概述 数据库迁移是实际工作中经常遇到的问题,比如由于磁盘空间、业务性能、项目改造等等原因,有从甲服务器迁移到乙服务器,从A种数据库迁移到B种数据库,从源路径迁移到另一个目标路径、同一个机器下从一个用户迁移到另一个用户等各种场景,有时需要整个数据库所有文件都迁移,有时只需要迁移部分数据文件如REDO、表空间文件等。 chameleon是一个基于Python的MySQL到openGauss的实时复制工具。该工具提供了初始全量数据的复制及增量数据的实时复制能力,支持MySQL中各种数据类型的迁移。本文就介绍如何使用pg_chameleon将MySQL数据库迁移至openGauss。 ![]()
文章目录 概述 一、工具介绍 二、工具安装 1.whl直接安装: 2. 源码安装 三. chameleon配置文件说明 四、执行迁移 1.初始化迁移过程 2.复制基础数据 3.开启实时同步复制 4.结束复制过程及清理资源 Q&A: 一、工具介绍 chameleon工具使用mysql-replication库从MySQL中提取row images,这些row images将以jsonb格式被存储到openGauss中。在openGauss中会执行一个pl/pgsql函数,解码jsonb并将更改重演到openGauss。同时,工具通过一次初始化配置,使用只读模式,将MySQL的全量数据拉取到openGauss,使得该工具提供了初始全量数据的复制以及后续增量数据的实时在线复制功能,可大大降低系统切换数据库时的停服时间。
二、工具安装 注意这里需要使用非root用户继续后续的操作,应该是为了控制执行权限。因为我将工具和openGauss安装在同一个机器,所以我这里直接使用的是omm用户。这里需要连接到外网进行一些工具依赖库的下载。
1.whl直接安装: 获取安装包 https://opengauss.obs.cn-south-1.myhuaweicloud.com/latest/chameleon/chameleon-3.0.0-py3-none-any.whl 创建python虚拟环境并激活。
python3 -m venv venv source venv/bin/activate 然后通过pip安装即可。
pip3 install ./chameleon-3.0.0-py3-none-any.whl 提示“Successfully installed ****”就可以。
- 源码安装 通过git下载源码:
git clone git@gitee.com:opengauss/openGauss-tools-chameleon.git
下载完成后,同样需要先创建python虚拟环境并激活:
python3 -m venv venv source venv/bin/activate
然后进入代码的目录,执行python install命令安装:
cd openGauss-tools-chameleon python3 setup.py install
安装完成后,不要退出python虚拟环境,可以开始使用chameleon工具。若退出了,后续继续执行进入Python环境的两行即可。
三. chameleon配置文件说明 pg_chameleon通过~/.pg_chameleon/configuration下的配置文件config-example.yaml定义迁移过程中的各项配置。整个配置文件大约分成四个部分,分别是全局设置、类型重载、目标数据库连接设置、源数据库设置。全局设置主要定义log文件路径、log等级等。类型重载让用户可以自定义类型转换规则,允许用户覆盖已有的默认转换规则。目标数据库连接设置用于配置连接至openGauss的连接参数。源数据库设置定义连接至MySQL的连接参数以及其他复制过程中的可配置项目。
完整的配置文件如下所示:
# global settings pid_dir: '~/.pg_chameleon/pid/' log_dir: '~/.pg_chameleon/logs/' log_dest: file log_level: info log_days_keep: 10 rollbar_key: '' rollbar_env: '' type_override allows the user to override the default type conversion into a different one. type_override: "tinyint(1)": override_to: boolean override_tables: - "*" postgres destination connection pg_conn: host: "127.0.0.1" port: "15400" user: "opengauss_test" password: "Gauss_234" database: "opengauss_db" charset: "utf8" sources: mysql: readers: 4 writers: 4 db_conn: host: "1.1.1.1" port: "3306" user: "mysql_t1" password: "Mysql_234" charset: 'utf8' connect_timeout: 10 schema_mappings: mysql_database: mysql_db1_sch limit_tables: skip_tables: grant_select_to: - usr_readonly lock_timeout: "120s" my_server_id: 100 replica_batch_size: 10000 replay_max_rows: 10000 batch_retention: '1 day' copy_max_memory: "300M" copy_mode: 'file' out_dir: /tmp sleep_loop: 1 on_error_replay: continue on_error_read: continue auto_maintenance: "disabled" gtid_enable: false type: mysql skip_events: insert: - delphis_mediterranea.foo # skips inserts on delphis_mediterranea.foo delete: - delphis_mediterranea # skips deletes on schema delphis_mediterranea update: keep_existing_schema: No migrate_default_value: Yes
配置文件使用yaml文件规则配置,需要特别注意对齐,缩进表示层级关系,缩进时不允许使用Tab键,只允许使用空格,缩进的空格数目不重要,但相同层级的元素左侧需要对齐。 以上配置文件的含义是,迁移数据时,MySQL侧使用的用户名密码分别是 mysql_t1 和 Mysql_234。MySQL服务器的IP和port分别是1.1.1.1和3306,待迁移的数据库是mysql_database。 openGauss侧使用的用户名密码分别是 opengauss_test和 Gauss_234。openGauss服务器的IP和port分别是127.0.0.1(因为我是在openGauss服务器上部署的迁移工具)和5432,目标数据库是opengauss_db,同时会在opengauss_database下创建mysql_db1_sch,迁移的表都将位于该schema下。 需要注意的是,这里使用的用户需要有远程连接MySQL和openGauss的权限,以及对对应数据库的读写权限。同时对于openGauss,运行chameleon所在的机器需要在openGauss的远程访问白名单中。对于MySQL,用户还需要有RELOAD、REPLICATION CLIENT、REPLICATION SLAVE的权限。
(venv) [omm@pekphisprb70593 chameleon]$ chameleon set_configuration_files creating directory /home/omm/.pg_chameleon creating directory /home/omm/.pg_chameleon/configuration/ creating directory /home/omm/.pg_chameleon/logs/ creating directory /home/omm/.pg_chameleon/pid/ copying configuration example in /home/omm/.pg_chameleon/configuration//config-example.yml (venv) [omm@pekphisprb70593 configuration]$ touch config-example.yml (venv) [omm@pekphisprb70593 configuration]$ vi config-example.yml (venv) [omm@pekphisprb70593 configuration]$ ll total 4 -rw------- 1 omm dbgrp 2276 Sep 16 10:18 config-example.yml (venv) [omm@pekphisprb70593 configuration]$ cp config-example.yml default.yml (venv) [omm@pekphisprb70593 configuration]$ vi default.yml
根据上面的示例修改default.yml文件,注意这个冒号后面有空格。
四、执行迁移 1.初始化迁移过程 开始使用工具做迁移过程。先初始化复制流。
chameleon create_replica_schema --config default chameleon add_source --config default --source mysql
2.复制基础数据 接下来开始复制基础数据。这里使用的Mysql和数据与上一篇相同。 chameleon init_replica --config default --source mysql
![]()
做完此步骤后,将把MySQL当前的全量数据复制到openGauss。可以在openGauss侧查看全量数据复制后的情况。 数据已复制成功。 ![]()
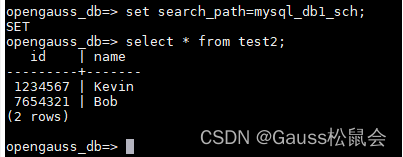
3.开启实时同步复制 在MySQL侧插入数据
mysql> insert into test2 values (7654321,'Bob');
在openGauss可以马上查询到 ![]()
新建表插入数据也是可以的: 在MySQL侧新建t1,插入一条数据
mysql> create table if not exists t1(id int(10)); mysql> insert into t1 values (1);
在openGauss侧查询
![]()
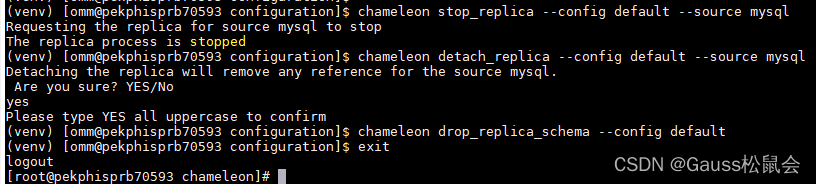
4.结束复制过程及清理资源 chameleon stop_replica --config default --source mysql chameleon detach_replica --config default --source mysql chameleon drop_replica_schema --config default ![]()
Q&A: q1: 执行报错 [root@pekphisprb70593 chameleon]# python3 -m venv venv [root@pekphisprb70593 chameleon]# source venv/bin/activate (venv) [root@pekphisprb70593 chameleon]# chameleon set_configuration_files pg_chameleon cannot be run as root
A: 不允许用root,切换omm用户执行
q2: omm用户执行没有权限 [omm@pekphisprb70593 chameleon]$ python3 -m venv venv Error: [Errno 13] Permission denied: ‘/opt/software/chameleon/venv’ A: 使用omm 用户安装 和进入 python3 source命令 q3:执行(venv) [omm@pekphisprb70593 logs]$ chameleon add_source --config default --source mysql 报错
results: ('count' 'BIGINT', 'dest_schema' 'pg_catalog.text') statement_id: py:0x7f854e40ef60 string: WITH t_check AS ( SELECT (jsonb_each_text(jsb_schema_mappings)).value AS dest_schema FROM sch_chameleon.t_sources WHERE i_id_source <> -1 UNION ALL SELECT value AS dest_schema FROM json_each_text('"mysql_db1:mysql_db1_sch"'::json) ) SELECT count(dest_schema), dest_schema FROM t_check GROUP BY dest_schema HAVING count(dest_schema)>1 ; CONNECTION: [idle] client_address: 127.0.0.1/32 client_port: 39710 version: (openGauss 3.0.0 build 02c14696) compiled at 2022-04-01 18:12:34 commit 0 last mr on x86_64-unknown-linux-gnu, compiled by g++ (GCC) 7.3.0, 64-bit CONNECTOR: [IP4] pq://opengauss_test:***@127.0.0.1:15400/opengauss_db?[sslmode]=disable category: None
A:schema_mapping 的配置项,注意冒号后面有空格
![]() 除了基础数据同步,chameleon后续还将支持将视图、触发器、自定义函数、存储过程等数据库对象从MySQL迁移到openGauss。期待一下吧~ openGauss: 一款高性能、高安全、高可靠的企业级开源关系型数据库。
除了基础数据同步,chameleon后续还将支持将视图、触发器、自定义函数、存储过程等数据库对象从MySQL迁移到openGauss。期待一下吧~ openGauss: 一款高性能、高安全、高可靠的企业级开源关系型数据库。
🍒如果您觉得博主的文章还不错或者有帮助的话,请关注一下博主,如果三连点赞评论收藏就更好啦!谢谢各位大佬给予的支持!



 除了基础数据同步,chameleon后续还将支持将视图、触发器、自定义函数、存储过程等数据库对象从MySQL迁移到openGauss。期待一下吧~ openGauss: 一款高性能、高安全、高可靠的企业级开源关系型数据库。
除了基础数据同步,chameleon后续还将支持将视图、触发器、自定义函数、存储过程等数据库对象从MySQL迁移到openGauss。期待一下吧~ openGauss: 一款高性能、高安全、高可靠的企业级开源关系型数据库。