摘要:采用Redis Labs推出的多线程压测工具memtier_benchmark对比测试下GaussDB(for Redis) 和原生Redis的特性差异。
本文分享自华为云社区《华为云企业级Redis评测第一期:稳定性与扩容表现》,作者:GaussDB 数据库 。
GaussDB(for Redis) 是华为云推出的企业级Redis,采用计算存储分离架构,兼容Redis生态的云原生NoSQL数据库,基于共享存储池的多副本强一致机制,支持持久化存储,保证数据的安全可靠。具有高兼容、高性价比、高可靠、弹性伸缩、高可用、无损扩容等特点。GaussDB(for Redis)满足高读写性能场景及容量需弹性扩展的业务需求,广泛使用于电商、游戏以及视频直播等行业。即可作为前端缓存支撑大并发的访问,也可作为底层数据库负责核心数据可靠存储。
接下来我们使用采用Redis Labs推出的多线程压测工具memtier_benchmark对比测试下GaussDB(for Redis) 和原生Redis的特性差异。
1、创建GaussDB(for Redis)实例
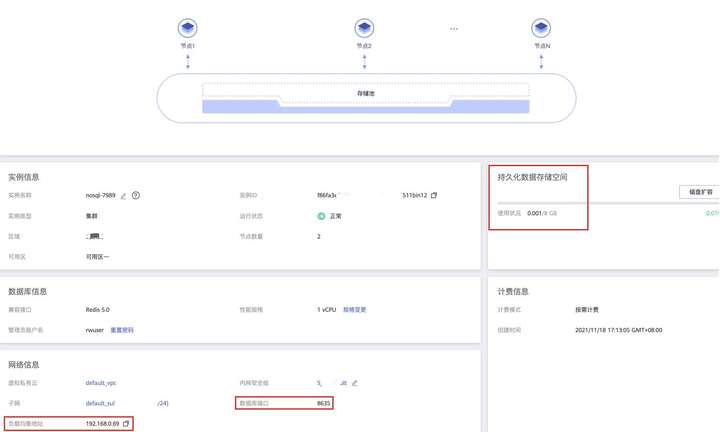
在华为云通过控制台购买GaussDB(for Redis)实例,测试实例的配置为8G容量,如下所示。
![]()
如截图所示,GaussDB(for Redis)提供了统一的负载均衡地址和端口,方便应用程序访问高可用的Redis服务。持久化数据存储空间直观展示了数据量及容量上限。另外,依托于GaussDB(for Redis)存算分离的架构,实例的容量和性能可以按需分别扩展:
- 如需更多容量,只需点击“磁盘扩容”;
- 如需更高的吞吐性能,则通过“规格变更”或“添加节点”完成。
2、安装memtier_benchmark
使用与GaussDB(for Redis)测试实例相同子网的ECS云服务器,部署memtier_benchmark测试环境
# yum install autoconf automake make gcc-c++
# yum install pcre-devel zlib-devel libmemcached-devel openssl-devel
# git clone https://github.com/RedisLabs/memtier_benchmark.git
# cd memtier_benchmark
# autoreconf -ivf
# ./configure
# make && make install
如libevent版本较低,需要在安装memtier_benchmark前 按以下步骤安装libevent
# wget https://github.com/downloads/libevent/libevent/libevent-2.0.21-stable.tar.gz
# tar xfz libevent-2.0.21-stable.tar.gz
# pushd libevent-2.0.21-stable
# ./configure
# make
# sudo make install
# popd
# export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:${PKG_CONFIG_PATH}
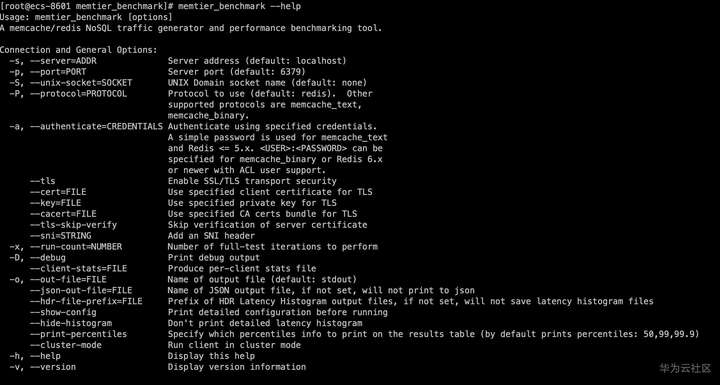
确认安装成功
# memtier_benchmark --help
![]()
3、数据批量装载
向GaussDB(for Redis) 中装载数据
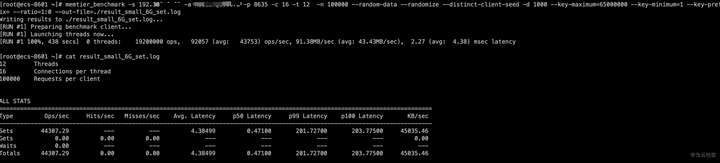
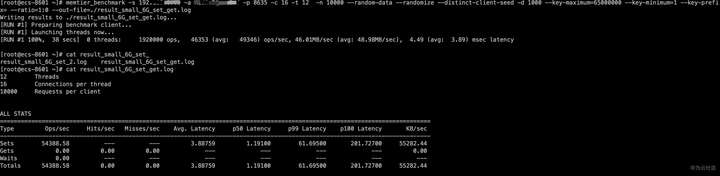
使用memtier_benchmark向GaussDB(for Redis) 中装载数据命令如下,单个value长度1000字节,12个线程,每个线程16个客户端,每个客户端发出请求数100000个,全部是写入操作。
memtier_benchmark -s 192.XXX.XXX.XXX -a XXXXXXX -p 8635 -c 16 -t 12 -n 100000 --random-data --randomize --distinct-client-seed -d 1000 --key-maximum=65000000 --key-minimum=1 --key-prefix= --ratio=1:0 --out-file=./result_small_6G_set.log
可以看到执行了1920万次操作,平均每秒4.4w的ops,总耗时438秒。
![]()
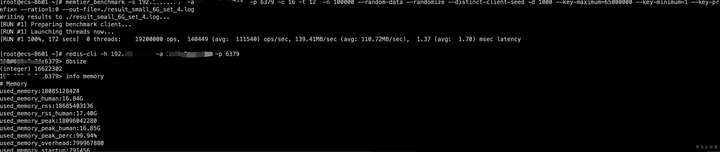
使用redis-cli登录实例,查看dbsize(注意:由于采用MVCC机制,查询结果为key数量的预估值,非实时的准确值。)
![]()
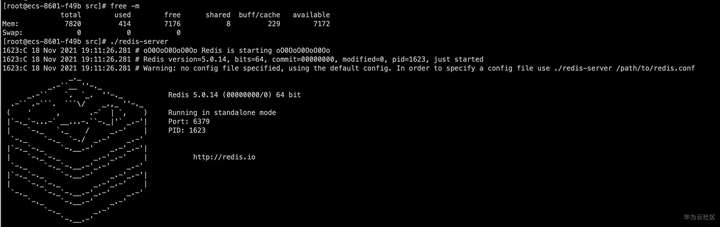
向原生Redis中装载数据
为了对比方便,我们在另一台4核8G的ECS上部署一个单节点的开源Redis,版本与GaussDB(for Redis)一致使用5.0
![]()
还是使用memtier_benchmark相同的配置向原始redis中插入数据
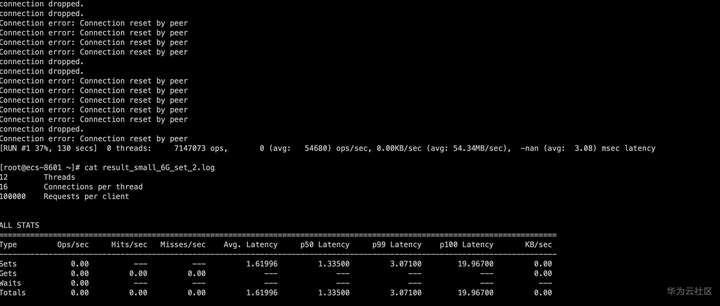
memtier_benchmark -s 192.XXX.XXX.XXX -a XXXXXXX -p 6379 -c 16 -t 12 -n 100000 --random-data --randomize --distinct-client-seed -d 1000 --key-maximum=65000000 --key-minimum=1 --key-prefix= --ratio=1:0 --out-file=./result_small_6G_set_2.log
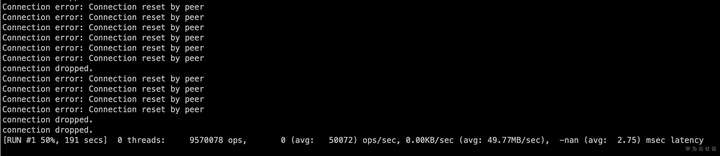
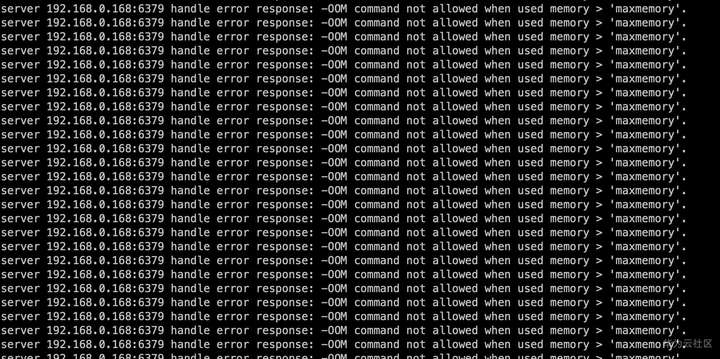
执行一段时间后出现大量报错
![]()
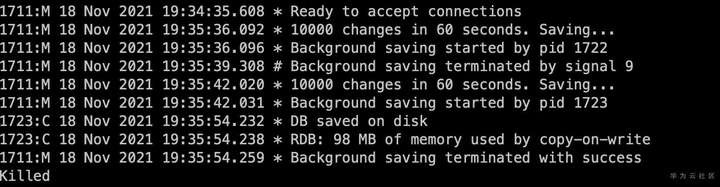
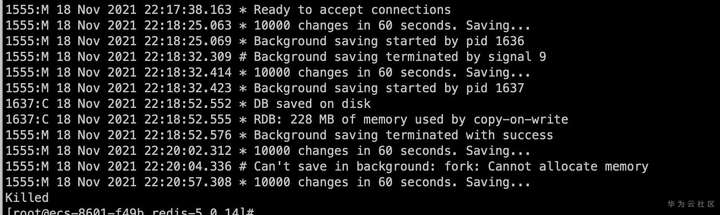
从Redis日志中查看,是在做RDB快照的时候出现了问题。从系统日志中分析当时发生了OOM故障。
![]()
![]()
这其实和原生Redis的RDB快照处理方式有关,Redis是fork了一个进程使用copy-on-write的方式持久化内存数据,这必然会导致更多内存的申请和使用。并且除了RDB快照,原生redis在执行aof重写,新加从库的操作时也会申请使用更多的内存。为了避免OOM的情况出现,操作系统往往要预留出一倍的空闲内存,限制了内存资源的使用率造成极大的浪费。
反观GaussDB(for Redis) 由于摒弃了fork机制,使得架构更健壮。从上面的测试也可以看到,导入同样数量的数据时,GaussDB(for Redis) 的可用性和响应的性能没有受到任何的影响。
4、实例紧急扩容
为了测试能进行下去,我们将GaussDB(for Redis) 和原生Redis分别扩容到16G。
GaussDB(for Redis)扩容到16G
对GaussDB(for Redis) 来说由于采用了存算分离的架构,分布式存储池海量在线,按额度分配给用户使用。扩容过程没有数据拷贝,也不会影响业务使用。接下来我们测试使用memtier_benchmark在持续的RW操作场景下GaussDB(for Redis)的扩容过程,看看是否会影响业务的读写;
memtier_benchmark -s 192.XXX.XXX.XXX -a XXXXXXXX -p 8635 -c 16 -t 12 -n 10000 --random-data --randomize --distinct-client-seed -d 1000 --key-maximum=65000000 --key-minimum=1 --key-prefix= --ratio=1:0 --out-file=./result_small_6G_set_get.log
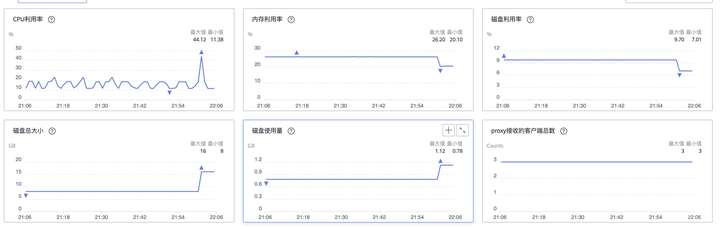
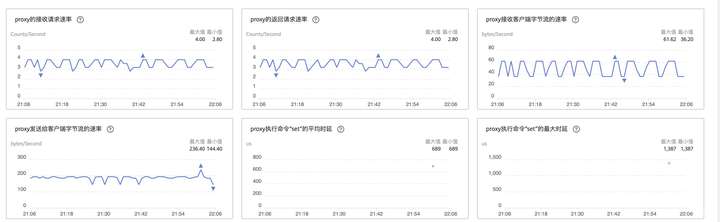
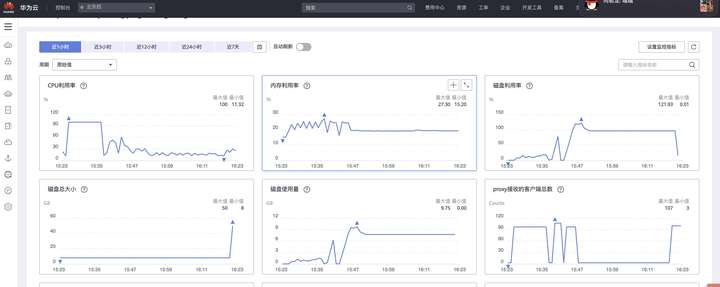
在执行命令的同时进行扩容操作,查看测试结果和监控发现,扩容期间未见报错,GaussDB(for Redis) 响应时延没有明显变化。
![]()
![]()
![]()
原生Redis扩容到16G
原生Redis实例受服务器内存限制,要扩容到16G只能先升级ECS配置。需要重启服务器,存在短时间业务不可使用的问题。升级后再次使用memtier_benchmark插入数据依旧报错,检查发现还是出现了OOM
![]()
![]()
![]()
没办法,只能再次升级云服务器ECS配置到32G,升级期间Redis服务再次不可用。这次升级后终于使用memtier_benchmark成功的插入了数据。
![]()
5、数据淘汰问题
下面我们来看高压力下导致数据写满的场景,直观对比双方的表现。
插入数据到GaussDB(for Redis)
memtier_benchmark参数设置如下,全部为写入操作,set的单个value长度50k字节,12个线程,每个线程16个客户端,每个客户端发出请求数10000次请求。折算下来 总的插入的key约为192万,数据量约96G,远大于实例的规格了。
memtier_benchmark -s 192.XXX.XXX.XXX -a XXXXXXX -p 8635 -c 16 -t 12 -n 10000 --random-data --randomize --distinct-client-seed -d 50000 --key-maximum=65000000 --key-minimum=1 --key-prefix= --ratio=1:0 --out-file=./result_small_6G_set.log
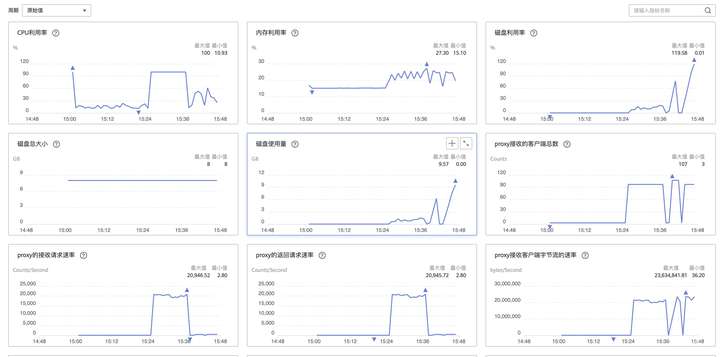
运行了一段时间后,从监控上看到GaussDB(for Redis)磁盘空间100%,并且实例进入只读模式拒绝新数据的写入。检查发现共导入数据194954条。
![]()
![]()
![]()
![]()
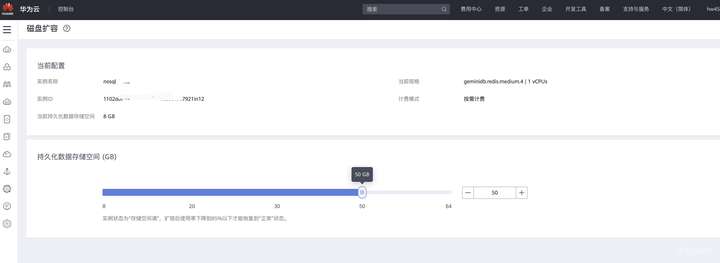
对于GaussDB(for Redis)来说,当容量接近写满的时候,用户会收到告警通知,此时只需在控制台点击“磁盘扩容”,即可秒级完成扩容,对业务没有影响。
![]()
![]()
![]()
插入数据到原生Redis
原生Redis通过配置限制了内存大小为8G,同样执行以下命令导入数据
memtier_benchmark -s 192.XXX.XXX.XXX -a XXXXXXX -p 8635 -c 16 -t 12 -n 10000 --random-data --randomize --distinct-client-seed -d 50000 --key-maximum=65000000 --key-minimum=1 --key-prefix= --ratio=1:0 --out-file=./result_small_6G_set.log
运行一段时间后报错。
![]()
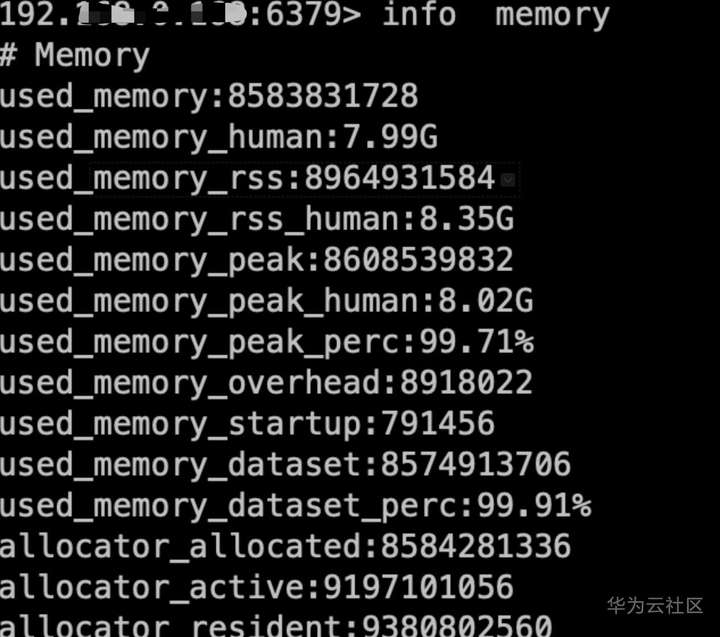
登录redis查看内存已写满
![]()
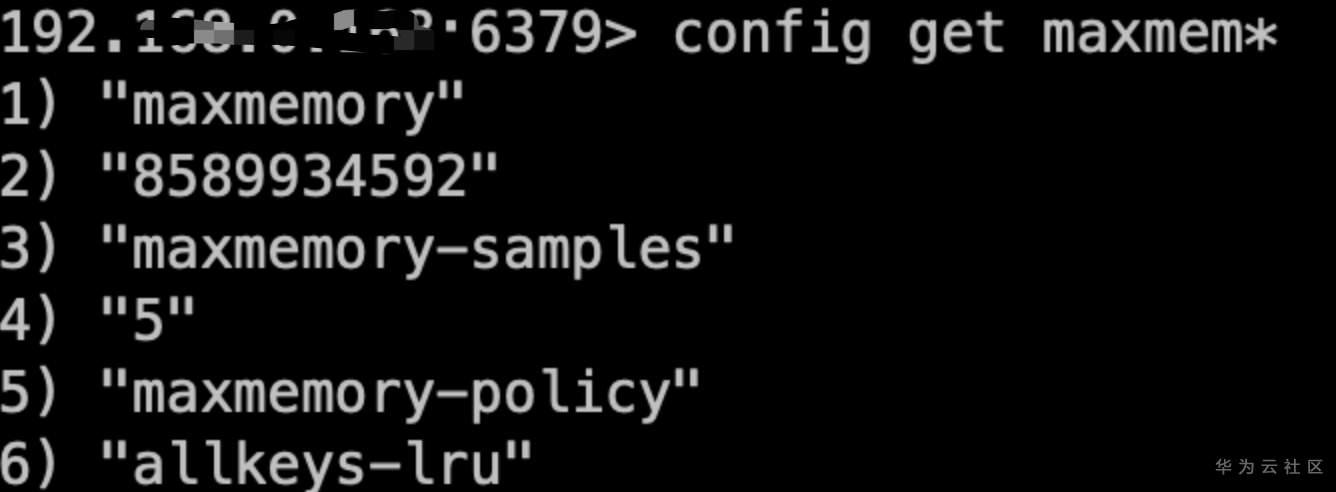
也可以通过配置maxmemory-policy设置数据淘汰策略保障数据写入,如图我们将淘汰策略设置成allkeys-lru,即淘汰最近最少使用的key 满足插入数据的内存需求;
![]()
修改配置后 插入正常
![]()
综上,GaussDB(for Redis)更加看重数据安全,将“保障用户数据不丢”作为最高优先级。当数据写满后自动进入只读模式,确保实例中数据的安全。通过控制台可以做到快速的扩容,最大可能降低对业务的影响。 原生Redis提供了数据淘汰参数,用户可自主选择策略当数据写满后淘汰符合条件的数据,设计思想更偏向于缓存的用途“数据可随意丢弃”。如使用在重要的业务场景,不希望数据丢失,建议选择GaussDB(for Redis)。
6、测试总结
本次我们使用memtier_benchmark分别对GaussDB(for Redis) 和原生Redis进行set操作的测试,8G规格的GaussDB(for Redis) 很顺利的完成了数据加载的操作,原生Redis出现OOM异常导致数据加载失败。原生Redis通过fork进程copy-on-write的方式拷贝数据,在RDB快照、aof重写以及新增从库等操作时容易出现OOM异常。反观GaussDB(for Redis) 由于摒弃了fork机制,使得架构更健壮,服务的可用性更强。
在后续的扩容操作中GaussDB(for Redis)能够快速完成且对业务RW操作无影响,而原生Redis扩容需停服,期间业务无法正常使用。GaussDB(for Redis)快速扩容的特性非常适合生产环境中需要紧急扩容的场景,如游戏开服、电商抢购的火爆程度远超预期时。从测试的情况看,扩容几乎达到了秒级完成,且扩容过程中对业务的读写完全没有影响。
另外更重要的原生Redis无论采用RDB还是aof方式进行数据持久化,都有数据丢失的风险,而GaussDB(for Redis)支持全量数据落盘,GaussDB基础组件服务提供底层数据三副本冗余保存,能够保证数据零丢失。如果使用场景既要满足KV查询的高性能,又希望数据得到重视能够不丢,建议从原生Redis迁移到GaussDB(for Redis) 。
点击关注,第一时间了解华为云新鲜技术~