摘要:采用多主实例模式的HA方案,不仅可以规避主备切换服务中断的问题,实现服务不中断或少中断,还可以通过横向扩展集群来提高并发能力。
本文分享自华为云社区《FusionInsight Spark支持JDBCServer的多实例特性介绍》,作者: 一枚核桃。
基于社区已有的JDBCServer基础上,采用多主实例模式实现了其高可用性方案。集群中支持同时共存多个JDBCServer服务,通过客户端可以随机连接其中的任意一个服务进行业务操作。即使集群中一个或多个JDBCServer服务停止工作,也不影响用户通过同一个客户端接口连接其他正常的JDBCServer服务。
多主实例模式相比主备模式的HA方案,优势主要体现在对以下两种场景的改进。
- 主备模式下,当发生主备切换时,会存在一段时间内服务不可用,该时间JDBCServer无法控制,取决于Yarn服务的资源情况。
- Spark中通过类似于HiveServer2的Thrift JDBC提供服务,用户通过Beeline以及JDBC接口访问。因此JDBCServer集群的处理能力取决于主Server的单点能力,可扩展性不够。
采用多主实例模式的HA方案,不仅可以规避主备切换服务中断的问题,实现服务不中断或少中断,还可以通过横向扩展集群来提高并发能力。
实现方案
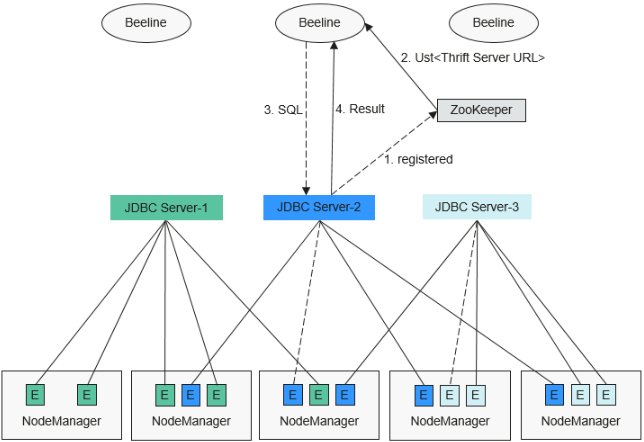
多主实例模式的HA方案原理如下图所示。
![]()
1、JDBCServer在启动时,向ZooKeeper注册自身消息,在指定目录中写入节点,节点包含了该实例对应的IP,端口,版本号和序列号等信息(多节点信息之间以逗号隔开)。
示例如下:
[serverUri=192.168.169.84:22550;version=8.1.2;sequence=0000001244,serverUri=192.168.195.232:22550 ;version=8.1.2;sequence=0000001242,serverUri=192.168.81.37:22550 ;version=8.1.2;sequence=0000001243]
2、客户端连接JDBCServer时,需要指定Namespace,即访问ZooKeeper哪个目录下的JDBCServer实例。在连接的时候,会从Namespace下随机选择一个实例连接,详细URL参见URL连接介绍。
3、客户端成功连接JDBCServer服务后,向JDBCServer服务发送SQL语句。
4、JDBCServer服务执行客户端发送的SQL语句后,将结果返回给客户端。
在HA方案中,每个JDBCServer服务(即实例)都是独立且等同的,当其中一个实例在升级或者业务中断时,其他的实例也能接受客户端的连接请求。
多主实例方案遵循以下规则:
- 当一个实例异常退出时,其他实例不会接管此实例上的会话,也不会接管此实例上运行的业务。
- 当JDBCServer进程停止时,删除在ZooKeeper上的相应节点。
- 由于客户端选择服务端的策略是随机的,可能会出现会话随机分配不均匀的情况,进而可能引起实例间的负载不均衡。
- 实例进入维护模式(即进入此模式后不再接受新的客户端连接)后,当达到退服超时时间,仍在此实例上运行的业务有可能会发生失败。
URL连接介绍
多主实例模式
多主实例模式的客户端读取ZooKeeper节点中的内容,连接对应的JDBCServer服务。连接字符串为:
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;
说明:
-
-
- 其中“<zkNode_IP>:<zkNode_Port>”是ZooKeeper的URL,多个URL以逗号隔开。
例如:“192.168.81.37:24002,192.168.195.232:24002,192.168.169.84:24002”。
-
-
- 其中“sparkthriftserver2x”是ZooKeeper上的目录,表示客户端从该目录下随机选择JDBCServer实例进行连接。
示例:安全模式下通过Beeline客户端连接时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;"
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;user.principal=<principal_name>;user.keytab=<path_to_keytab>
其中<principal_name>表示用户使用的Kerberos用户的principal,如“test@<系统域名>”。<path_to_keytab>表示<principal_name>对应的keytab文件路径,如“/opt/auth/test/user.keytab”。
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;
示例:普通模式下通过Beeline客户端连接时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;"
非多主实例模式
非多主实例模式的客户端连接的是某个指定JDBCServer节点。该模式的连接字符串相比多主实例模式的去掉关于Zookeeper的参数项“serviceDiscoveryMode”和“zooKeeperNamespace”。
示例:安全模式下通过Beeline客户端连接非多主实例模式时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<server_IP>:<server_Port>/;user.principal=spark2x/hadoop.<系统域名>@<系统域名>;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;"
说明
- 其中“<server_IP>:<server_Port>”是指定JDBCServer节点的URL。
- “CLIENT_HOME”是指客户端路径。
多主实例模式与非多主实例模式两种模式的JDBCServer接口相比,除连接方式不同外其他使用方法相同。由于Spark JDBCServer是Hive中的HiveServer2的另外一个实现,具体使用方法,请参见Hive官网:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients。
点击关注,第一时间了解华为云新鲜技术~