摘要:很多大数据计算都是用 SQL 实现的,跑得慢时就要去优化 SQL,但常常碰到让人干瞪眼的情况。
本文分享自华为云社区《做 SQL 性能优化真是让人干瞪眼》,作者: 石臻臻的杂货铺 。
很多大数据计算都是用 SQL 实现的,跑得慢时就要去优化 SQL,但常常碰到让人干瞪眼的情况。比如,存储过程中有三条大概形如这样的语句执行得很慢:
select a,b,sum(x) from T group by a,b where …;
select c,d,max(y) from T group by c,d where …;
select a,c,avg(y),min(z) from T group by a,c where …;
这里的 T 是个有数亿行的巨大表,要分别按三种方式分组,分组的结果集都不大。
分组运算要遍历数据表,这三句 SQL 就要把这个大表遍历三次,对数亿行数据遍历一次的时间就不短,何况三遍。
这种分组运算中,相对于遍历硬盘的时间,CPU 计算时间几乎可以忽略。如果可以在一次遍历中把多种分组汇总都计算出来,虽然 CPU 计算量并没有变少,但能大幅减少硬盘读取数据量,就能成倍提速了。
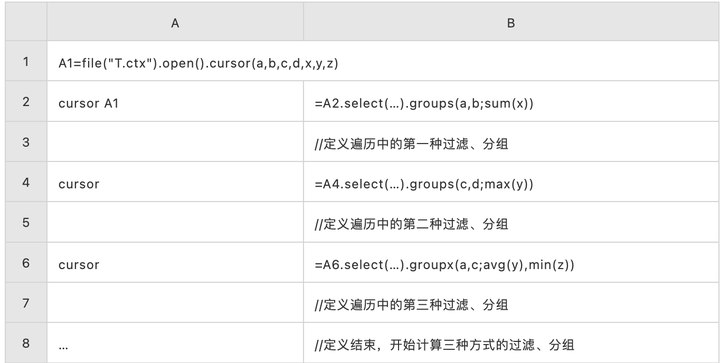
如果 SQL 支持类似这样的语法:
from T -- 数据来自 T 表
select a,b,sum(x) group by a,b where … -- 遍历中的第一种分组
select c,d,max(y) group by c,d where … -- 遍历中的第二种分组
select a,c,avg(y),min(z) group by a,c where …; -- 遍历中的第三种分组
能一次返回多个结果集,那就可以大幅提高性能了。
可惜, SQL 没有这种语法,写不出这样的语句,只能用个变通的办法,就是用 group a,b,c,d 的写法先算出更细致的分组结果集,但要先存成一个临时表,才能进一步用 SQL 计算出目标结果。SQL 大致如下:
create table T_temp as select a,b,c,d,
sum(case when … then x else 0 end) sumx,
max(case when … then y else null end) maxy,
sum(case when … then y else 0 end) sumy,
count(case when … then 1 else null end) county,
min(case when … then z else null end) minz
group by a,b,c,d;
select a,b,sum(sumx) from T_temp group by a,b where …;
select c,d,max(maxy) from T_temp group by c,d where …;
select a,c,sum(sumy)/sum(county),min(minz) from T_temp group by a,c where …;
这样只要遍历一次了,但要把不同的 WHERE 条件转到前面的 case when 里,代码复杂很多,也会加大计算量。而且,计算临时表时分组字段的个数变得很多,结果集就有可能很大,最后还对这个临时表做多次遍历,计算性能也快不了。大结果集分组计算还要硬盘缓存,本身性能也很差。
还可以用存储过程的数据库游标把数据一条一条 fetch 出来计算,但这要全自己实现一遍 WHERE 和 GROUP 的动作了,写起来太繁琐不说,数据库游标遍历数据的性能只会更差!
只能干瞪眼!
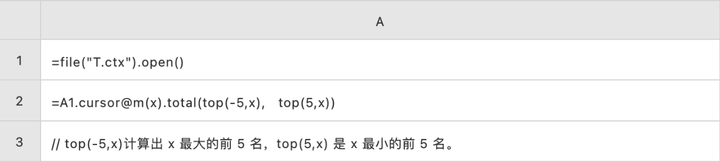
TopN 运算同样会遇到这种无奈。举个例子,用 Oracle 的 SQL 写 top5 大致是这样的:
select * from (select x from T order by x desc) where rownum<=5
表 T 有 10 亿条数据,从 SQL 语句来看,是将全部数据大排序后取出前 5 名,剩下的排序结果就没用了!大排序成本很高,数据量很大内存装不下,会出现多次硬盘数据倒换,计算性能会非常差!
避免大排序并不难,在内存中保持一个 5 条记录的小集合,遍历数据时,将已经计算过的数据前 5 名保存在这个小集合中,取到的新数据如果比当前的第 5 名大,则插入进去并丢掉现在的第 5 名,如果比当前的第 5 名要小,则不做动作。这样做,只要对 10 亿条数据遍历一次即可,而且内存占用很小,运算性能会大幅提升。
这种算法本质上是把 TopN 也看作与求和、计数一样的聚合运算了,只不过返回的是集合而不是单值。SQL 要是能写成这样:select top(x,5) from T 就能避免大排序了。
然而非常遗憾,SQL 没有显式的集合数据类型,聚合函数只能返回单值,写不出这种语句!
不过好在全集的 TopN 比较简单,虽然 SQL 写成那样,数据库却通常会在工程上做优化,采用上述方法而避免大排序。所以 Oracle 算那条 SQL 并不慢。
但是,如果 TopN 的情况复杂了,用到子查询中或者和 JOIN 混到一起的时候,优化引擎通常就不管用了。比如要在分组后计算每组的 TopN,用 SQL 写出来都有点困难。Oracle 的 SQL 写出来是这样
select * from
(select y,x,row_number() over (partition by y order by x desc) rn from T)
where rn<=5
这时候,数据库的优化引擎就晕了,不会再采用上面说的把 TopN 理解成聚合运算的办法。只能去做排序了,结果运算速度陡降!
假如 SQL 的分组 TopN 能这样写:
select y,top(x,5) from T group by y
把 top 看成和 sum 一样的聚合函数,这不仅更易读,而且也很容易高速运算。
可惜,不行。还是干瞪眼!
关联计算也是很常见的情况。以订单和多个表关联后做过滤计算为例,SQL 大体是这个样子:
select o.oid,o.orderdate,o.amount
from orders o
left join city ci on o.cityid = ci.cityid
left join shipper sh on o.shid=sh.shid
left join employee e on o.eid=e.eid
left join supplier su on o.suid=su.suid
where ci.state='New York'
and e.title = 'manager'
and ...
订单表有几千万数据,城市、运货商、雇员、供应商等表数据量都不大。过滤条件字段可能会来自于这些表,而且是前端传参数到后台的,会动态变化。
SQL 一般采用 HASH JOIN 算法实现这些关联,要计算 HASH 值并做比较。每次只能解析一个 JOIN,有 N 个 JOIN 要执行 N 遍动作,每次关联后都需要保持中间结果供下一轮使用,计算过程复杂,数据也会被遍历多次,计算性能不好。
通常,这些关联的代码表都很小,可以先读入内存。如果将订单表中的各个关联字段预先做序号化处理,比如将雇员编号字段值转换为对应雇员表记录的序号。那么计算时,就可以用雇员编号字段值(也就是雇员表序号),直接取内存中雇员表对应位置的记录,性能比 HASH JOIN 快很多,而且只需将订单表遍历一次即可,速度提升会非常明显!
也就是能把 SQL 写成下面的样子:
select o.oid,o.orderdate,o.amount
from orders o
left join city c on o.cid = c.# -- 订单表的城市编号通过序号 #关联城市表
left join shipper sh on o.shid=sh.# -- 订单表运货商号通过序号 #关联运货商表
left join employee e on o.eid=e.# -- 订单表的雇员编号通过序号 #关联雇员表
left join supplier su on o.suid=su.# -- 订单表供应商号通过序号 #关联供应商表
where ci.state='New York'
and e.title = 'manager'
and ...
可惜的是,SQL 使用了无序集合概念,即使这些编号已经序号化了,数据库也无法利用这个特点,不能在对应的关联表这些无序集合上使用序号快速定位的机制,只能使用索引查找,而且数据库并不知道编号被序号化了,仍然会去计算 HASH 值和比对,性能还是很差!
有好办法也实施不了,只能再次干瞪眼!
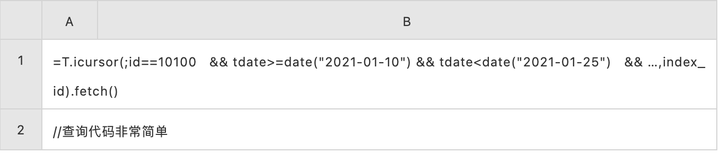
还有高并发帐户查询,这个运算倒是很简单:
select id,amt,tdate,… from T
where id='10100'
and tdate>= to_date('2021-01-10', 'yyyy-MM-dd')
and tdate<to_date('2021-01-25', 'yyyy-MM-dd')
and …
在 T 表的几亿条历史数据中,快速找到某个帐户的几条到几千条明细,SQL 写出来并不复杂,难点是大并发时响应速度要达到秒级甚至更快。为了提高查询响应速度,一般都会对 T 表的 id 字段建索引:
create index index_T_1 on T(id)
在数据库中,用索引查找单个帐户的速度很快,但并发很多时就会明显变慢。原因还是上面提到的 SQL 无序理论基础,总数据量很大,无法全读入内存,而数据库不能保证同一帐户的数据在物理上是连续存放的。硬盘有最小读取单位,在读不连续数据时,会取出很多无关内容,查询就会变慢。高并发访问的每个查询都慢一点,总体性能就会很差了。在非常重视体验的当下,谁敢让用户等待十秒以上?!
容易想到的办法是,把几亿数据预先按照帐户排序,保证同一帐户的数据连续存储,查询时从硬盘上读出的数据块几乎都是目标值,性能就会得到大幅提升。
但是,采用 SQL 体系的关系数据库并没有这个意识,不会强制保证数据存储的物理次序!这个问题不是 SQL 语法造成的,但也和 SQL 的理论基础相关,在关系数据库中还是没法实现这些算法。
那咋办?只能干瞪眼吗?
不能再用 SQL 和关系数据库了,要使用别的计算引擎。
开源的集算器 SPL 基于创新的理论基础,支持更多的数据类型和运算,能够描述上述场景中的新算法。用简单便捷的 SPL 写代码,在短时间内能大幅提高计算性能!
上面这些问题用 SPL 写出来的代码样例如下:
一次遍历计算多种分组
![]()
用聚合的方式计算 Top5
全集 Top5(多线程并行计算)
![]()
分组 Top5(多线程并行计算)
![]()
用序号做关联的 SPL 代码:
系统初始化
![]()
查询
![]()
高并发帐户查询的 SPL 代码:
数据预处理,有序存储
![]()
帐户查询
![]()
除了这些简单例子,SPL 还能实现更多高性能算法,比如有序归并实现订单和明细之间的关联、预关联技术实现多维分析中的多层维表关联、位存储技术实现上千个标签统计、布尔集合技术实现多个枚举值过滤条件的查询提速、时序分组技术实现复杂的漏斗分析等等。
正在为 SQL 性能优化头疼的小伙伴们,来和我们一起探讨吧:
SPL下载地址:http://c.raqsoft.com.cn/article/1595816810031
SPL开源地址:https://github.com/SPLWare/esProc
点击关注,第一时间了解华为云新鲜技术~