小 T 导读:随着业务的发展及数据量的增长,南京津驰选择将 TDengine 社区版搭建在 GPS 服务中,替代原来的 Redis+MySQL+CSV 存储技术方案,以解决查询效率低、数据安全性低、数据占用空间大等问题。本文详细阐述了其在技术选型、数据建模、数据迁移、效果展示等多方面的实践思路与经验汇总。
南京津驰健康科技有限公司是一家专业从事互联网技术服务、计算机软件开发及应用于一体的互联网营销服务的创新型企业。 在竞争激烈的互联网行业中,始终坚持以技术为核心,组建强大的技术开发团队,希望通过发挥我们的专业知识,以客户的利益最大化为目标,为企业提供线上线下全方位的信息技术服务。
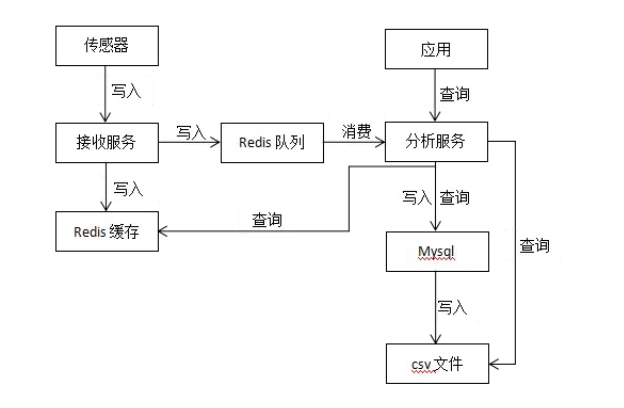
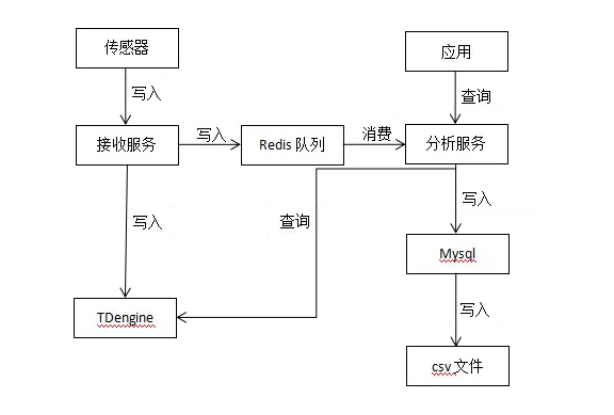
目前我们的 GPS 服务采用的存储技术方案是 Redis + MySQL + CSV,实时数据存储到 Redis 队列,经过服务消费后将原始数据存储到 MySQL,凌晨执行定时任务将前一天 MySQL 中的原始数据存储到 CSV 文件。
当前系统中有 726 台设备,每台设备每秒上传 1 条数据,假设每台设备每年施工 200 天,预计一台设备一年有 60*60*24*200=17,280,000 条数据,那726 台设备就有 726*17,280,000=12,545,280,000 条数据。
随着业务的发展以及数据量的增长,各种问题也逐渐凸显,开始影响工作效率,具体可以归纳为以下几方面:
CSV 是文件存储,在读取数据时只能一个文件一个文件地读取,且需要读取全部数据后再做处理,查询效率比较低。
最终的数据是保存到 CSV 文件中,并且是单文件保存,数据丢失将无法找回。虽然也可以手动保存多份文件,但这将增加运维成本。
数据在 CSV 文件中没有进行任何的压缩技术处理,数据占用硬盘空间比较大。
由于数据既有存储在 MySQL 中的,也有存储在 CSV 文件中的,导致查询数据时得从两个数据源进行查询。且由于 CSV 是文件存储,从中查询数据还需要先从文件中读取数据,也不方便加搜索条件进行数据过滤。
时序数据是指时间序列数据,是按时间顺序记录的数据列,在同一数据列中的各个数据必须是同口径的,要求具有可比性。时序数据可以是时期数,也可以时点数。对以上业务所产生的数据进行分析,完全具备时序数据的特点。基于业务场景的需求,我们决定选择时序数据库作为 GPS 服务平台的核心组件。
时序数据库全称时间序列数据库(Time Series Database),是用于存储和管理时间序列数据的专业化数据库,具备写多读少、冷热分明、高并发写入、无事务要求、海量数据持续写入等特点,支持基于时间区间的聚合分析和高效检索,广泛应用在物联网、经济金融、环境监控、工业制造、农业生产、硬件和软件系统监控等场景。
为了更好地实现业务场景的需求,我们调研了以下几款时序数据库产品:InfluxDB、OpenTSDB 和 TDengine。
-
InfluxDB:单机性能有问题,且集群不开源,未来扩展很成问题,无法令人信任。
-
OpenTSDB:不是独立的服务组件,还要依赖 HBase、HDFS、ZooKeeper,体积庞大,学习成本高,运维困难。
-
TDengine:性能强大,单机就可以扛住我们目前的业务写入量,节约大量成本。且集群开源,通过社群反馈与资料显示可以看到,集群版性能依然稳定,未来扩展方便。
TDengine 的模块之一是时序数据库。但除此之外,为减少研发的复杂度、系统维护的难度,TDengine 还提供缓存、消息队列、订阅、流式计算等功能。与 Hadoop 等典型的大数据平台相比,TDengine 具有如下鲜明的特点:
-
10 倍以上的性能提升:定义了创新的数据存储结构,单核每秒能处理至少 2 万次 请求,插入数百万个数据点,读出一千万以上数据点,比现有通用数据库快十倍以 上。
-
硬件或云服务成本降至 1/5:由于超强性能,计算资源不到通用大数据方案的 1/5;通过列式存储和先进的压缩算法,存储占用不到通用数据库的 1/10。
-
全栈时序数据处理引擎:将数据库、消息队列、缓存、流式计算等功能融为一体, 应用无需再集成 Kafka/Redis/HBase/Spark/HDFS 等软件,大幅降低应用开发和维护的复杂度成本。
-
强大的分析功能:无论是十年前还是一秒钟前的数据,指定时间范围即可查询。数 据可在时间轴上或多个设备上进行聚合。即席查询可通过 Shell、Python、 R、 MATLAB 随时进行。
-
高可用性和水平扩展:通过分布式架构和一致性算法,通过多复制和集群特性, TDengine 确保了高可用性和水平扩展性以支持关键任务应用程序。
-
零运维成本、零学习成本:安装集群简单快捷,无需分库分表,实时备份。类似标 准 SQL,支持 RESTful,支持 Python/Java/C/C++/C#/Go/Node.js, 与 MySQL 相似,零学习成本。
-
核心开源:除了一些辅助功能外,TDengine 的核心是开源的。企业再也不会被数据库绑定了。这使生态更加强大,产品更加稳定,开发者社区更加活跃。
从开源免费、社区活跃、迭代更新、性能高、开销低、支持集群等多方面考虑, TDengine 成为了我们的首选解决方案。
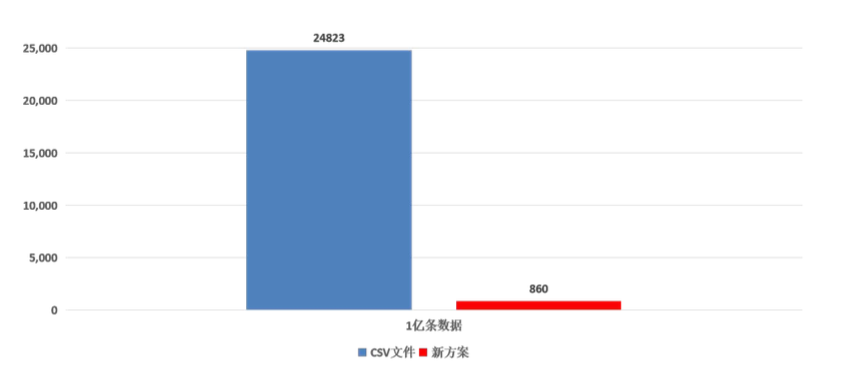
目前,我们使用的是单机。根据建表的数据类型估算,整个服务写入量大约为每秒接近 400M 左右, TDengine 可以轻松抗住这个级别的写入压力,并且压缩率喜人。 1 亿条数据硬盘资源占用对比如下,存储空间降为原方案的 3% ,单位兆:
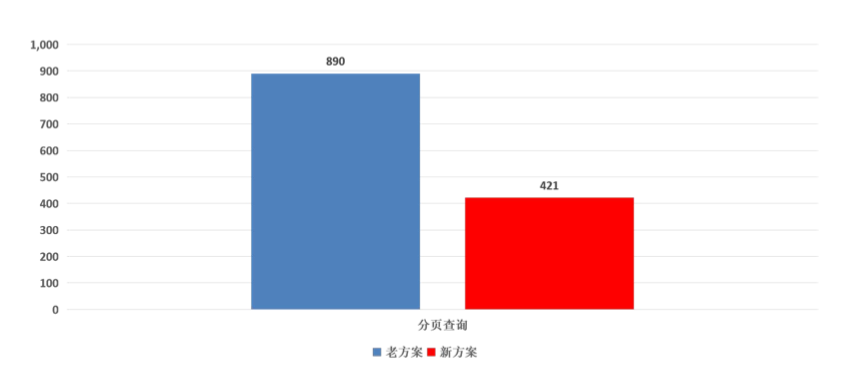
而查询方面也能给出了很优秀的答卷,查询速度提升了两倍多,单位毫秒 :
由于是既有系统的升级改造,必须符合现有系统架构,不能影响现有功能。因此,
数据建模必须限定在一定的范围内,有一定的约束和限制,不像设计一个新系
创建一个名为 gps 的库,这个库的数据将保留 36500 天(超过 36500 天将被自动删除),每 10 天一个数据文件,内存块数为 4,允许更新数据。
CREATE DATABASE gps KEEP 36500 DAYS 10 BLOCKS 4 UPDATE 1;
CREATE TABLE gps_history (gps_time timestamp,sn nchar(20),pile_no int,lon binary(20),lat binary(20),speed float,temperature int,status int,road_float int,data_status int,warn_status int,upload_time timestamp,create_time timestamp,remark nchar(100) ) TAGS (pid nchar(64),bid nchar(64));
insert into gps.gps_10001 using gps.gps_history tags ('10001','10002') values (now,'CY10001',1000,125.91014472833334,45.8548872365,0.01,120,4,1,0,1,now,now,'备注' );
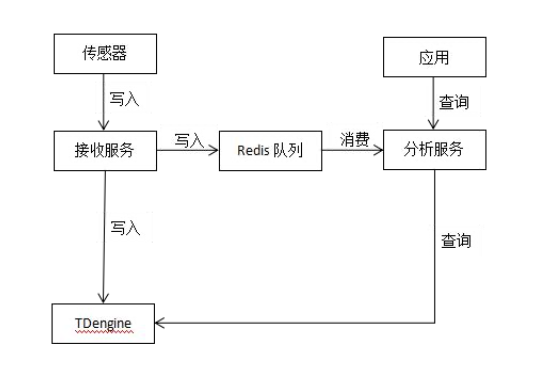
在 GPS 服务平台现有的架构中,有一个数据接收服务专门对外提供时序数据的写入,数据分析服务进行计算并提供查询服务。
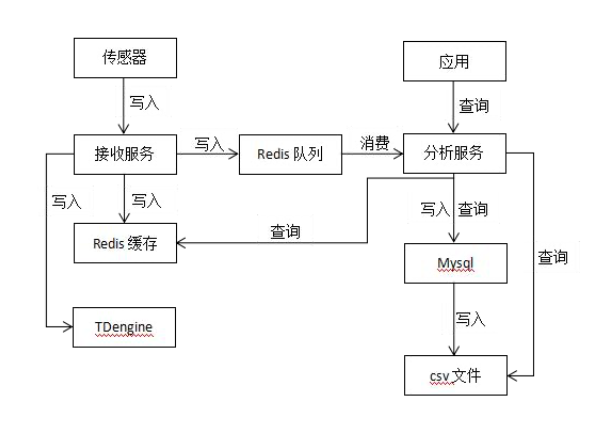
基于上图的架构设计,代码改造工作就变得非常简单。只需要改动数据接收服务的写入、数据分析服务的查询,再在现有基础上增加对 TDengine 的支持,就能将写入和查询两个功能按照 TDengine 的 JDBC 接口进行接口适配,将时序数据的写入和查询切换到 TDengine。
通过这种方式,我们就把 TDengine 的改造迁移屏蔽在了 GPS 服务内部,上层应用无需关心,功能上不受任何影响。
升级改造项目,如何保证历史数据的平滑迁移也是一个重点问题。为此,我们开发了一个数据迁移工具,用于将 CSV 文件中的历史数据平滑迁移到 TDengine。为了确保海量数据的快速迁移,这个工具还进行了持续的性能优化,以及大数据量的压力测试。
将改造后的新版本上线,CSV 文件和 TDengine 并行运行,同时向两个数据库写入数据,由于 CSV 文件有全量数据,查询请求全部交给 Redis 与 CSV 文件;与此同时,启动数据迁移工具,将历史数据迁移到 TDengine,待数据迁移完成后,进入到第二阶段。
CSV 文件和 TDengine 并行运行,也同时向两个数据库写入数据;在数据迁移完全完成后,TDengine 中已经具备全量数据,此时,将查询请求全部切换到 TDengine。观察两周左右的时间,如果没有发现问题,将进入到第三阶段。
经过试运行TDengine 一切正常,功能和性能都没有问题,于是我们将 CSV 文件停止运行,数据只向 TDengine 写入,CSV 文件占用的资源全部回收。
目前,TDengine 社区版已经平稳运行在 GPS 服务中,其作为时序数据库在读写性能、存储表现等方面都是令人满意的。除此之外其在运维难度和学习成本上也是意想不到的低,很轻松就能搭好一套可用的集群,这也是非常巨大的一个优势。另外 TDengine 的版本迭代速度非常快,一些在旧版本遇到的问题很快就得到了修复,并且在性能优化方面效果也是十分显著。后期,我们打算在公司内部的其他物联网产品中继续深入使用。
👇 点击阅读原文,了解体验TDengine!