本文节选自《设计模式就该这样学》之享元模式(Flyweight Pattern)
1 故事背景
一个程序员就因为改了生产环境上的一个方法参数,把int型改成了Integer类型,因为涉及到钱,结果上线之后公司损失惨重,程序员被辞退了。信不信继续往下看。先来看一段代码:
public static void main(String[] args) {
Integer a = Integer.valueOf(100);
Integer b = 100;
Integer c = Integer.valueOf(129);
Integer d = 129;
System.out.println("a==b:" + (a==b));
System.out.println("c==d:" + (c==d));
}
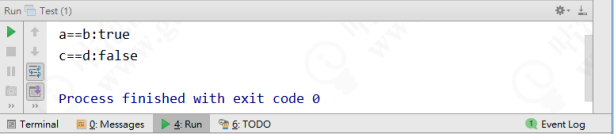
大家猜它的运行结果是什么?在运行完程序后,我们才发现有些不对,得到了一个意想不到的运行结果,如下图所示。
![file]()
看到这个运行结果,有人就一定会问,为什么是这样?之所以得到这样的结果,是因为Integer用到的享元模式。来看Integer的源码,
public final class Integer extends Number implements Comparable<Integer> {
...
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
...
}
再继续进入到IntegerCache的源码来看low和high的值:
private static class IntegerCache {
// 最小值
static final int low = -128;
// 最大值,支持自定义
static final int high;
// 缓存数组
static final Integer cache[];
static {
// 最大值可以通过属性配置来改变
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
// 如果设置了对应的属性,则使用该值
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// 最大数组大小为Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
// 将low-high范围内的值全部实例化并存入数组中当缓存使用
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
由上可知,Integer源码中的valueOf()方法做了一个条件判断,如果目标值在-128 - 127,则直接从缓存中取值,否则新建对象。其实,Integer第一次使用的时候就会初始化缓存,其中范围最小值为-128,最大值默认是127。接着会把low至high中所有的数据初始化存入数据中,默认就是将-128 - 127总共256个数循环实例化存入cache数组中。准确的说应该是将这256个对象在内存中的地址存进数组中。这里又有人会问了,那为什么默认是-128 - 127,怎么不是-200 - 200或者是其他值呢?那JDK为何要这样做呢?
在Java API 中是这样解释的:
Returns an Integer instance representing the specified int value. If a new Integer instance is not required, this method should generally be used in preference to the constructor Integer(int), as this method is likely to yield significantly better space and time performance by caching frequently requested values. This method will always cache values in the range -128 to 127, inclusive, and may cache other values outside of this range
大致意思是:
128~127的数据在int范围内是使用最频繁的,为了减少频繁创建对象带来的内存消耗,这里其实是用到了享元模式,以提高空间和时间性能。
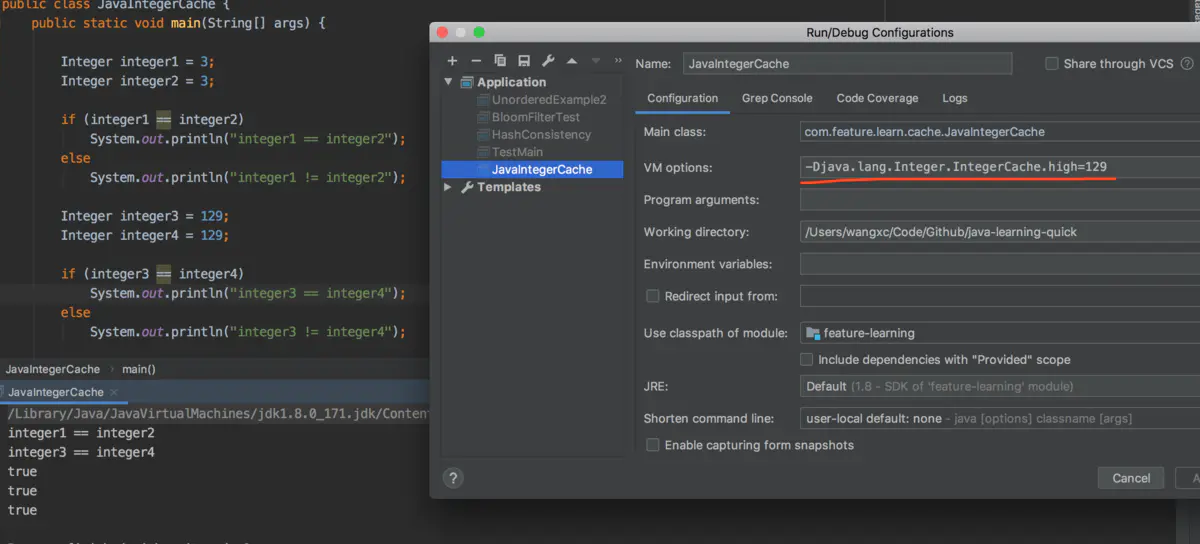
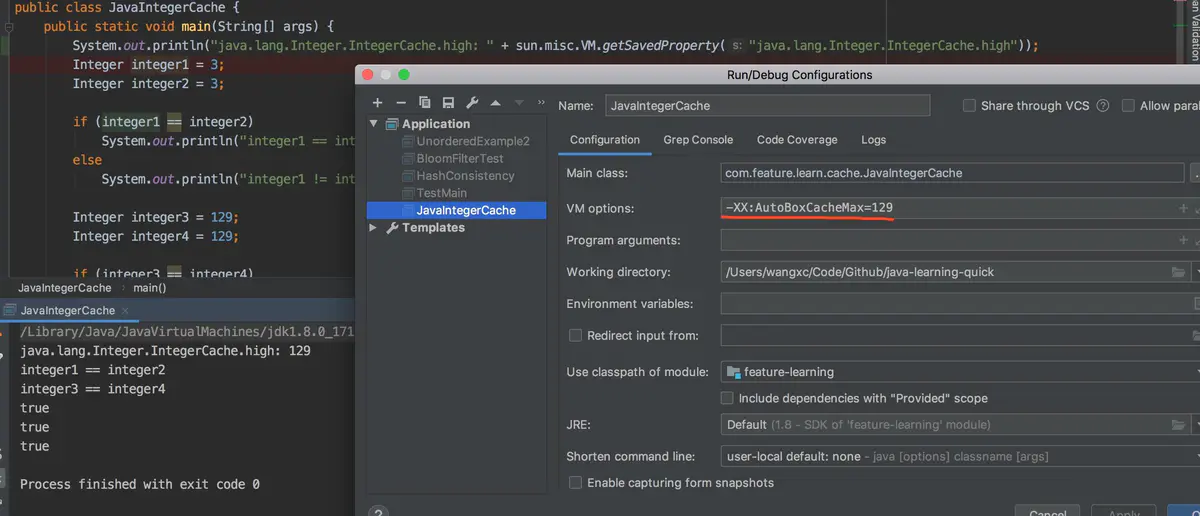
JDK增加了这一默认的范围并不是不可变,我们在使用前可以通过设置-Djava.lang.Integer.IntegerCache.high=xxx或者设置-XX:AutoBoxCacheMax=xxx来修改缓存范围,如下图:
![file]()
![file]()
后来,我又找到一个比较靠谱的解释:
实际上,在Java 5中首次引入此功能时,范围固定为-127到+127。 后来在Java 6中,范围的最大值映射到java.lang.Integer.IntegerCache.high,VM参数允许我们设置高位数。 根据我们的应用用例,它可以灵活地调整性能。 应该从-127到127选择这个数字范围的原因应该是什么。这被认为是广泛使用的整数范围。 在程序中首次使用Integer必须花费额外的时间来缓存实例。
Java Language Specification 的原文解释如下:
Ideally, boxing a given primitive value p, would always yield an identical reference. In practice, this may not be feasible using existing implementation techniques. The rules above are a pragmatic compromise. The final clause above requires that certain common values always be boxed into indistinguishable objects. The implementation may cache these, lazily or eagerly. For other values, this formulation disallows any assumptions about the identity of the boxed values on the programmer's part. This would allow (but not require) sharing of some or all of these references. This ensures that in most common cases, the behavior will be the desired one, without imposing an undue performance penalty, especially on small devices. Less memory-limited implementations might, for example, cache all char and short values, as well as int and long values in the range of -32K to +32K.
2 关于Integer和int的比较
- 由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false
- Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true
- 非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为 ①当变量值在-128 - 127之间时,非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同;②当变量值在-128 - 127之间时,非new生成Integer变量时,java API中最终会按照new Integer(i)进行处理(参考下面第4条),最终两个Interger的地址同样是不相同的)
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false
- 对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
3 扩展知识
在JDK中,这样的应用不止int,以下包装类型也都应用了享元模式,对数值做了缓存,只是缓存的范围不一样,具体如下表所示:
| 基本类型 |
大小 |
最小值 |
最大值 |
包装器类型 |
缓存范围 |
是否支持自定义 |
| boolean |
- |
- |
- |
Bloolean |
- |
- |
| char |
6bit |
Unicode 0 |
Unic ode 2(16)-1 |
Character |
0~127 |
否 |
| byte |
8bit |
-128 |
+127 |
Byte |
-128~127 |
否 |
| short |
16bit |
-2(15) |
2(15)-1 |
Short |
-128~127 |
否 |
| int |
32bit |
-2(31) |
2(31)-1 |
Integer |
-128~127 |
支持 |
| long |
64bit |
-2(63) |
2(63)-1 |
Long |
-128~127 |
否 |
| float |
32bit |
IEEE754 |
IEEE754 |
Float |
- |
|
| double |
64bit |
IEEE754 |
IEEE754 |
Double |
- |
|
| void |
- |
- |
- |
Void |
- |
- |
大家觉得这个锅背得值不值?
4 使用享元模式实现数据库连接池
再举个例子,我们经常使用的数据库连接池,因为使用Connection对象时主要性能消耗在建立连接和关闭连接的时候,为了提高Connection对象在调用时的性能,将Connection对象在调用前创建好并缓存起来,在用的时候直接从缓存中取值,用完后再放回去,达到资源重复利用的目的,代码如下。
public class ConnectionPool {
private Vector<Connection> pool;
private String url = "jdbc:mysql://localhost:3306/test";
private String username = "root";
private String password = "root";
private String driverClassName = "com.mysql.jdbc.Driver";
private int poolSize = 100;
public ConnectionPool() {
pool = new Vector<Connection>(poolSize);
try{
Class.forName(driverClassName);
for (int i = 0; i < poolSize; i++) {
Connection conn = DriverManager.getConnection(url,username,password);
pool.add(conn);
}
}catch (Exception e){
e.printStackTrace();
}
}
public synchronized Connection getConnection(){
if(pool.size() > 0){
Connection conn = pool.get(0);
pool.remove(conn);
return conn;
}
return null;
}
public synchronized void release(Connection conn){
pool.add(conn);
}
}
这样的连接池,普遍应用于开源框架,可以有效提升底层的运行性能。
【推荐】Tom弹架构:收藏本文,相当于收藏一本“设计模式”的书
本文为“Tom弹架构”原创,转载请注明出处。技术在于分享,我分享我快乐!
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。关注微信公众号『 Tom弹架构 』可获取更多技术干货!