本文由百度智能云大数据平台技术架构师——李莅在百度开发者沙龙线上分享的演讲内容整理而成。本次分享围绕云原生数据湖架构的价值展开,深度数据湖计算和统一元数据的技术架构。希望开发者能够通过本文对一站式大数据处理平台构建有初步认识。
文:李莅
视频回放:https://developer.baidu.com/live.html?id=14
本次分享的主题是:数据湖架构下的大规模数据处理技术实践。内容主要分为以下4个方面:
-
背景介绍
-
大数据基础建设
-
数据湖数仓建设
-
一站式开发平台
01背景介绍
什么是数据湖
数据湖的概念最早出现在2010年 ,此时数据湖是一个集中式的存储系统,流入任意规模的结构化和非结构化的数据。但这些还是在关注它存储的相关特性。
随着对象存储(BOS)解决了海量数据和低成本存储问题,用户更关注挖掘湖中数据的价值。数据湖的重点从存储转向数据的计算分析,核心在于强化数据分析的能力。
2017年随着AI 的兴起,深度学习使用大数据处理海量的训练数据输入。借助数据湖架构,可以更好地打通数据之间的壁垒,支撑AI 模型的训练、推理以及数据的预处理。
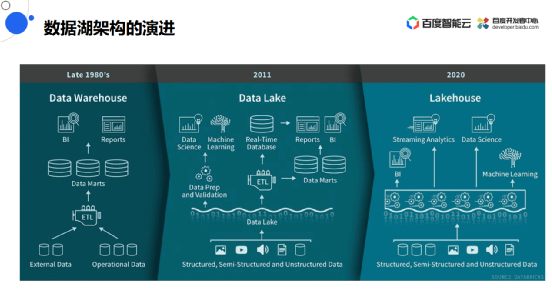
数据化架构的演进
![]()
-
第一个阶段在1980年,当时还是传统的数仓形式:用户把关系型数据库的内容采集下来,通过ETL存储到专门的分析型数据库中,然后在上层提供BI、报表类的服务。
-
第二个阶段在2011年,此时开始引入数据湖的概念:源端的类型也变为更多结构化的数据和非结构化的数据,包括音频和视频等等,然后把这些数据全部都存到数据湖里。
接下来会按照两种情况处理:第一种通过数据预处理之后为数据科学或机器学习提供训练的数据输入。第二种通过传统的ETL处理,存到分析型数据库或实时数据库里用来提供传统的报表或BI分析。
-
第三个阶段在2020年,此时提出湖仓一体的概念,称为Lakehouse。底层数据保持不变,但是使用一个数据湖来对接上层所有应用,其中没有相关的分析型数据库或实时数据库或数据预处理机制,数据湖可以直接对接BI、报表、训练、数据科学、流式分析等分析类的场景。
大数据项目实例
![]()
以一个实际的大数据项目为例来介绍一下如何在大规模数据的背景下建设一个数据湖的数仓。
客户的场景主要分为这四方面的内容。
面临新的挑战
在这个背景下会遇到一些新的挑战。
-
首先客户的数据量指数级地增加的,客户很期望在数据量暴增的同时改善存储的成本并且提高计算能力。
-
其次客户的业务发展之后, 数据类型更加多样 ,原来可能以关系型数据库为主,后来增加了很多很难直接进行分析和计算的数据库,用户也希望能够统一管理。
-
最后,消费数据的 应用类型更加复杂 ,带来更大的并发访问量,wokload和性能期望是复杂多样的。比如有的客户期望毫秒级的延迟,也有的客户期望小时级但是数据吞吐量特别大。
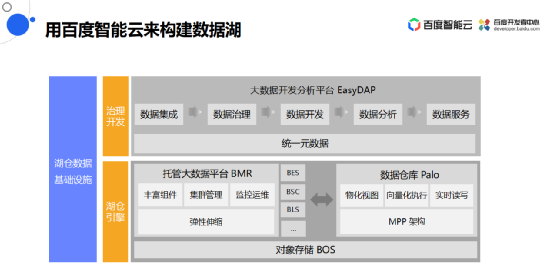
用百度智能云来构建数据湖
![]()
使用百度智能运来构建数据湖,这是提供的一个数据湖仓解决方案。
其中最底层是湖仓引擎层,它的核心设计有三个产品:
上层提供一个治理开发平台——大数据开发分析平台EasyDAP。
02大数据基础设施建设
网络规划
首先对客户做一个网络规划,其中VPC划分是最重点需要考虑的,一般有以下几个内容:
-
在线业务VPC
-
离线业务VPC
-
研发测试VPC
-
考虑部门等组织结构状况进行更细致的VPC划分
-
VPC之间网络隔离,保证互不影响和安全性
有些情况是需要跨VPC去传输数据的,通常会有两种方式去解决:
1)先将数据导入到公共服务比如Kafka或者BOS上,通过中间服务来上传和下载数据, 公共服务保证各VPC可以访问。
2)VPC如果紧密联系也可以通过网络专线来打通。
计算集群规划
接下来对客户的计算集群做规划,这里使用BMR去快速创建集群。主要考虑以三个方面。
1. 按业务划分,独立使用。
2. 不同集群之间是强物理隔离。
3. 便于审计资源消耗。
1. 主节点,数量比较少,主要是存元数据和管控。
2. 核心节点,通常是用来存HDFS,所以希望它保持稳定。
3. 任务节点,可以进行弹性扩缩容。
还可以为不同类型可设置不同规格硬件,以满足业务需要,
1. 通用型,1:4。
2. 计算型,1:2。
3. 内存型,1:8。
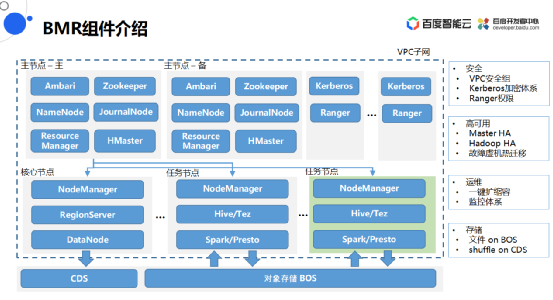
BMR组件介绍
![]()
BMR主节点部署的是传统的Hadoop各种元数据服务,比如NameNode、JournalNode、Zookeeper、ResourceManager等。
核心节点主要是部署如DataNode、HBase的RegionServer这种存储服务,同时也会混合布置一些NodeManager,以充分利用计算资源。
任务节点主要是部署NodeManager,同时也会有一些计算的组件比如像Hive中的Tes,Spark中的Presto。
集群中的存储主要使用CDS,数据会存储到BOS中。
计算存储分离
整体架构主要考虑计算和存储分离的思路,来减少计算对存储的依赖,提高集群的弹性,以便获得更高的性价比来降低运营的成本。计算存储分离主要做以下三件事情。
-
第一件是BOS替代HDFS,这里面主要是把很多非结构化文件存到BOS中,核心离线数仓Hive也存到BOS中,针对HBase改造它的底层把其中Hfile也存到BOS中。
-
第二件是使用自动扩缩容机制,通过前面的存储让核心节点数量最小化,按需扩容任务节点,任务完成后通过自动策略机制及时释放,可使用相对稳定性差但成本更低的竞价实例。
-
第三件是存储管理使用对象存储数据生命周期管理机制,短期临时的数据进行自动TTL清理,对长期存储的数据进行存储冷热分级,冷数据能够自动下沉到更低成本的介质中。
为什么选择对象存储
大数据场景数据是日积月累的,所以存储通常要考虑三个方面:
BOS在存储弹性、存储成本、存储管理这三个方面都远胜过HDFS。
-
在存储弹性方面,BOS是按量付费的,存储空间几乎无限,而HDFS需要规划机型大小,扩缩容成本高,相比之下对象存储就简单很多。
-
在存储成本方面,BOS通过EC编码技术和规模效应,单GB成本低,而性能优秀。冷数据可以专门归档存储,可以存到像磁带、蓝光这样的介质中来进一步获得更低的成本。
-
在存储管理方面,BOS的存储管理功能齐全。可以按业务划分若干Bucket,易于管理权限。配置生命周期规则等自动管理规则。拥有监控报表,工具齐全,便于分析审计使用情况。
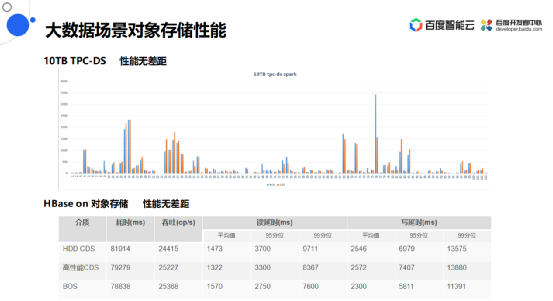
大数据场景下对象存储性能
![]()
使用两种方法对比了大数据场景下对象存储性能。
大数据组件适配对象存储
大数据组件适配对象存储的时候做了以下的改造工作:
-
首先适配Hadoop接口其中包括FileSystem接口和AbstractFileSystem接口
保证在路径写法上兼容,之前Hadoop生态里面能直接使用HDFS的路径一般能使用BOS。
-
其次在BOS数据读写上使用BOS的分块并发上传来提高性能
这样做不占用本地缓存直接写入BOS,保证文件传完才可见,这样能够避免存储一些脏数据,确保了操作的原子性。
-
元数据,BOS相比于其他友商的好处就是单个文件可以保证强一致性,同时还能支持rename。使用List对象名的前缀来实现,如果目录层级很深,在高层级做ls的时候性能较差。但是目录rename不是原子操作,其底层遍历整个目录,然后递归,并发rename每个对象,内部重试尽可能达到最终一致。
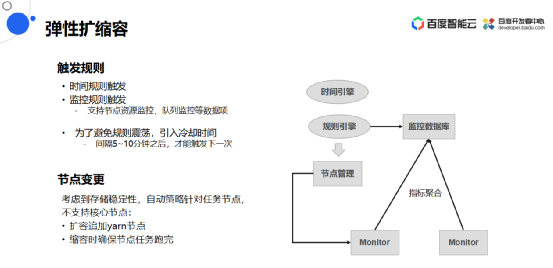
弹性扩容
![]()
应用BOS之后可以进行弹性扩缩容,例如图的右侧,从底层采集集群的指标,聚合之后存到监控数据库,然后规则引擎会不断去分析规则数据库中的指标数据,最后应用各种用户配置的数据规则和策略对节点进行扩缩容管理。
规则引擎分为两种,一种是时间触发规则,还有一种是监控触发规则,监控规则触发支持节点的资源监控比如CPU或者Hadoop集群队列的监控,然后为了避免规则引起的震荡引入冷却时间的机制,一般来说每条规则触发5-10分钟之后才会触发下一条规则。
然后在进行节点变更时,考虑到存储的稳定性,自动策略不会触发到核心节点的自动扩缩容,主要是针对任务节点,任务节点在扩容的时候会去购买虚机,然后部署yarn服务,然后自动把作业给调度上去,缩容的时候可以确保节点作业任务跑完,不让新的节点调度上去,最后作业跑完之后才会释放这个节点。
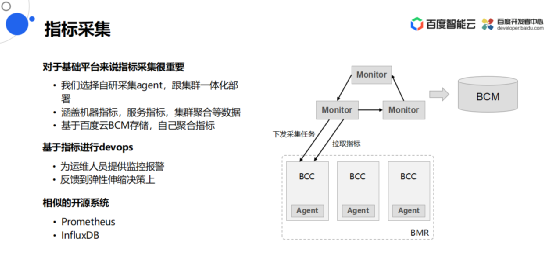
指标采集
![]()
自动扩缩容是非常依赖指标采集,这里设计了一套自动采集的系统,它会把Agent部署到每一台BMR里面的虚机上,并跟集群保持一体化部署,然后采集的指标涵盖机器指标、服务指标、集群聚合等各种集群级的指标,最后下发采集任务之后拉取指标数据,并且把这些存到百度云的监控云存储里面。
之后其他的地方就能基于这些指标进行devops的操作,为运维人员和客户提供监控报警,同时也可以反馈到弹性伸缩扩容决策上。
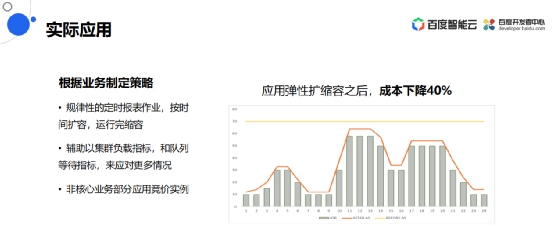
实际应用
![]()
存算分离整体应用到具体的业务场景上,需要根据业务制定一些策略比如
整体应用弹性扩缩容之后,成本下降40%。
03数据湖仓建设
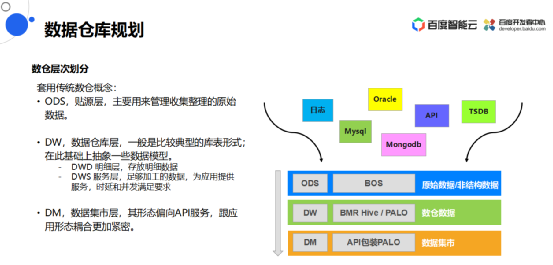
数据仓库规划
![]()
首先对客户的数据仓库做一个规划,这里套用一些传统的数仓概念,基本上分为三层:
1. uDWD 明细层,存放明细数据。
2. uDWS 服务层,足够加工的数据,为应用提供服务,保证时延和并发满足要求。
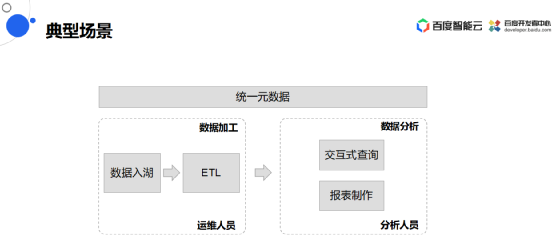
典型场景
![]()
典型的应用场景就在统一元数据的框架下都是一套库表的结构,大概分为两种人员,一种是运维人员,一种是分析人员。
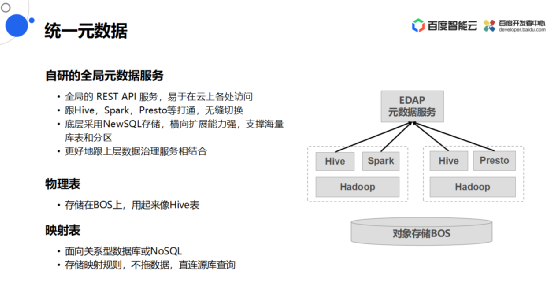
统一元数据
![]()
在这个场景下,我们为数据提供统一的元数据服务。
这是自研的一套全局元数据服务,其中提供全局的 REST API 服务,非常方便在云上各处访问而不受网络的限制,它的底层跟Hive,Spark,Presto等打通,相比于原来的Hive元数据可以做到无缝切换,存储底层采用NewSQL存储,横向扩展能力强,支撑海量库表和分区。有了这样一套统一的元数据之后可以更好地跟上层数据治理服务相结合。
统一元数据里面主要分为两种表结构,一种是物理表,跟hive表差不多,它的数据存在对象存储上,用起来也像Hive。另一种是映射表,通常是面向关系型数据库或者NoSQL,只存储映射规则不存储数据,通过SQL查询的时候底层直接连源库去查询。
访问控制
![]()
在统一元数据的基础之上,还根据客户的需求制定了访问控制的机制,因为客户要对不同人员做细粒度权限的管控和审计,这里实现了行列权限,实现的思路是:
此外还提供数据脱敏机制,将用户密级和数据密级进行定义(L0~L5),用户只能访问对应密级的数据。
如果用户要访问比他高的数据就需要进行脱敏访问,脱敏访问分为两种:
入湖分析&联邦分析
数据湖分析首先要分析湖里的数据,但是很多用户通常有一些存量的数据不想入湖,比如以前购买的传统数仓中的集群,但是业务上又希望能够把这些数据跟数据湖里的数据一起分析。这里引入一个联邦分析的概念,一般通过映射规则将数据源注册成库表形式,然后底下引擎运行SQL时直接查询数据源,这种情况跟入湖一样同时支持丰富的数据源访问能力。
联邦分析的 优势 有以下几个方面:
联邦分析的 劣势 有以下几个方面:
-
对数据源有直接的访问压力,需要谨慎规划。
-
性能依赖源库的计算能力,和算子谓词下推的能力。
数据入湖
![]()
数据入湖分为两种。
一种是 批量入湖 ,通常都是定时作业的形式,直接扫描源库,写入数据湖存储,批量作业通常都是整库迁移的场景,所以要根据数据图表结构生成很多批量作业来进行合理的调度来让它整体运行起来,在这个过程之中也支持Spark算子进行数据清洗。
另一种 实时入湖 ,通过数据传输服务DTS,使用CDC技术采集MySQL、Oracle、SQLServer这些关系型数据库的增量日志,然后把这些日志实时写入Kafka,实时写入到数据湖的库表里面,通常还会定期将增量日志合入全量表。
湖仓一体
在入湖的时候会遇到一些问题:
-
传统入湖,需要校验避免引入脏数据,管理成本高,性能差。
-
实时入湖需要 T+1 merge,数据不能及时可见。
-
传统数据库的格式的分区管理在对象存储上性能差,因为它依赖数据存储的各种元数据的管理。
这样我们就引入了湖仓一体的技术,首先采用湖仓一体的存储格式Iceberg能够带来以下几方面的好处:
-
支持ACID事务(支持insert,update,delete),避免引入脏数据。
-
对象存储友好,因为它有一个清单文件去管理里面的文件,所以避免list,rename等降低对BOS元数据的依赖。
-
同时支持Merge on read 实现实时可见。
-
还能通过统一元数据,统一查询入口,多场景工作负载(ad-hoc,报表等)性能优化,保证性能和统一的访问体验,性能优化主要有两方面:
-
自研存储缓存系统,通过缓存去加速对对象存储上面数据的访问。
-
对存储格式进行优化,引入了SortKey机制,访问特定模式时可以获得更好的性能。
统一数据湖分析
在统一元数据的基础上,基于Trino的引擎去做改造,从而实现了统一的数据湖分析,实现了自研的数据湖分析引擎。
通过统一元数据,将底层Hive表、PALO表和源库都包装成统一的视图形成统一的查询入口,然后使用Presto SQL进行分析,降低各种SQL的学习成本,然后通过配套的数据资产快速检索,找到用户想去查询的库表信息,这样就给统一数据湖分析带来一些好处。
其中实现了以下几个方面的核心能力:
04一站式开发平台
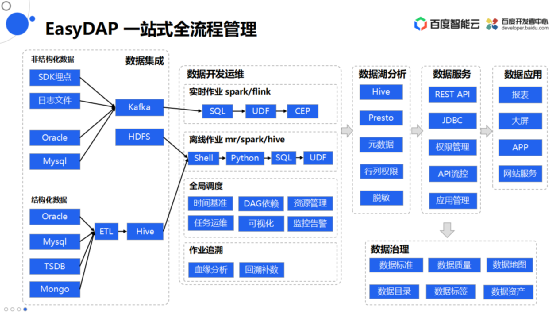
EasyDAP 一站式全流程管理
![]()
EasyDAP一站式开发平台主要涵盖以下几个功能板块,
-
数据集成。
-
数据开发运维。
-
数据湖分析。
-
数据服务。
-
数据应用。
-
数据治理。
这个平台可以将前面所有介绍到的大数据开发操作都界面化,然后在同一个平台上去操作完成。
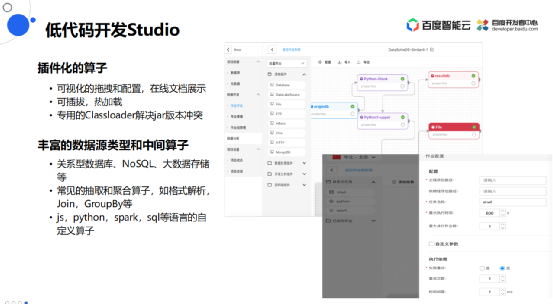
低代码开发Studio
![]()
这个平台提供低代码的开发studio,通过插件化的算子,可以在画布上进行可视化的拖拽和配置,是以节点的形式把线连起来去构建数据流,同时还有在线文档展示。它是可插拔和热加载的,还有专用的Classloader解决jar版本冲突。
支持丰富的数据源类型和中间算子:
作业调度
![]()
作业调度,主要抽象了三种作业依赖形式:
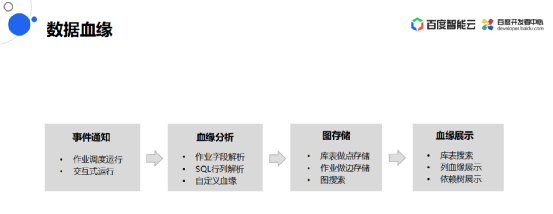
数据血缘
![]()
在平台上构建的作业也为其提供数据血缘的服务,作业运行的时候通过作业调度或者用户交互式运行会触发时间通知。
数据血缘分析模块收到通知之后就会分析作业字段的解析,SQL行列的解析,用户自己标识的血缘信息也可以提取出来。
基于这些血缘分析的信息,把库表作位点存储,把运行的作业作位边存储,这样可以构建一个血缘关系图,然后存到图数据库里面,可以基于此进行搜索。
最后通过界面把这些血缘关系展示出来,可以在界面上去搜索库表,然后展示以库表为中心的血缘(可以支持到列的粒度),也支持整颗依赖树的展示。
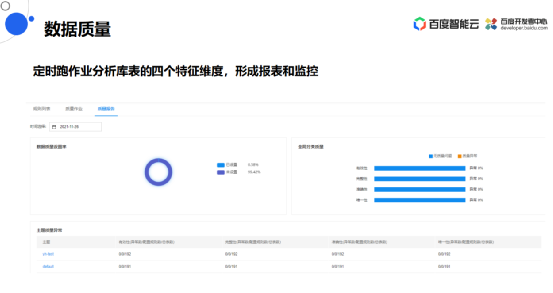
数据质量
![]()
数据作业还提供数据质量图,我们给库表去配置一些质量相关的算子,这样用户可以定时去跑作业分析库表的四个特征维度,然后根据这四个特征维度去形成对应的质量报表和监控数据。
以上是老师的全部分享内容,有问题欢迎在评论区提出。
往期推荐
🔗
可视化神器背后的奥秘
6000字,详解数据仓库明星产品背后的技术奥秘
扫描二维码,备注:大数据开发,立即加入大数据产品&技术交流群。
![]()