Part 1 - 预写式日志
在计算机科学中,预写式日志[1](Write-Ahead logging,缩写 WAL)是关系数据库系统中用于提供原子性和持久性(事务ACID属性中的A与D)的一系列技术。在使用WAL的系统中,所有的修改在生效之前都要先写入log文件中。log文件中通常包括redo和undo信息。假设一个程序在执行某些操作的过程中机器掉电了。在重新启动时,程序可能需要知道当时执行的操作是成功了还是部分成功或者是失败了。如果使用了WAL,程序就可以检查log文件,并对突然掉电时计划执行的操作内容跟实际上执行的操作内容进行比较。在这个比较的基础上,程序就可以决定是撤销已做的操作还是继续完成已做的操作,或者是保持原样。
WAL允许用in-place方式更新数据库。另一种用来实现原子更新的方法是shadowpaging。用in-place方式做更新的主要优点是减少索引和块列表的修改。ARIES[2]是WAL系列技术常用的算法,其核心策略为:1)Write ahead logging,对于对象的任何变更都要首先记入日志,同时日志必须要先于对象被写入磁盘;2)Repeating history during Redo,在crash之后重启时,ARIES通过重新执行数据库在crash之前的行为,使数据库恢复到它crash之前那一刻的状态,然后undo掉crash时还在执行的事务;3)Logging changes during Undo,将在undo事务时对数据库所做的变更记录日志,保证在重复重启时不会重做。在文件系统中,WAL通常称为journaling[3]。
![]()
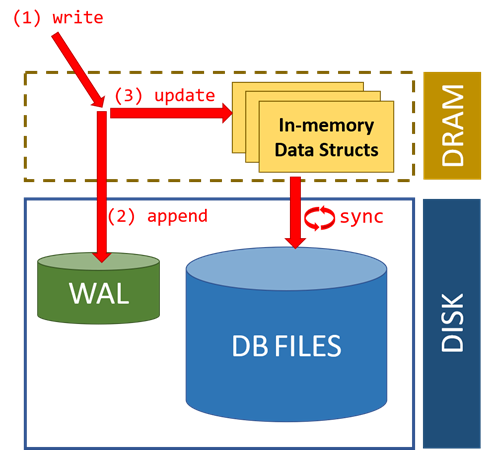
RocksDB[4]中的每个更新操作都会写到两个地方:1)写到磁盘上的WAL日志;2)一个名为memtable的内存数据结构,后续会被刷盘到SST文件。WAL会把memtable的操作序列化之后以日志文件形式存储在持久化介质中。在数据库出现崩溃的时候,WAL文件可以用于重新构建memtable,帮助数据库恢复数据库到一个一致的状态。当一个memtable被安全地落盘到持久化介质之后,相关的WAL日志会变成过期的,然后被归档,最终归档的日志会在一定时间后被从硬盘上删除。
1.1 WAL管理器
WAL文件使用一个递增的序列号生成到WAL文件夹。为了重新构建数据库的状态,这些文件会被按序列号顺序读取。WAL管理器提供把WAL文件作为一个可独立进行读取的抽象接口。内部使用Writer或者Reader抽象接口打开,并读取文件。
Writer提供一个抽象接口,用于在日志文件末尾增加数据。存储介质相关的内部细节信息通过WriteableFile接口处理。类似的,Reader提供一个抽象接口,用于从一个日志文件中顺序读取日志记录。内部的存储介质相关细节信息有SequentialFile接口处理。
1.2 WAL文件格式
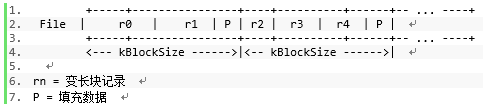
WAL文件由一系列的变长记录构成。记录通过kBlockSize(默认为32KB)聚集在一起。如果某个特定记录不能放入剩余的空间,那么剩余空间将会被空数据填充。writer写而reader读数据的时候,是按照一个kBlockSize大小的块来读的。
![]()
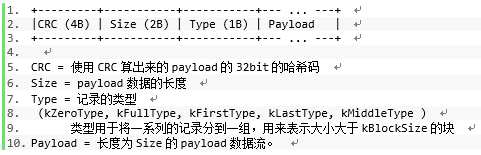
记录的排列格式如下所示:
![]()
WAL文件包含一系列的大小为32KB的块,唯一的例外是文件的末尾可能会包含一个分片的块。每个块都由一系列记录构成,一个记录不会在一个块的最后6个Byte开始(毕竟放不下)。任何剩下的数据都构成tailer,tailer由全0构成,读取的时候应该被跳过。如果当前块正好剩下7个Byte,并且一个新的非0长度记录被加入进来,那么write必须加一个FIRST记录(里面不含任何用户数据)来填充剩下的7个byte,然后在下一个块再提交用户数据。
![]()
![]()
FULL类型的记录保存完整的用户数据。FIRST,MIDDLE,LAST在不得不把用户数据切分成多个分片的时候使用(大多数是因为块边界问题)。FIRST是用户数据的第一个分片用的类型,LAST是最后一个用户数据分片用的记录类型,MIDDLE则是中间那些所有的其他数据的记录类型。
例子:考虑一个用户记录的序列:
![]()
![]() A会在第一个block里被存储为一个FULL记录。B会被分成三个分片:第一个分片占据第一个块剩下的空间,第二个分片占据第二个块的完整空间,第三个分片占据第三个块的开头部分。第三个块还剩下6个Byte,作为一个tailer,留空。C会在第四个块以FULL记录存储。
A会在第一个block里被存储为一个FULL记录。B会被分成三个分片:第一个分片占据第一个块剩下的空间,第二个分片占据第二个块的完整空间,第三个分片占据第三个块的开头部分。第三个块还剩下6个Byte,作为一个tailer,留空。C会在第四个块以FULL记录存储。
1.3 WAL的生命周期
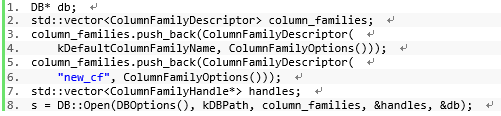
用一个例子来说明一个WAL的生命周期。一个RocksDB的db实例创建了两个列族:"new_cf"和"default"。一旦db被打开,一个新的WAL会在磁盘上被创建,以保证写持久性。
![]()
往列族中加入一些数据:
![]()
这时WAL需要记录所有的写操作。WAL会保持打开,并不断跟踪后续的写操作,直到大小到达DBOptions::max_total_wal_size设定阈值。
如果用户决定把列族"new_cf"的数据落盘,以下的事情会发生:
-
new_cf的数据(key1和key3)会被落盘到一个新的SST文件;
-
一个新的WAL会被创建,现在后续的写操作都会写到新的WAL了;
-
旧的WAL不再接受新的写入,但是删除操作会被延后。
![]()
这时,会有两个WAL文件,旧的保存有从key1到key4的内容,新的保存key5和key6。因为旧的还有线上数据,就是"defalut"列族的,还不能被删除。只有当用户最后决定把"default"列族的数据落盘,旧的WAL才能被归档,然后自动从磁盘上删除。
![]()
![]() 总的来说一个WAL文件会在以下时机被创建:
总的来说一个WAL文件会在以下时机被创建:
一个WAL会在他持有的所有列族的数据的最大请求序列号落盘后被删除(或者归档,如果允许归档),换句话说所有的WAL里的数据都被固定到SST文件。归档WAL会被移到一个独立的位置,然后再从存储设备上清除。实际的删除动作可能会因为拷贝的原因被延后。
1.4 WAL配置
这些配置可以在options.h中找到。
-
DBOptions::wal_dir:用于设置RocksDB存储WAL文件的目录,这允许用户把WAL和实际数据分开存储(云溪数据库默认两者保存在同一个目录);
-
DBOptions::WAL_ttl_seconds,DBOptions::WAL_size_limit_MB:这两个选项影响WAL文件删除的时间。非0参数表示时间和硬盘空间的阈值,超过这个阀值,会触发删除归档的WAL文件(云溪数据库中默认0);
-
DBOptions::max_total_wal_size:如果希望限制WAL的大小,RocksDB使用其作为列族落盘的触发器。一旦WAL超过这个大小,RocksDB会开始强制列族落盘,以保证删除最老的WAL文件。这个配置在列族以不固定频率更新的时候非常有用。如果没有大小限制,如果这个WAL中有一些非常低频更新的列族的数据没有落盘,用户可能会需要保存非常老的WAL文件(云溪数据库中默认0)。
-
DBOptions::avoid_flush_during_recovery:选项名已经说明了他的用途(恢复过程中避免落盘)(云溪数据库中默认false);
-
DBOptions::manual_wal_flush:决定WAL是每次写操作之后自动flush还是纯人工flush(用户必须调用FlushWAL来触发一个WALflush)(云溪数据库中默认false);
-
DBOptions::wal_filter:通过改参数用户可以提供一个在恢复过程中处理WAL文件时被调用的filter对象(云溪数据库中默认Disabled);
-
WriteOptions::disableWAL:如果用户依赖于其他写日志方式,或者不担心数据丢失,该参数就非常有用了(云溪数据库中默认false)。
1.5 WAL过滤器12
事务日志迭代器提供一种方法,用来在RocksDB实例间复制数据。一旦一个WAL因为列族被落盘而被归档,WAL不会马上被删掉。这是为了允许事务日志迭代器可以继续读取WAL文件,再发送给从节点。事务日志迭代器提供一种方法,用来在RocksDB实例间复制数据。一旦一个WAL因为列族被落盘而被归档,WAL不会马上被删掉。这是为了允许事务日志迭代器可以继续读取WAL文件,再发送给从节点。
Part 2 - WAL的实现
2.1 etcd[5]
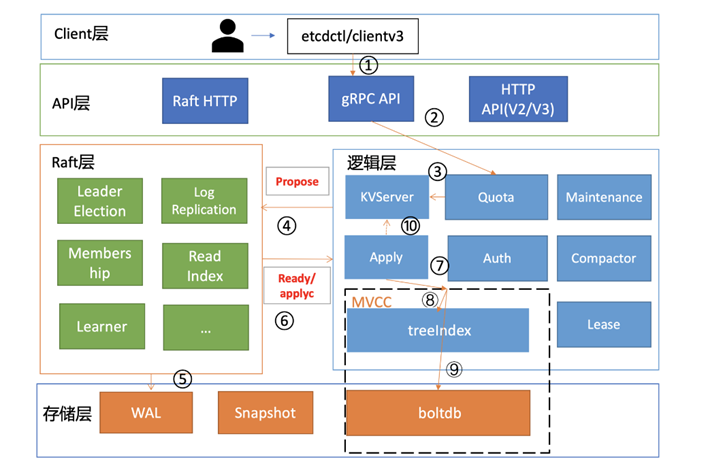
etcd整体架构如下图所示:
![]()
etcd的写请求流程大致可以总结为如下过程:1)首先 client 端通过负载均衡算法选择一个 etcd 节点,发起 gRPC 调用;2)然后 etcd 节点收到请求后经过gRPC 拦截器、Quota模块后,进入 KVServer 模块;3)KVServer 模块向 Raft 模块提交一个提案;4)随后此提案通过 RaftHTTP 网络模块转发集群中各个节点;5)经过集群多数节点持久化后,状态会变成已提交;6)etcdserver 从 Raft 模块获取已提交的日志条目,7)传递给 Apply 模块;8)Apply 模块通过MVCC 模块执行提案内容;9)更新状态机。
在流程5中,Raft 模块收到提案后,如果当前节点是Follower,它会转发给Leader,只有Leader 才能处理写请求。Leader收到提案后,通过Raft 模块输出待转发给Follower 节点的消息和待持久化的日志条目,日志条目则封装了提案内容。etcdserver从 Raft 模块获取到以上消息和日志条目后,作为 Leader,它会将 put 提案消息广播给集群各个节点,同时需要把集群 Leader 任期号、投票信息、已提交索引、提案内容持久化到一个 WAL(Write Ahead Log)日志文件中,用于保证集群的一致性、可恢复性。
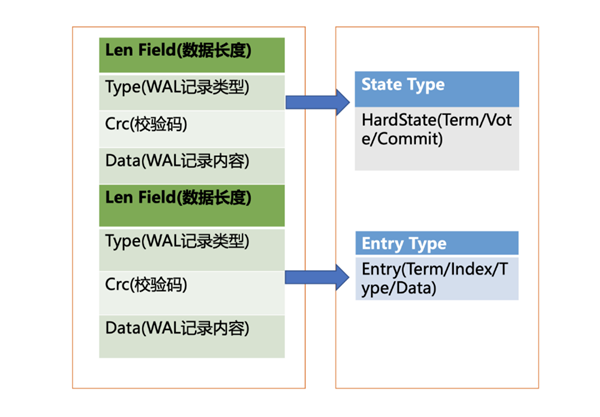
![]()
上图是 WAL 结构,它由多种类型的 WAL 记录顺序追加写入组成,每个记录由类型、数据、循环冗余校验码组成。不同类型的记录通过Type 字段区分,Data为对应记录内容,CRC为循环校验码信息。WAL记录类型目前支持5 种,分别是文件元数据记录、日志条目记录、状态信息记录、CRC 记录、快照记录。文件元数据记录包含节点 ID、集群 ID 信息,它在 WAL 文件创建的时候写入;日志条目记录包含 Raft 日志信息,如 put 提案内容;状态信息记录,包含集群的任期号、节点投票信息等,一个日志文件中会有多条,以最后的记录为准;CRC记录包含上一个 WAL 文件的最后的 CRC(循环冗余校验码)信息,在创建、切割 WAL 文件时,作为第一条记录写入到新的WAL 文件,用于校验数据文件的完整性、准确性等;快照记录包含快照的任期号、日志索引信息,用于检查快照文件的准确性。
WAL模块又是如何持久化一个put 提案的日志条目类型记录呢?首先看看put 写请求如何封装在Raft 日志条目里面。下面是Raft 日志条目的数据结构信息,它由以下字段组成:Term是 Leader 任期号,随着 Leader 选举增加;Index 是日志条目的索引,单调递增增加;Type 是日志类型,比如是普通的命令日志(EntryNormal)还是集群配置变更日志(EntryConfChange);Data 保存述的 put 提案内容。
![]()
了解完 Raft 日志条目数据结构后,再看 WAL 模块如何持久化 Raft 日志条目。它首先将 Raft 日志条目内容(含任期号、索引、提案内容)序列化后保存到 WAL 记录的 Data 字段,然后计算 Data 的CRC 值,设置Type 为Entry Type,以上信息就组成了一个完整的 WAL 记录。最后计算 WAL 记录的长度,顺序先写入 WAL 长度(Len Field),然后写入记录内容,调用 fsync 持久化到磁盘,完成将日志条目保存到持久化存储中。当一半以上节点持久化此日志条目后,Raft 模块就会通过channel 告知etcdserver 模块,put提案已经被集群多数节点确认,提案状态为已提交,可以执行此提案内容了。于是进入流程6,etcdserver 模块从 channel 取出提案内容,添加到先进先出(FIFO)调度队列,随后通过 Apply 模块按入队顺序,异步、依次执行提案内容。
[1] https://zh.wikipedia.org/wiki/%E9%A2%84%E5%86%99%E5%BC%8F%E6%97%A5%E5%BF%97
[2] https://en.wikipedia.org/wiki/Algorithms_for_Recovery_and_Isolation_Exploiting_Semantics
[3] https://en.wikipedia.org/wiki/Journaling_file_system
[4] https://rocksdb.org.cn/doc/Write-Ahead-Log-File-Format.html
[5] https://github.com/etcd-io/etcd/blob/release-3.4/wal/doc.go