Kyuubi 简介
Apache Kyuubi (Incubating)是一个 Thrift JDBC/ODBC 服务,目前对接了 Apache Spark 计算框架,支持多租户和分布式等特性,可以满足企业内诸如 ETL、BI 报表等多种大数据场景的应用。Kyuubi 可以为企业级数据湖探索提供标准化的接口,赋予用户调动整个数据湖生态的数据的能力,使得用户能够像处理普通数据一样处理大数据。项目已于2021年 6 月 21 号正式进入 Apache 孵化器。从社区当前阶段的发展目标来看,它的主要方向是依托本身的架构设计,围绕各类主流计算框架,打造一个面向 Serverless SQL on Lakehouse 的服务。
项目地址:https://github.com/apache/incubator-kyuubi
前言
为了能让 Kyuubi 可以更好的满足诸如 ETL、BI 报表等多种大数据场景的应用,从 Kyuubi v1.0.0 版本开始,我们引入了 Kyuubi 引擎共享级别这个概念,来对的迭代过程中不断被优化和完善。
Kyuubi 引擎的共享级别描述了会话(session)和引擎(engine)之间的对应关系。它决定了一个新的会话是否可以以及如何与其他会话共享一个现有的后台引擎。会话也被视为来自终端用户创建的客户端发起的Thrift JDBC/ODBC连接,而引擎是独立的分布式应用程序,他它在 Spark SQL、 Flink SQL(开发中,见 https://github.com/apache/incubator-kyuubi/issues/1322 )等计算框架之上实现了所有功能,支持在单节点机器或集群上运行。
Kyuubi 的服务端是这个对应关系的描述者。而它本身是一个是水平可扩展的服务发现层,支持多个 Kyuubi Server 进行负载均衡(LoadBalance)来提供高可用(HA)、平滑下线等能力。值得注意的是,无论是在HA还是单节点模式下,Kyuubi引擎共享级别的功能都是不受影响的。换句话说,客户端无论连接到哪个 Kyuubi Server 节点,在共享级别规则生效的前提下,它都能准确的联系上对应的引擎。
为什么我们需要这个功能?
Apache Spark是一个用于大规模数据分析的统一计算框架。在想象驾驶这样一辆全时驱动的超跑风驰电掣时,我们也要考虑人、车、环境等一系列综合因素的影响。Kyuubi 在 API 上的易用性设计已经很大程度上降低了用户使用Spark SQL 来处理数据的准入门槛和难度。而在运行时, Spark 本身的运行效率,也受到各种依赖服务,如 YARN, HDFS, HiveMetastore 等依赖因素的影响。举例来说,
-
百公里加速耗时。Spark 程序在启动时需要和 YARN 和 HDFS 完成大量的准备工作来启动自己,正常情况下这个阶段是非常耗时的,更不用说在一些资源相对紧张的场景下。通过共享复用,可以免去这个耗时。
-
核载量。Spark 程序主从架构及运行时的资源预设基本可以求导出其核载量,当实际的承载量超出这个阈值时,应用会变得不稳定。适当的隔离,可以让应用更加安全。
-
资源利用率。一个常驻的 Spark 应用的资源管理基本上是由自身去管理的,当客户端请求频繁时,可以更高效的复用 Driver/Executor 的资源,反之,资源就闲置了。一个非常驻的 Spark 应用的资源管理基本上是通过YARN/K8S等平台去管理的,用完了释放,可以让别的应用去高效的竞争这些资源。
通过这个功能, 用户和集群管理者可以更加灵活地处理不同的大数据工作负载。
共享级别
Kyuubi 目前支持下表所示的集中贡献级别。其中,更好的引擎隔离度使我们的引擎和在其上运行的查询执行更加稳定。更好的引擎共享性意味着我们更有可能重用一个已经全速运转的引擎。
![]()
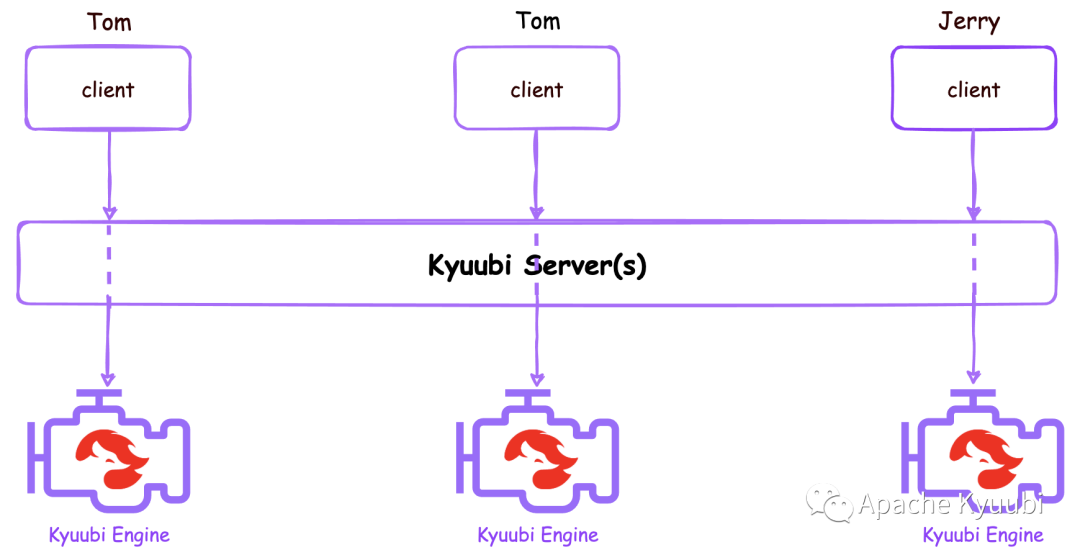
CONNECTION
![]()
如上图所示,在CONNECTION共享级别下,会话和引擎是一对一的关系,每个会话都有一个自己的独立引擎,其他任何人或连接都无法访问。在会话中,一个用户或客户端可以向相应的引擎发送多个操作请求,包括元数据调用或 SQL 查询任务。尽管它仍然是一种交互式的形式可以进行Ad hoc 查询,但这种模式可以提供良好的隔离性使得它也适合批处理作业。当关闭会话时,相应的引擎也会同时关闭,意味着独占的资源会全部返还给资源管理器。
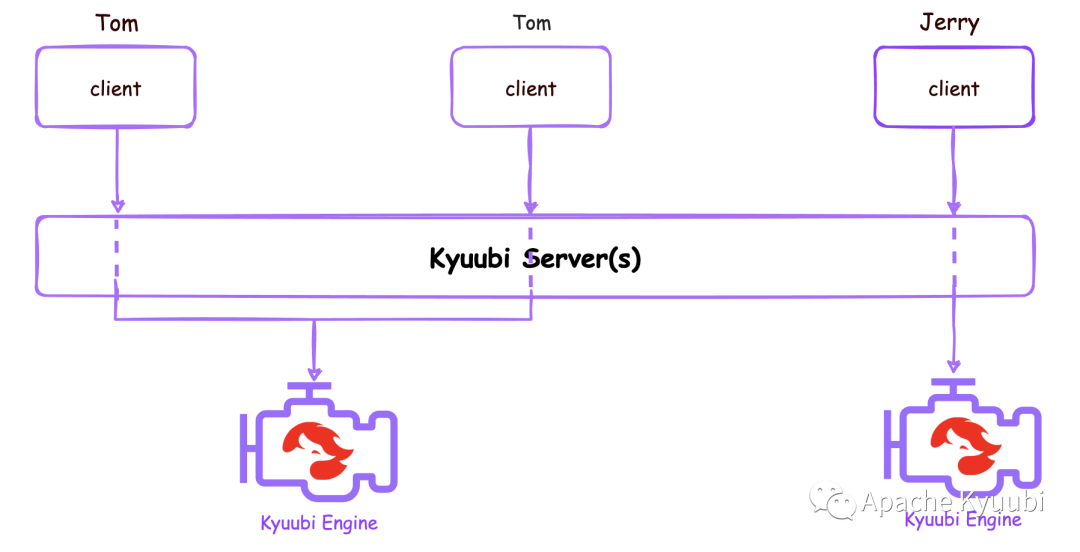
USER
![]()
如上图所示,在 USER 共享级别下,用户和引擎是一对一的关系,每个用户都有一个自己的独立引擎,其他任何人都无法访问,而来自同一用户的会话连接则可以复用这个引擎。共享的范畴可以大致概括为 SparkContext 对象和 SharedState 对象。前者包含了 Spark 程序运行所需环境,包括类加载器、全局的配置(Spark conf/Hadoop conf等)、Driver / Executors 进程。后者包括外置的Catalog、Hive Metastore的客户端、全局的视图管理器等。默认情况下,每个会话依然可以拥有自己线程安全的 SparkSession 实例,它包含临时视图,SQL配置、UDFs等 SessionState 里的内容。当然,将 kyuubi.engine.single.spark.session 设置为 true 将使 SparkSession 变成单例,这时候它也会被所有会话共享。
不同于 CONNECTION 共享级别,在 USER 共享级别下,在当关闭会话时,相应的引擎将不会被关闭。并且,当所有的会话都被关闭时,它仍然有一个存活时间(Time to live, TTL)。在这个TTL内,可以快速建立新的会话,而无需等待引擎启动,这对 Ad hoc 场景是友好的,特别是对于一些耗时极短的 SQL 而言。
USER 共享级别目前是 Kyuubi 默认的模式。
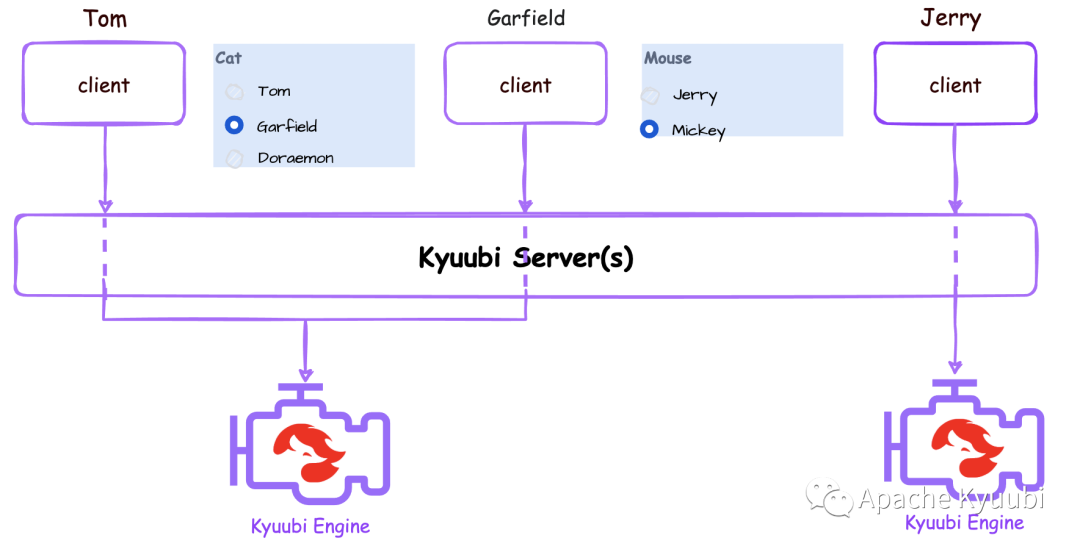
GROUP
![]()
如上图所示,在 GROUP 共享级别下,主用户组(Primary Group)和引擎是一对一的关系,每个主用户组都有一个自己的独立引擎,其他任何用户组都无法访问,而属于同一用户组的用户则可以复用这个引擎,达到多人或者团队共享的目的。我们可以遵循Hadoop GroupsMapping(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/GroupsMapping.html ),通过配置将用户映射到一个主用户组。
与 USER 共享级别相比,SparkContext、SparkSession 和 TTL 的工作机制基本都是一样的。值得注意的是,由于单个 Spark 应用全局的用户属性(sparkUser)是唯一的且不变的,所以我们只能拿主用户组来模拟它。如果你想依靠一些插件对客户端用户进行细粒度的访问控制,你需要从 SparkContext.getLocalProperty("kyuubi.session.user") 获取它,并将它发送给安全服务,比如 Apache Ranger。
GROUP 共享级别将在 Kyuubi v1.4.0-Incubating 版本发布。在一些场景下,比如计算资源是稀缺的,而相对而言用户却不少,这时候给每个用户启动一个引擎,显然是僧多粥少。不防使用 GROUP 模式,并使用 Spark 提供的 Fair Scheduler Pools 功能(https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application) 来进行 App 内的隔离共享,不同的会话可以通过 set spark.scheduler.pool = poolName 来实现一定的隔离能力。
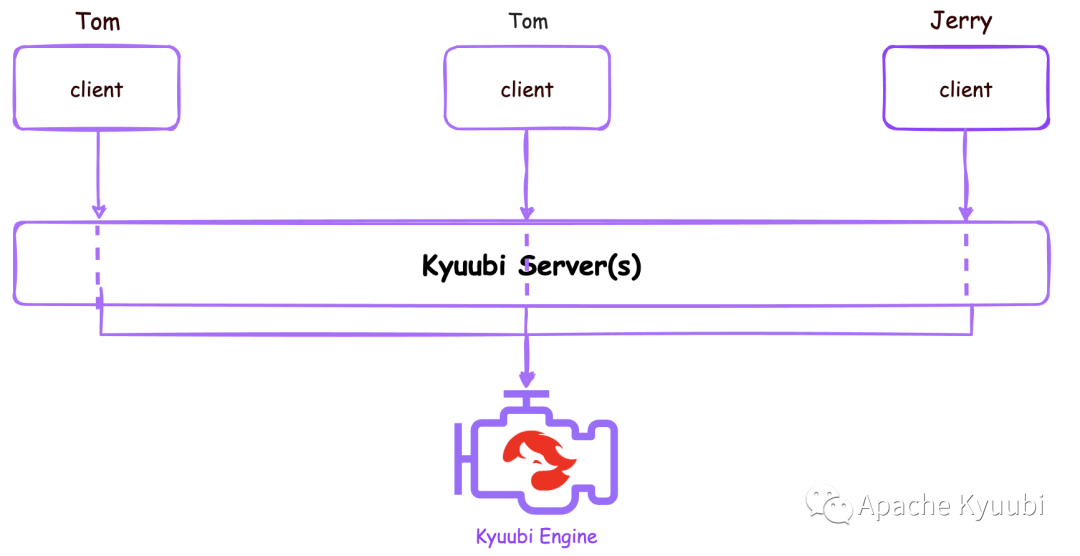
SERVER
![]()
如上图所示,在 SERVER 共享级别下,架构就比较简单了。基本上就等同于一个 Spark 社区提供的 ThriftServer,附带上了高可用特性。
在安全集群中,比如开启了 Kerberos 认证的 Hadoop 集群,那对终端用户就必须是拥有 Service Principal/Keytab 的管理员,才能使用这个模式了。
Subdomain
引擎共享子域(kyuubi.engine.share.level.subdomain)是对引擎共享级别的补充。在满足租户隔离不被破坏的前提下,让 USER、GROUP 或 SERVER 共享级别也能够为一个用户、组或服务器(集群)创建多个引擎。
例如,在USER共享级别,你可以使用kyuubi.engine.share.level.subdomain=sd1 和 kyuubi.engine.share.level.subdomain=sd2 来为用户 Tom 创建两个独立的引擎,而 Tom 的其他会话可以分别指定这两个键值对来选择对应子域的引擎复用。
kyuubi.engine.share.level.subdomain 应配置在 JDBC 连接 URL 中,以告诉Kyuubi Server 你想使用哪个引擎。
混合使用
所有支持的共享级别都可以同时在一个 Kyuubi Server 或集群中一起使用。
相关配置项
https://github.com/apache/incubator-kyuubi/blob/master/docs/deployment/engine_share_level.md#related-configurations
结论
用纯 SQL 的方式去描述传统大数据数仓或者是 Lakehouse 上的各种工作负载、最大化计算资源的效能,并满足企业服务等级协议(SLA)的要求,并不是一件容易的事情。在 Kyuubi 中我们引入了 Kyuubi 引擎共享级别来适配不同场景的诉求。同时,这个功能可以配合 Apache Spark 提供的动态资源分配、推断执行、Adaptive Query Execution等高阶功能共同强化用户大规模 ETL 任务及 Ad hoc 查询的自动化能力,为用户带来 Serverless SQL on Lakehouse 的能力。
作者:Kent Yao,网易数帆技术专家,Apache Kyuubi(Incubating) PPMC