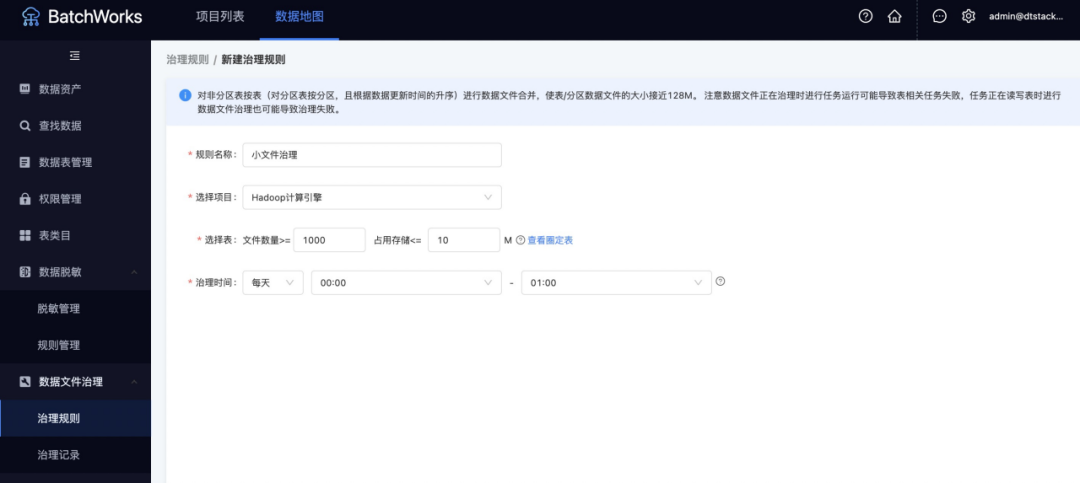
在数据地图中可以根据文件数量和占用存储创建相应的治理规则,按照每天每周或每月治理。
![file]()
参数说明
· 规则名称:新建规则的名称
· 选择项目:小文件合并规则生效的项目
· 选择表:这里配置的是圈定需要合并的表范围,判断条件是 and,例如表的文件数量大于1000并且占用总存储小于10M时,才会对该表中的文件进行合并操作
· 治理时间:该规则的调度周期,例如每天的凌晨00:00~01:00进行小文件合并,注意如果小文件合并时间到了结束的时间,还没有合并完成,则会结束当前的合并,等待下次处理
![file]()
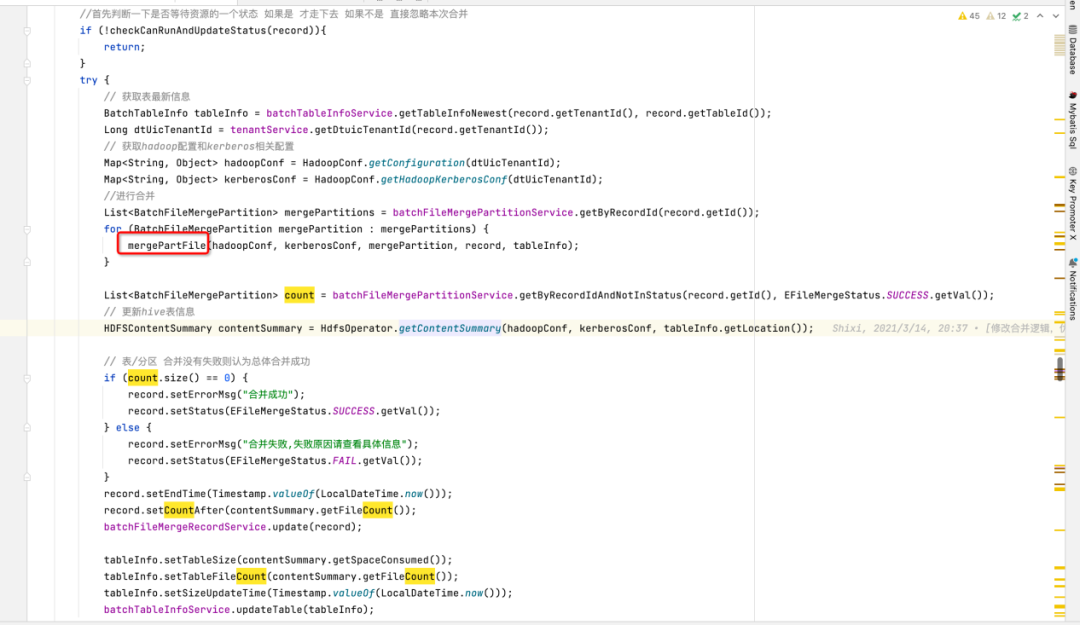
根据治理规则查询出所有符合信息的表,判断该表是否为分区表。如果为非分区表则对该表进行文件治理,如果为分区表则按照分区进行治理,最后创建治理记录。
![file]()
每天定时任务触发,根据告警记录查询记录中满足条件的表的基本信息状态。
![file]()
● 小文件合并的具体步骤
1)备份文件
先创建临时路径,把文件复制到临时路径中去,再创建要合并的临时文件
![file]()
2)小文件合并
执行 HDFS 的 fileMerge 请求合并文件
![file]()
真正调用 hive-exec 方法处理,判断是否达到阈值合并文件
![file]()
![file]()
3)将合并的文件覆盖到原文件中去
判断如果合并完成,删除原路径下的数据,把临时路径修改为原来的真实路径
![file]()
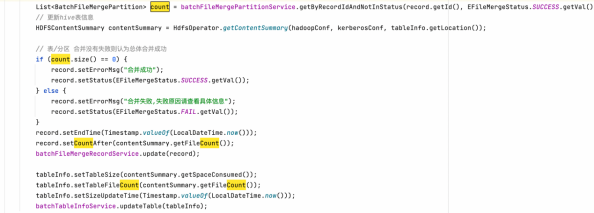
全部处理完成后,查询 rdos_file_merge_partition 表是否为异常信息打印,若不存在异常信息,更新治理记录表完成治理,并更新数据地图中的表信息
![file]()
治理记录表把握整体的治理成功失败状态,分区信息治理信表维护了整个治理记录哪些表治理失败的记录,最后全量返回对应的是失败或成功状态。
· 分区信息治理信表:rdos_file_merge_partition
· 治理记录表:rdos_file_merge_record
最后把表结构放在下面,有兴趣的小伙伴可以自行查看:
CREATE TABLE `rdos_file_merge_partition` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`project_id` int(11) DEFAULT NULL COMMENT '项目id',
`tenant_id` int(11) DEFAULT NULL COMMENT '租户id',
`record_id` int(11) DEFAULT NULL COMMENT '合并记录id',
`status` tinyint(1) DEFAULT NULL COMMENT '合并状态',
`start_time` datetime DEFAULT NULL COMMENT '开始时间',
`end_time` datetime DEFAULT NULL COMMENT '结束时间',
`error_msg` longtext COMMENT '错误信息',
`partition_name` varchar(255) DEFAULT NULL COMMENT '分区名',
`copy_location` varchar(1024) DEFAULT NULL COMMENT '备份路径',
`storage_before` varchar(255) DEFAULT NULL COMMENT '合并前占用存储',
`storage_after` varchar(255) DEFAULT NULL COMMENT '合并后占用存储',
`file_count_before` int(11) DEFAULT NULL COMMENT '合并前文件数量',
`file_count_after` int(11) DEFAULT NULL COMMENT '合并后文件数量',
`gmt_create` datetime DEFAULT NULL COMMENT '创建时间',
`gmt_modified` datetime DEFAULT NULL COMMENT '修改时间',
`is_deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除 0:未删除,1 :已删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='小文件合并分区信息表';
CREATE TABLE `rdos_file_merge_record` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`project_id` int(11) DEFAULT NULL COMMENT '项目id',
`tenant_id` int(11) DEFAULT NULL COMMENT '租户id',
`table_id` int(11) DEFAULT NULL COMMENT '合并hive表id',
`table_name` varchar(255) DEFAULT NULL COMMENT '表名',
`rule_id` int(11) DEFAULT NULL COMMENT '小文件合并规则id',
`location` varchar(1024) DEFAULT NULL COMMENT '存储位置',
`status` tinyint(1) DEFAULT NULL COMMENT '合并状态',
`error_msg` longtext COMMENT '错误信息',
`start_time` datetime DEFAULT NULL COMMENT '合并开始时间',
`end_time` datetime DEFAULT NULL COMMENT '合并结束时间',
`is_partition` tinyint(1) DEFAULT NULL COMMENT '是否是分区表',
`count_before` int(11) DEFAULT NULL COMMENT '合并前文件数量',
`count_after` int(11) DEFAULT NULL COMMENT '合并后文件数量',
`create_user_id` int(11) DEFAULT NULL COMMENT '创建用户',
`modify_user_id` int(11) DEFAULT NULL COMMENT '修改人id',
`gmt_create` datetime DEFAULT NULL COMMENT '创建时间',
`gmt_modified` datetime DEFAULT NULL COMMENT '修改时间',
`is_deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除 0:未删除, 1:已删除',
`plan_time` datetime NOT NULL COMMENT '计划时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='小文件合并记录表';
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack