.NET 7 内置了速率限制(Rate Limiting)功能,速率限制指的是限制可访问资源的请求数。例如数据库每分钟可以安全处理 1000 个请求,再多不确定会不会崩。这时就可以在应用程序中放一个速率限制器,规定每分钟只允许 1000 个请求,在达到这个数量后开始拒绝请求。这是一种保护资源的方法,可以避免应用在高浏览的情况下崩溃。
有很多种不同的算法来控制请求流,下面介绍 .NET 7 中提供的 4 种方法:
并发限制
顾名思义,并发限制器就是限制有多少并发请求可以访问资源。如果限制是 10,那么只有 10 个请求可以同时访问一个资源,第 11 个请求将被拒绝。
一旦前面的请求完成,则允许的请求数量会增加 1,当第二个请求完成时,数量增加到 2,依此类推。该算法是通过 释放 RateLimitLease 来完成的。
令牌桶
令牌桶是另一种算法,就像一个装满令牌的桶。每隔一段时间,桶内会新增固定数量的令牌,但令牌数不能超过桶可容纳的最大数量。当一个请求进来时,它会获取并保存一个令牌,如果存储桶为空,则新请求进入时没有令牌可获取,即将被拒绝访问资源。
假设单个桶可以容纳 10 个令牌,且每分钟往里面加入 2 个令牌。现在有 3 个请求进来了,剩下 7 个令牌。一分钟后,桶自动补充到 9 个令牌,然后 9 个请求瞬间取走所有令牌。那么接下来在桶内添加令牌之前,所有请求都不允许访问资源。如果接下来没有请求,则桶会在 5 分钟内自动补到 10 个令牌,然后等待请求。
固定窗口限制
固定窗口算法使用“窗口”的概念,窗口采用时间计量,在固定的一段时间内限制最大请求,并在切换到下一个窗口的时候重置请求数。
假设现在有一个最多只能容纳 100 人(最大请求数)的电影院(窗口),每场电影需要播放 2 个小时(窗口持续时间)。电影开始后,剩下的观众(请求)只能排队等待下一场窗口,排队的最大数量也是 100 ,超出的部分不允许继续排队,只能等待下一个窗口开始后才能继续排队。
滑动窗口限制
滑动窗口算法类似于固定窗口算法,但增加了“段(segments)”的概念。
- 一个段是一个窗口的一部分,如果将前面 2 小时的窗口分成 4 个段,则会有 4 个 30 分钟的段。此外还有一个“段索引”,它始终指向窗口中的最新段。
- 30 分钟内的请求进入最新的段,且每 30 分钟窗口滑动一个段。如果在窗口滑过段期间出现了新的请求,则该请求会被刷新,且段的最大限制会增加。如果没有请求,则段的限制保持不变。
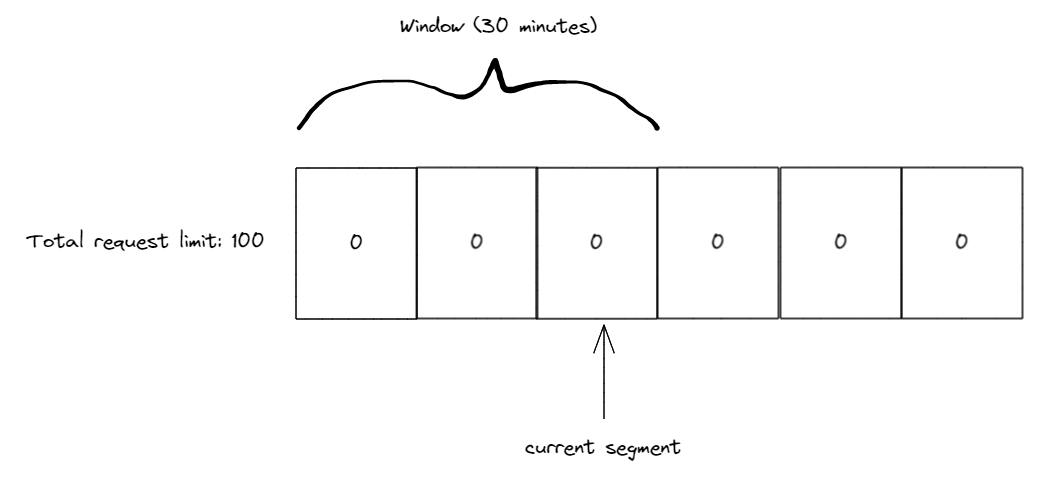
例设现在有一个滑动窗口,它包含 3 个 10 分钟的段,最多只能接受100 个请求。现在它的初始状态是 3 个段,计数均为 0,当前的段索引指向第 3 个段。
![]()
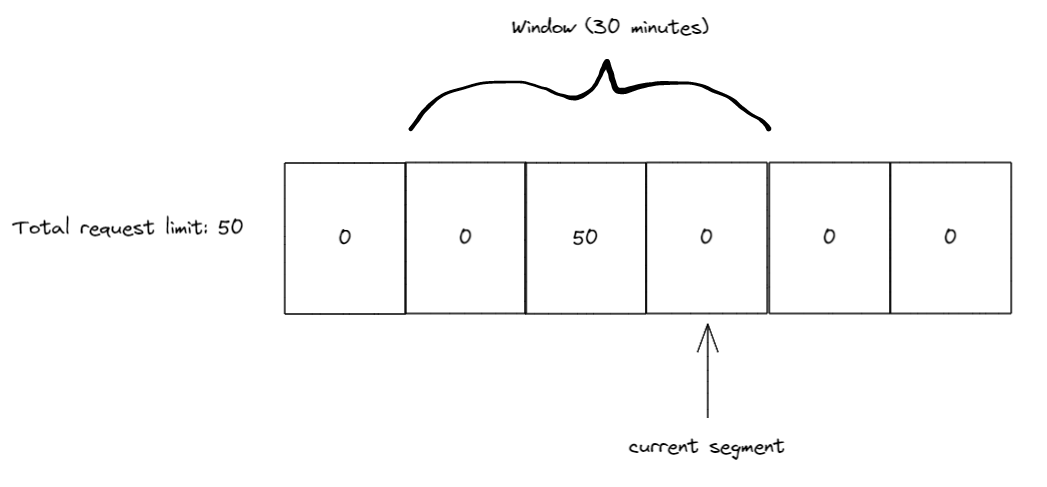
在前 10 分钟内,我们收到 50 个请求,所有请求都在第 3 段(段索引所在的位置)。10 分钟过去后,我们将窗口滑动 1 段,同时将当前段索引移动到第 4 段。
![]()
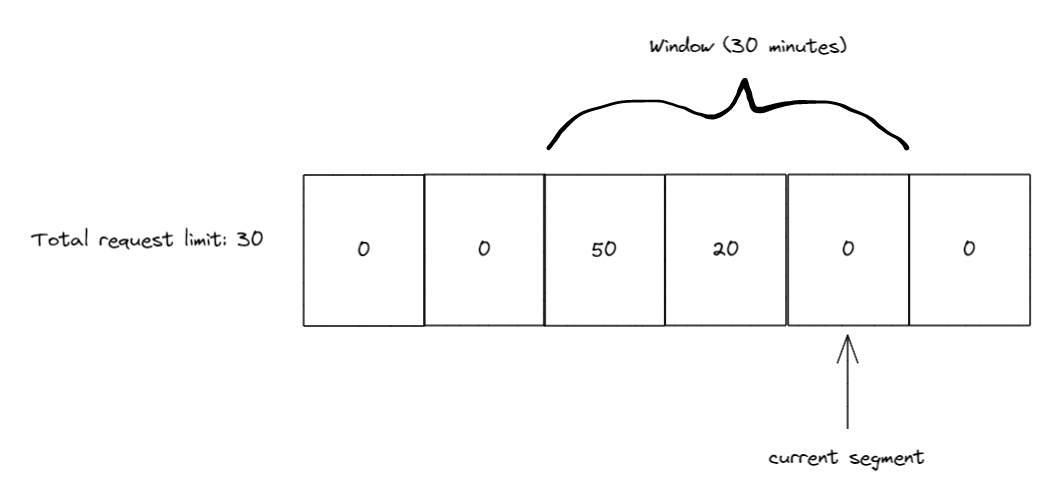
接下来的 10 分钟内,我们又收到了 20 个请求,所以现在第 3 段有 50 个,第 4 段有 20 个。同样在 10 分钟过去后窗口开始滑动,因此当前的段索引指向了 5,而由于段 3 和段 4 都在窗口内,因此窗口只剩 20 个请求名额。
![]()
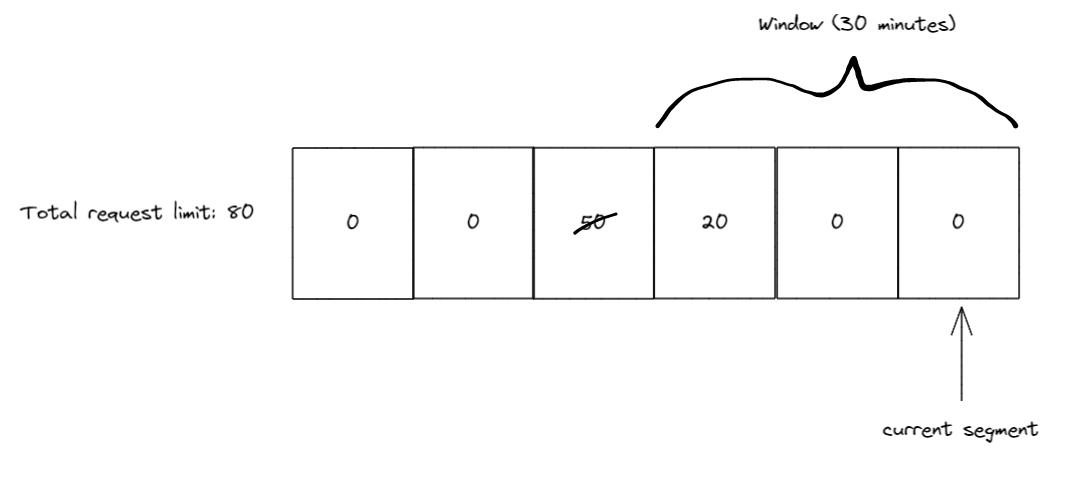
又过了 10 分钟后,再次滑动窗口,这一次窗口滑动后段索引为 6,但段 3(有 50 个请求的段)已位于窗口之外,因此窗口收回了 50 个请求限额。由于段 4 仍有 20 个请求,所以滑动窗口的请求限额变为 80 。
![]()
微软博客中有关于速率限制功能和相关 API 、中间件的详细介绍,对此功能感兴趣的朋友可在 Nuget 中进一步了解。