摘要:本文归纳了Neo4j和Nebula两个开源图数据库的两个pull request修复的堆栈溢出问题,并试着写写通过阅读pr中的问题而得到的一些启发
本文分享自华为云社区《巧妙构造的查询语句会导致堆栈溢出?从两个开源图数据库PR看查询执行时的编码设计问题》,作者:蜉蝣与海 。
导读&简介
查询语言(Query Language)的出现方便了用户在计算引擎上执行各种操作,就图数据库而言,neo4j支持查询语言cypher,nebula有其独有的查询语言nGQL。由于查询语言规则依赖语言自身文法,用户使用查询语言自由度较大,输入灵活,一般测试手段难以覆盖到所有情况,所以在某种程度上复杂的查询语句是各类计算产品健壮性的试金石,本文归纳了两个开源产品pr(pull request)时修复的堆栈溢出问题,并试着写写通过阅读pr中的问题而得到的一些启发。
先上链接,如果你更喜欢读代码而不是听我叨叨:StackOverFlowError occurs when reducing a List(neo4j):
issue:https://github.com/neo4j/neo4j/issues/12683
pr:https://github.com/neo4j/neo4j/commit/8336c2f75f4baa4283babe31293899020092d5d1
fix crash when the expression exceed the depth(nebula):
https://github.com/vesoft-inc/nebula/pull/3606
代码分析
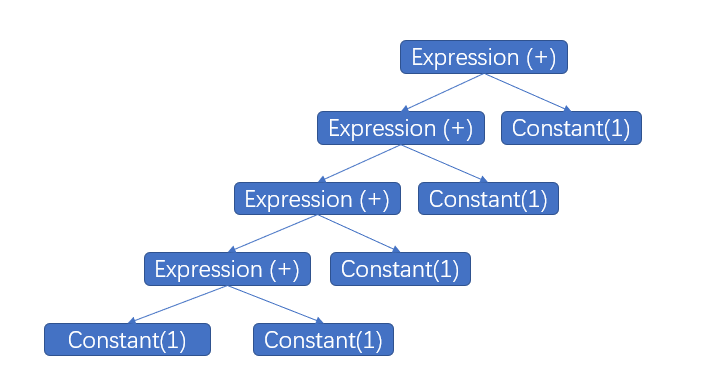
在这两个PR中都提到了StackOverFlow。我们先试着描述一下问题,Nebula的pr要稍微好懂一点:可以试着打开测试用例来看之前有问题的语句,是一堆 1+1+1+…+1+1
as result, 当+1+1这样的语法要素出现的次数太多时,会报栈溢出。通过阅读parser.yy可以看到,对于每个加法符号,都会生成一个表达式对象:
// parser.yy
expression_internal
:constant_expression {
$$ = $1;
} ...
| expression_internal PLUS expression_internal {
$$ = ArithmeticExpression::makeAdd(qctx->objPool(), $1, $3);
}
static ArithmeticExpression* makeAdd(ObjectPool* pool,
Expression* lhs = nullptr,
Expression* rhs = nullptr) {
return pool->add(new ArithmeticExpression(pool, Expression::Kind::kAdd, lhs, rhs));
}
对于像“1+1+1+1+1”这样的表达式,调用栈就会成这样:
![]()
当用户输入的+1的数目比较多时,头部expression下就会链式挂载若干个子expression,如果在语法解析层和语法执行层没有对表达式做特殊的处理,这些子链会被递归调用(即父expression会调用子expression),递归的深度取决于子链的数目。
neo4j的issue有些小众,其关注的是对这样自定义聚集操作的语句:
unwind range(0,15000) as xxx
with collect([xxx]) as set1
with reduce(c = [], x in set1| c + x) as fromNodes
unwind fromNodes as x return x
其中range(0,15000)会生成一个列表,共15000个元素,如[0,1,2,…,14998,14999]这样。unwind会对这个链表进行展开,通过collect([xxx])对每个元素生成一个独立的列表并打包成set1([0],[1],…[14998],[14999]),然后通过reduce操作对这些独立的元素进行拼接。问题就是出在拼接的时候:reduce看起来是不断在进行foreach(x in set1){c = c + x}这样的操作,然而实际代码实现时,对15000个元素进行了展开,生成的是c=x0+x1+x2+…+x14999。并没有使用一个变量去缓存c的中间状态,而是试图通过不断的二元计算直接算出c的结果。代码如下:
// CypherMath.Add
if ( lhsIsListValue && rhs instanceof ListValue )
{
return VirtualValues.concat( (ListValue) lhs, (ListValue) rhs );
}
// VirtualValues.concat
public static ListValue concat( ListValue... lists )
{
return new ListValue.ConcatList( lists );
}
这样会有15000个ConcatList链式连接,实际计算时15000个ConcatList被递归调用,生成了一个深为15000的函数调用栈。
上述代码的问题和PR中的解决方案
可以看到,不管是C++的nebula,还是java写的neo4j,通过巧妙地构造查询语句,都可以使得内部执行时生成深度较深的函数调用栈。而函数调用栈的深度,在不同编程语言下都是有限制的(大部分查询语言栈空间是M级的,参见附录[1]和附录[2])。超过这个限制,轻则直接导致语句崩溃,如果系统的异常处理机制不够完善,也可能导致更严重的问题。
nebula和neo4j对这个问题采用了两种不同的解决方案。在nebula中,通过在parser.yy中调用checkExprDepth方法,去检查最大递归调用深度,超出则报错;而在neo4j中,通过构建一个list来缓存concat的元素列表,进而消除了递归调用。
// neo4j更新list的代码,解析语句阶段,原始list调用add方法,会生成一个包含value元素的新的list,这个新list会替换调原始的list
public ListValue add( ListValue value )
{
var newSize = lists.length + 1;
var newArray = new ListValue[newSize];
System.arraycopy( lists, 0, newArray, 0, lists.length );
newArray[lists.length] = value;
return new ConcatList( newArray);
}
容易发现nebula的解决方案更直接一点,过深的调用栈一律拒绝;而neo4j则是通过一些容器(如List,Stack)等消除了递归调用,对用户更加友好,但是如果其他地方也出现类似情况,可能需要做针对性修改。
PR带来的启示
在查询语言的解析和计划执行的编码设计阶段,为查询语句中的某个语法成分(如表达式、函数、子句)编写执行逻辑的代码往往是相对直观且易于理解的。比如加法操作可以直接构造一个ArithmeticExpression对象,List拼接可以直接构造一个ConcatList对象。然而由于用户输入的不确定性,需要考虑多个语法成分联动,或者某几个语法成分批量出现时带来的问题(例如深度过深的递归)。要么像nebula一样在量上做限制,量太大直接报错;要么像neo4j一样针对每个会因为批量联动带来问题的点给出不会出错的编码设计。通过这两种手段,可以减少极端语句对系统的影响,提高系统的健壮性。
附录
[1]C++函数调用栈溢出demo:https://blog.csdn.net/qq_44989173/article/details/115986871?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1.pc_relevant_paycolumn_v3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1.pc_relevant_paycolumn_v3&utm_relevant_index=2
[2]JVM StackOverFlow和OOM 场景模拟:https://blog.csdn.net/HUDCHSDI/article/details/113817579
点击关注,第一时间了解华为云新鲜技术~