摘要:本文将介绍如何使用AI技术实现失败测试用例的智能分析。
本文分享自华为云社区《测试用例又双叒叕失败了,啥原因?NLP帮你来分析》,作者: 敏捷的小智 。
随着软件行业的快速发展,为了实现高质量的快速迭代,越来越多的公司开始推进测试自动化来缩短测试周期,较成熟的软件公司开始追求80%甚至更高的测试自动化率。一轮耗时一周的手工测试在自动化后可能一天或更短时间内就能完成全部执行。在每一轮自动化测试中,对失败用例进行根因分析是一份十分重要的工作,而海量测试日志的人工分析开始成为瓶颈。本文将介绍如何使用AI技术实现失败测试用例的智能分析。
基于日志分析辅助开发人员发现及定位系统问题早已不是新鲜课题,在过去几十年里都有广泛的研究。随着数据的持续积累,学术界的研究和工业实践都有尝试使用机器学习来求解,包括监督方法和非监督方法。在发现问题方面,2017年的一篇《DeepLog: Anomaly Detection and Diagnosis from System Logs》引起了广泛的关注。文中介绍了通过多重LSTM模型,学习日志模板及日志参数组成的时序数据特征,对系统行为及系统状态进行异常检测,辅助开发人员提前感知系统的潜在风险。本文将从定位问题的角度,介绍如何使用日志分析的技术在测试场景下辅助失败用例的根因定位。
本文的使用的算法简单很多,但对测试日志及历史分析有较高的要求。首先,基于大数定律,样本量越大越能接近数据的原始分布,所以要求待分析的失败用例要有足够的量级,-否则不仅有杀鸡用牛刀之嫌,效果也不会好。其次,要有一定的失败测试用例分析数据,本文介绍的是有监督学习的解决方案,带标签的数据质量将会决定学习效果的上线。
好了,既然上来就揭了谜底:用文本分类模型来实现失败测试用例的根因定位。就先给大家展示一下完整的解决方案。
![]()
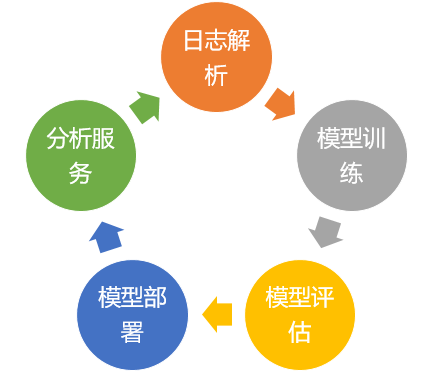
图一:失败测试日志分析服务构建流程
如图一所示,失败测试日志分析服务构建流程可以概括为以下步骤:
1. 测试日志分析数据的准备:确认测试日志被正确记录并保存,对失败测试日志的根因分析也被妥善保存。日志中应该包含可以用来定位根因的高价值信息,如系统返回的错误码、报错信息等。
2. 模型的训练:根据已有的分析数据训练模型。
a) 日志清洗:在失败用例的日志中, 充斥的大量与失败原因不相关的内容。这些噪音数据会增加模型训练的不确定性。结合历史经验,对日志数据进行清洗,提取关键信息,在训练初期是不可缺少的关键一步。例如,实践中发现,几乎所有失败用例中都有系统返回的错误信息。如果没有,需要仔细检查一下是日志设计不合理,还是可以直接认定为测试环境问题。测试人员拿到失败测试用例,看到错误信息基本就能定位大概的失败原因。所以在日志清洗时,只截取错误信息,是目前实践下来效果较好的一个预处理步骤。
样例:
Case001 配置问题 参数比对失败
Case002 环境问题 无法连接*.*.*.*
……
b) 日志预处理:人参与的越少,后期维护的成本越低,所以在日志预处理阶段,只对日志做简单预处理,如分词、去除停用词等。
c) 模型训练:将历史分析数据载入TextCNN文本分类模型。TextCNN最大的优势是网络结构简单,在多项数据集上轻松超越benchmark。网络结构简单,参数数目少,计算量少,训练速度较快。想了解模型细节的同学,可以戳Convolutional Neural Networks for Sentence Classification 。
d) 模型调参:通过修改embedding dim长度、调整随机策略等,尝试获得最优的模型。当模型能在实验室实现train test的准确率在85%左右,可以认为是ready to go的模型。
3. 将步骤2训练获得的模型host成在线分析服务。
4. 测试自动化执行中,失败测试用例的日志在预处理后,被自动post到预测服务,获得预测的结果,包括预测的根因和置信度。
测试人员可以在一轮测试执行后立刻得到测试结果分析报告。
首先测试人员结合历史经验,对可直观感知到失败原因的测试用例及时进行定位并做出处理,比如是测试环境问题则修复环境,重新执行测试用例。
其次,结合模型输出的置信度,对预测结果做好分级。历史上大量出现过的的错误日志,一般置信度较高,直接给出根因。置信度较低的失败用例,可能是新增问题,及时给出警告。
不同的业务场景会生成不同的日志,随着业务场景的不断增加,日志的特征空间趋于无限,无法用同一个模型适配所有场景。尽量减少人工参与,针对特定业务场景,使用较轻量级的模型快速训练迭代,是能够在工业界落地实现的一个很重要的特性,本文介绍的TextCNN文本分类模型目前实践来看是能够满足以上要求的。在提升模型准确度上,结合主动学习提升数据质量,引入小样本学习减少人工依赖将是后续重点的探索方向。
参考资料
1. Experience Report: System Log Analysis for Anomaly Detection, 2016.
点击关注,第一时间了解华为云新鲜技术~