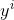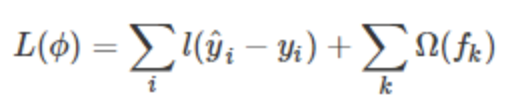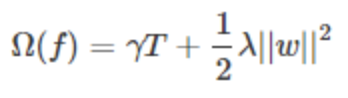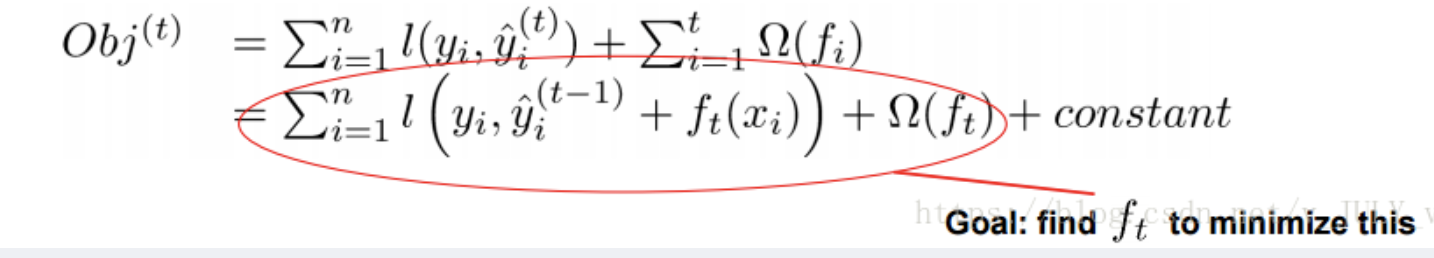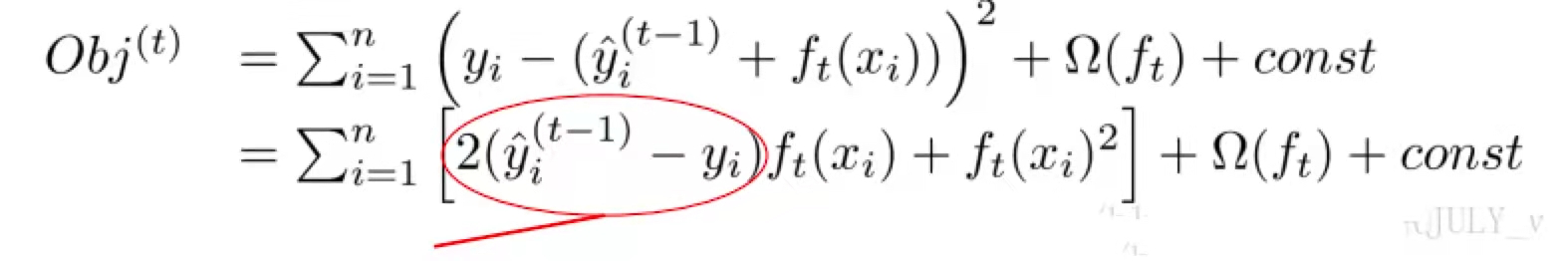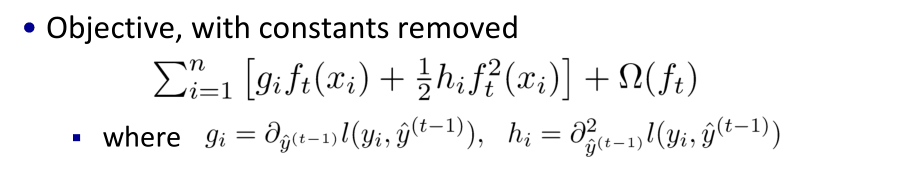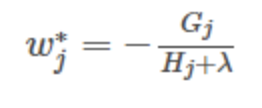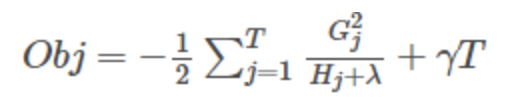这两个模型都属于集成学习中的树模型,每个机器学习模型都有它特定的应用场景,不同的数据集适合用到的模型是不一样的。
结构化数据、非结构化数据
- 结构化数据:规整,维度固定;一般我们的表格数据都属于结构化数据。
- 非结构化数据:非规整,维度不固定;比如说一些文本、图像、音频、视频等
![]()
结构化数据的特点:
- 类别字段较多
- 聚合特征较多
![]()
对于结构化数据集,如果我们遇到的数据集有很多类别类型的特征,而且特征与特征之间是相互独立的,非常适合使用树模型。
XGBoost
提出时间较早的高阶树模型,精度较好。比随机森林较晚,比LightGBM、Catboost较早。
缺点:训练时间较长,对类别特征支持不友好。
接口:scikit-learn接口和原声接口。
XGBoost是基于GBDT(Gradient Boosting Decision Tree)的一种算法模型,有关Gradient Boosting的介绍可以参考机器学习算法整理(四)
XGBoost首先是树模型,Xgboost就是由很多CART树集成。一般有分类树和回归树,分类树是使用数据集的特征(维度)以及信息熵或者基尼系数来进行节点分裂。对于回归树则无法使用信息熵和基尼系数来判定树的节点分裂,包括预测误差(常用的有均方误差、对数误差等)。而且节点不再是类别,是数值(预测值),那么怎么确定呢?有的是节点内样本均值,有的是最优化算出来的比如XGBoost。
CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。
![]()
而CART回归树实质上就是在该特征维度对样本空间进行划分,而这种空间划分的优化是一种NP难问题,因此,在决策树模型中是使用启发式方法解决。典型CART回归树产生的目标函数为:
![]()
因此,当我们为了求解最优的切分特征j和最优的切分点s,就转化为求解这么一个目标函数:
![]()
所以我们只要遍历所有特征的的所有切分点,就能找到最优的切分特征和切分点。最终得到一棵回归树。
我们之前在Gradient Boosting的介绍中说,每次训练出一个模型m后会产生一个错误e,这个错误就是残差。GBDT是计算负梯度,用负梯度近似残差。回归任务下,GBDT 在每一轮的迭代时对每个样本都会有一个预测值,此时的损失函数为均方差损失函数
![]()
此时的负梯度
![]()
所以,当损失函数选用均方损失函数时,每一次拟合的值就是(真实值 - 当前模型预测的值),即残差。此时的变量是![]() ,即“当前预测模型的值”,也就是对它求负梯度。残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。“残差”蕴含了有关模型基本假设的重要信息。如果回归模型正确的话, 我们可以将残差看作误差的观测值。GBDT需要将多棵树的得分累加得到最终的预测得分,且每一次迭代,都在现有树的基础上,增加一棵树去拟合前面树的预测结果与真实值之间的残差。
,即“当前预测模型的值”,也就是对它求负梯度。残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。“残差”蕴含了有关模型基本假设的重要信息。如果回归模型正确的话, 我们可以将残差看作误差的观测值。GBDT需要将多棵树的得分累加得到最终的预测得分,且每一次迭代,都在现有树的基础上,增加一棵树去拟合前面树的预测结果与真实值之间的残差。
XGBoost与GBDT比较大的不同就是目标函数的定义。XGBoost的目标函数如下图所示(注意这里是已经迭代切分之后的):
![]()
其中
- 红色箭头所指向的L 即为损失函数(比如平方损失函数:
![]() ,或逻辑回归损失函数:
,或逻辑回归损失函数:![]()
- 红色方框所框起来的是正则项(包括L1正则、L2正则)
- 红色圆圈所圈起来的为常数项
- 对于
![f(x)]() ,XGBoost利用泰勒展开三项,做一个近似。t是迭代次数。
,XGBoost利用泰勒展开三项,做一个近似。t是迭代次数。
我们可以很清晰地看到,最终的目标函数只依赖于每个数据点在误差函数上的一阶导数和二阶导数(泰勒展开,请参考高等数学整理 中的泰勒公式定义)
XGBoost的核心算法思想
- 不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。
![]()
注:![]() 为叶子节点q的分数,F对应了所有K棵回归树(regression tree)的集合,而f(x)为其中一棵回归树。T表示叶子节点的个数,w表示叶子节点的分数。
为叶子节点q的分数,F对应了所有K棵回归树(regression tree)的集合,而f(x)为其中一棵回归树。T表示叶子节点的个数,w表示叶子节点的分数。
- 当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数
- 最后只需要将每棵树对应的分数加起来就是该样本的预测值。
显然,我们的目标是要使得树群的预测值![]() 尽量接近真实值
尽量接近真实值![]() ,而且有尽量大的泛化能力。
,而且有尽量大的泛化能力。
所以,从数学角度看这是一个泛函最优化问题,故把目标函数简化如下:
![]()
这个目标函数分为两部分:损失函数和正则化项。且损失函数揭示训练误差(即预测分数和真实分数的差距),正则化定义复杂度。对于上式而言,![]() 是整个累加模型的输出,正则化项
是整个累加模型的输出,正则化项![]() 是则表示树的复杂度的函数,值越小复杂度越低,泛化能力越强,其表达式为
是则表示树的复杂度的函数,值越小复杂度越低,泛化能力越强,其表达式为
![]()
T表示叶子节点的个数,w表示叶子节点的分数。直观上看,目标要求预测误差尽量小,且叶子节点T尽量少(γ控制叶子结点的个数),节点数值w尽量不极端(λ控制叶子节点的分数不会过大),防止过拟合。
具体来说,目标函数第一部分中的i表示第i个样本,![]() 表示第i个样本的预测误差,我们的目标当然是误差越小越好。
表示第i个样本的预测误差,我们的目标当然是误差越小越好。
类似之前GBDT的套路,XGBoost也是需要将多棵树的得分累加得到最终的预测得分(每一次迭代,都在现有树的基础上,增加一棵树去拟合前面树的预测结果与真实值之间的残差)。
![]()
我们如何选择每一轮加入什么![f]() 呢?答案是非常直接的,选取一个
呢?答案是非常直接的,选取一个![f]() 来使得我们的目标函数尽可能的小。
来使得我们的目标函数尽可能的小。
![]()
第t轮的模型预测值 ![]() = 前t-1轮的模型预测
= 前t-1轮的模型预测![]() +
+ ![]() ,因此误差函数记为:
,因此误差函数记为:![]() (
( ![]() ,
, ![]() +
+ ![]() ),后面一项为正则化项。对于这个误差函数的式子而言,在第t步,
),后面一项为正则化项。对于这个误差函数的式子而言,在第t步,![]() 是真实值,即已知,
是真实值,即已知,![]() 可由上一步第t-1步中的
可由上一步第t-1步中的![]() 加上
加上![]() 计算所得,某种意义上也算已知值,故模型学习的是
计算所得,某种意义上也算已知值,故模型学习的是![f]() 。
。
我们可以考虑当![]() 是平方误差的情况(相当于
是平方误差的情况(相当于![]() ),这个时候我们的目标可以被写成下面这样的二次函数(图中画圈的部分表示的就是预测值和真实值之间的残差):
),这个时候我们的目标可以被写成下面这样的二次函数(图中画圈的部分表示的就是预测值和真实值之间的残差):
![]()
更加一般的,损失函数不是二次函数咋办?利用泰勒展开,不是二次的想办法近似为二次
![]()
为什么损失函数一定要有二次项,因为损失函数必须可导。通过求导,可以寻找能够使损失函数最小的参数,这些参数对应的映射即最佳线性回归或者逻辑回归。所以泰勒展开可以在没有二次项的情况下,人为创造一个二次项。
考虑到我们的第t 颗回归树是根据前面的t-1颗回归树的残差得来的,相当于t-1颗树的值![]() 是已知的。换句话说,
是已知的。换句话说,![]() 对目标函数的优化不影响,可以直接去掉,且常数项也可以移除,从而得到如下一个比较统一的目标函数。
对目标函数的优化不影响,可以直接去掉,且常数项也可以移除,从而得到如下一个比较统一的目标函数。
![]()
这时,目标函数只依赖于每个数据点在误差函数上的一阶导数![g]() 和二阶导数
和二阶导数![h]() 。
。
XGBoost总的指导原则:实质是把样本分配到叶子结点会对应一个目标函数obj,优化过程就是目标函数obj优化。也就是分裂节点到叶子不同的组合,不同的组合对应不同目标函数obj,所有的优化围绕这个思想展开。
正则项:树的复杂度
在这种新的定义下,我们可以把之前的目标函数进行如下变形,这里L2正则![]()
![]()
其中![]() 被定义为每个叶节点 j 上面样本下标的集合
被定义为每个叶节点 j 上面样本下标的集合 ![]() ,g是一阶导数,h是二阶导数。这一步是由于XGBoost目标函数第二部分加了两个正则项,一个是叶子节点个数(T),一个是叶子节点的分数(w)。
,g是一阶导数,h是二阶导数。这一步是由于XGBoost目标函数第二部分加了两个正则项,一个是叶子节点个数(T),一个是叶子节点的分数(w)。
从而,加了正则项的目标函数里就出现了两种累加
- 一种是i - > n(样本数)
- 一种是j -> T(叶子节点数)
这一个目标包含了T个相互独立的单变量二次函数。接着,我们可以定义
![]()
最终公式可以化简为
![]()
通过对![]() 求导等于0,可以得到
求导等于0,可以得到
![]()
然后把![]() 最优解代入得到:
最优解代入得到:
![]()
现在我们来看一下代码示例
数据下载地址:https://www.kaggle.com/c/ga-customer-revenue-prediction/data?select=train.csv
INPUT_TRAIN = "/Users/admin/Downloads/ga-customer-revenue-prediction/train.csv"
INPUT_TEST = "/Users/admin/Downloads/ga-customer-revenue-prediction/test.csv"
TRAIN = "/Users/admin/Downloads/ga-customer-revenue-prediction/train-processed.csv"
TEST = "/Users/admin/Downloads/ga-customer-revenue-prediction/test-processed.csv"
Y = "/Users/admin/Downloads/ga-customer-revenue-prediction/y.csv"
import os
import gc
import json
import time
from datetime import datetime
import timeit
import numpy as np
import pandas as pd
from pandas.io.json import json_normalize
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import warnings
warnings.filterwarnings('ignore')
if __name__ == "__main__":
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
def load_df(csv_path=INPUT_TRAIN, nrows=None):
# 导入csv文件
print(f"Loading {csv_path}")
JSON_COLUMNS = ['device', 'geoNetwork', 'totals', 'trafficSource']
# 读取文件的数据,并将JSON_COLUMNS中的字段读取成json格式
df = pd.read_csv(csv_path, converters={column: json.loads for column in JSON_COLUMNS},
dtype={'fullVisitorId': 'str'}, nrows=nrows)
# 将json格式的每一个字段变成pandas表本身的字段
for column in JSON_COLUMNS:
column_as_df = json_normalize(df[column])
column_as_df.columns = [f"{column}.{subcolumn}" for subcolumn in column_as_df.columns]
df = df.drop(column, axis=1).merge(column_as_df, right_index=True, left_index=True)
print(f"Loaded {os.path.basename(csv_path)}. Shape: {df.shape}")
return df
def process_dfs(train_df, test_df):
# 数据预处理
print("Processing dfs...")
print("Dropping repeated columns...")
# 去重
columns = [col for col in train_df.columns if train_df[col].nunique() > 1]
train_df = train_df[columns]
test_df = test_df[columns]
trn_len = train_df.shape[0]
merged_df = pd.concat([train_df, test_df])
merged_df['diff_visitId_time'] = merged_df['visitId'] - merged_df['visitStartTime']
merged_df['diff_visitId_time'] = (merged_df['diff_visitId_time'] != 0).astype('int')
del merged_df['visitId']
del merged_df['sessionId']
print("Generating date columns...")
format_str = "%Y%m%d"
merged_df['formated_date'] = merged_df['date'].apply(lambda x: datetime.strptime(str(x), format_str))
merged_df['WoY'] = merged_df['formated_date'].apply(lambda x: x.isocalendar()[1])
merged_df['month'] = merged_df['formated_date'].apply(lambda x: x.month)
merged_df['quarter_month'] = merged_df['formated_date'].apply(lambda x: x.day // 8)
merged_df['weekday'] = merged_df['formated_date'].apply(lambda x: x.weekday())
del merged_df['date']
del merged_df['formated_date']
merged_df['formated_visitStartTime'] = merged_df['visitStartTime'].apply(
lambda x: time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(x)))
merged_df['formated_visitStartTime'] = pd.to_datetime(merged_df['formated_visitStartTime'])
merged_df['visit_hour'] = merged_df['formated_visitStartTime'].apply(lambda x: x.hour)
del merged_df['visitStartTime']
del merged_df['formated_visitStartTime']
print("Encoding columns with pd.factorize()")
for col in merged_df.columns:
if col in ['fullVisitorId', 'month', 'quarter_month', 'weekday', 'visit_hour', 'Woy']:
continue
if merged_df[col].dtypes == object or merged_df[col].dtypes == bool:
merged_df[col], indexer = pd.factorize(merged_df[col])
print("Splitting back...")
train_df = merged_df[:trn_len]
test_df = merged_df[trn_len:]
return train_df, test_df
def preprocess():
train_df = load_df()
test_df = load_df(INPUT_TEST)
target = train_df['totals.transactionRevenue'].fillna(0).astype('float')
target = target.apply(lambda x: np.log1p(x))
del train_df['totals.transactionRevenue']
train_df, test_df = process_dfs(train_df, test_df)
train_df.to_csv(TRAIN, index=False)
test_df.to_csv(TEST, index=False)
target.to_csv(Y, index=False)
preprocess()
def rmse(y_true, y_pred):
# 均方根误差
return round(np.sqrt(mean_squared_error(y_true, y_pred)), 5)
def load_preprocessed_dfs(drop_full_visitor_id=True):
# 导入预处理完的数据
X_train = pd.read_csv(TRAIN, converters={'fullVisitorId': str})
X_test = pd.read_csv(TEST, converters={'fullVisitorId': str})
y_train = pd.read_csv(Y, names=['LogRevenue']).T.squeeze()
y_train = y_train[1:]
if drop_full_visitor_id:
X_train = X_train.drop('fullVisitorId', axis=1)
X_test = X_test.drop('fullVisitorId', axis=1)
return X_train, y_train, X_test
X, y, X_test = load_preprocessed_dfs()
print(X.shape)
print(y.shape)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.15, random_state=1)
print(f"Train shape: {X_train.shape}")
print(f"Validation shape: {X_val.shape}")
print(f"Test (submit) shape: {X_test.shape}")
def run_xgb(X_train, y_train, X_val, y_val, X_test):
params = {'objective': 'reg:linear', # 线性回归的学习目标
'eval_metric': 'rmse', # 均方根误差校验
'eta': 0.001, # 更新过程中用到的收缩步长
'max_depth': 10, # 树最大深度
'subsample': 0.6, # 用于训练模型的子样本占整个样本集合的比例
'colsample_bytree': 0.6, # 在建立树时对特征采样的比例
'alpha': 0.001, # L1正则化项
'random_state': 42, # 随机种子
'silent': True} # 打印模式
xgb_train_data = xgb.DMatrix(X_train, y_train)
xgb_val_data = xgb.DMatrix(X_val, y_val)
xgb_submit_data = xgb.DMatrix(X_test)
# num_boost_round进行2000次迭代,evals用于对训练过程中进行评估列表中的元素
# early_stopping_rounds早期停止次数100,验证集的误差迭代到一定程度在100次内不能再继续降低,就停止迭代。
# verbose_eval进行500次迭代输出一次
model = xgb.train(params, xgb_train_data, num_boost_round=2000,
evals=[(xgb_train_data, 'train'), (xgb_val_data, 'valid')],
early_stopping_rounds=100, verbose_eval=500)
y_pred_train = model.predict(xgb_train_data, ntree_limit=model.best_ntree_limit)
y_pred_val = model.predict(xgb_val_data, ntree_limit=model.best_ntree_limit)
y_pred_submit = model.predict(xgb_submit_data, ntree_limit=model.best_ntree_limit)
print(f"XGB : RMSE val: {rmse(y_val, y_pred_val)} - RMSE train: {rmse(y_train, y_pred_train)}")
return y_pred_submit, model
start_time = timeit.default_timer()
xgb_preds, xgb_model = run_xgb(X_train, y_train, X_val, y_val, X_test)
print('total time is:' + str(timeit.default_timer() - start_time))
运行结果
Loading /Users/admin/Downloads/ga-customer-revenue-prediction/train.csv
Loaded train.csv. Shape: (903653, 55)
Loading /Users/admin/Downloads/ga-customer-revenue-prediction/test.csv
Loaded test.csv. Shape: (804684, 53)
Processing dfs...
Dropping repeated columns...
Generating date columns...
Encoding columns with pd.factorize()
Splitting back...
(903653, 31)
(903653,)
Train shape: (768105, 31)
Validation shape: (135548, 31)
Test (submit) shape: (804684, 31)
[06:20:31] WARNING: /Users/travis/build/dmlc/xgboost/src/objective/regression_obj.cu:171: reg:linear is now deprecated in favor of reg:squarederror.
[06:20:31] WARNING: /Users/travis/build/dmlc/xgboost/src/learner.cc:573:
Parameters: { "silent" } might not be used.
This may not be accurate due to some parameters are only used in language bindings but
passed down to XGBoost core. Or some parameters are not used but slip through this
verification. Please open an issue if you find above cases.
[0] train-rmse:2.02025 valid-rmse:2.02937
[500] train-rmse:1.81049 valid-rmse:1.83542
[1000] train-rmse:1.68934 valid-rmse:1.73293
[1500] train-rmse:1.61610 valid-rmse:1.67851
[1999] train-rmse:1.56843 valid-rmse:1.64969
XGB : RMSE val: 1.6497 - RMSE train: 1.5682
total time is:669.2252929020001
XGBoost参数
General Parameters
有两中模型可以选择gbtree和gblinear。gbtree使用基于树的模型进行提升计算,gblinear使用线性模型进行提升计算。缺省值为gbtree。
取0时表示打印出运行时信息,取1时表示以缄默方式运行,不打印运行时信息。缺省值为0。
- nthread [default to maximum number of threads available if not set]
XGBoost运行时的线程数。缺省值是当前系统可以获得的最大线程数
- num_pbuffer [set automatically by xgboost, no need to be set by user]
size of prediction buffer, normally set to number of training instances. The buffers are used to save the prediction results of last boosting step.
- num_feature [set automatically by xgboost, no need to be set by user]
boosting过程中用到的特征维数,设置为特征个数。XGBoost会自动设置,不需要手工设置。
Booster Parameters
为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。 eta通过缩减特征的权重使提升计算过程更加保守。缺省值为0.3
取值范围为:[0,1]
minimum loss reduction required to make a further partition on a leaf node of the tree. the larger, the more conservative the algorithm will be.
range: [0,∞]
树的最大深度。缺省值为6
取值范围为:[1,∞]
- min_child_weight [default=1]
孩子节点中最小的样本权重和。如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。在现行回归模型中,这个参数是指建立每个模型所需要的最小样本数。该成熟越大算法越conservative
取值范围为: [0,∞]
- max_delta_step [default=0]
Maximum delta step we allow each tree’s weight estimation to be. If the value is set to 0, it means there is no constraint. If it is set to a positive value, it can help making the update step more conservative. Usually this parameter is not needed, but it might help in logistic regression when class is extremely imbalanced. Set it to value of 1-10 might help control the update
取值范围为:[0,∞]
用于训练模型的子样本占整个样本集合的比例。如果设置为0.5则意味着XGBoost将随机的冲整个样本集合中随机的抽取出50%的子样本建立树模型,这能够防止过拟合。
取值范围为:(0,1]
- colsample_bytree [default=1]
在建立树时对特征采样的比例。缺省值为1
取值范围:(0,1]
Task Parameters
- objective [ default=reg:linear ]
定义学习任务及相应的学习目标,可选的目标函数如下:
- “reg:linear” –线性回归。
- “reg:logistic” –逻辑回归。
- “binary:logistic”–二分类的逻辑回归问题,输出为概率。
- “binary:logitraw”–二分类的逻辑回归问题,输出的结果为wTx。
- “count:poisson”–计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7。(used to safeguard optimization)
- “multi:softmax” –让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数)
- “multi:softprob” –和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。没行数据表示样本所属于每个类别的概率。
- “rank:pairwise”–set XGBoost to do ranking task by minimizing the pairwise loss
- base_score [ default=0.5 ]
the initial prediction score of all instances, global bias
- eval_metric [ default according to objective ]
校验数据所需要的评价指标,不同的目标函数将会有缺省的评价指标(rmse for regression, and error for classification, mean average precision for ranking)
用户可以添加多种评价指标,对于Python用户要以list传递参数对给程序,而不是map参数list参数不会覆盖’eval_metric’
The choices are listed below:
- “rmse”: root mean square error
- “logloss”: negative log-likelihood
- “error”: Binary classification error rate. It is calculated as #(wrong cases)/#(all cases). For the predictions, the evaluation will regard the instances with prediction value larger than 0.5 as positive instances, and the others as negative instances.
- “merror”: Multiclass classification error rate. It is calculated as #(wrong cases)/#(all cases).
- “mlogloss”: Multiclass logloss
- “auc”: Area under the curve for ranking evaluation.
- “ndcg”:Normalized Discounted Cumulative Gain
- “map”:Mean average precision
- “ndcg@n”,”map@n”: n can be assigned as an integer to cut off the top positions in the lists for evaluation.
- “ndcg-”,”map-”,”ndcg@n-”,”map@n-”: In XGBoost, NDCG and MAP will evaluate the score of a list without any positive samples as 1. By adding “-” in the evaluation metric XGBoost will evaluate these score as 0 to be consistent under some conditions. training repeatively
- “gamma-deviance”: [residual deviance for gamma regression]
random number seed.
随机数的种子。缺省值为0
- dtrain:训练的数据
- num_boost_round:这是指提升迭代的次数,也就是生成多少基模型
- evals:这是一个列表,用于对训练过程中进行评估列表中的元素。形式是evals = [(dtrain,'train'),(dval,'val')]或者是evals = [(dtrain,'train')],对于第一种情况,它使得我们可以在训练过程中观察验证集的效果
- obj:自定义目的函数
- feval:自定义评估函数
- maximize:是否对评估函数进行最大化
- early_stopping_rounds:早期停止次数 ,假设为100,验证集的误差迭代到一定程度在100次内不能再继续降低,就停止迭代。这要求evals 里至少有 一个元素,如果有多个,按最后一个去执行。返回的是最后的迭代次数(不是最好的)。如果early_stopping_rounds存在,则模型会生成三个属性,bst.best_score,bst.best_iteration和bst.best_ntree_limit
- evals_result:字典,存储在watchlist中的元素的评估结果。
- verbose_eval :(可以输入布尔型或数值型),也要求evals里至少有 一个元素。如果为True,则对evals中元素的评估结果会输出在结果中;如果输入数字,假设为5,则每隔5个迭代输出一次。
- learning_rates:每一次提升的学习率的列表,
- xgb_model:在训练之前用于加载的xgb model。
XGBoost的缺点及LightGBM的优化
在LightGBM提出之前,最有名的GBDT工具就是XGBoost了,它是基于预排序方法的决策树算法。这种构建决策树的算法基本思想是:首先,对所有特征都按照特征的数值进行预排序。其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。最后,在找到一个特征的最好分割点后,将数据分裂成左右子节点。
这样的预排序算法的优点是能精确地找到分割点。但是缺点也很明显:首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如,为了后续快速的计算分割点,保存了排序后的索引),这就需要消耗训练数据两倍的内存。其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。最后,对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
为了避免上述XGBoost的缺陷,并且能够在不损害准确率的条件下加快GBDT模型的训练速度,lightGBM在传统的GBDT算法上进行了如下优化:
- 基于Histogram的决策树算法。
- 单边梯度采样 Gradient-based One-Side Sampling(GOSS):使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGBoost遍历所有特征值节省了不少时间和空间上的开销。
- 互斥特征捆绑 Exclusive Feature Bundling(EFB):使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
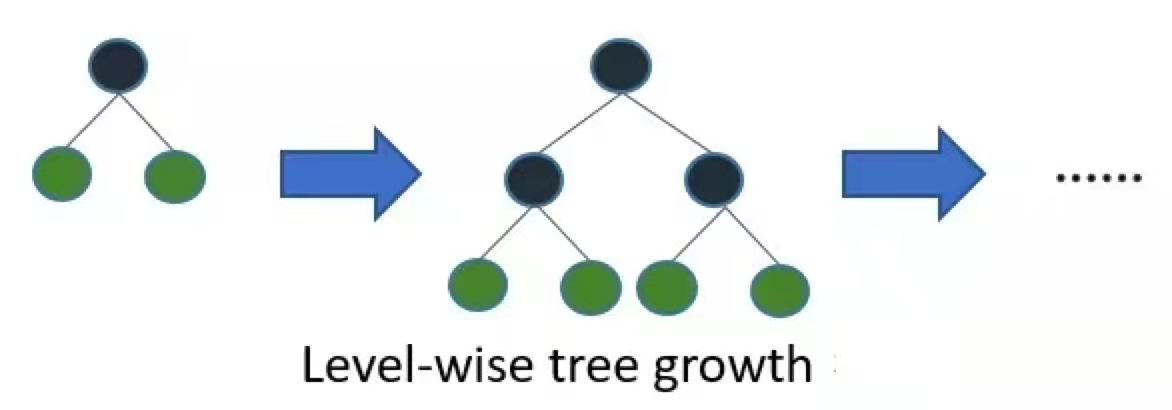
- 带深度限制的Leaf-wise的叶子生长策略:大多数GBDT工具使用低效的按层生长 (level-wise) 的决策树生长策略,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销。实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LightGBM使用了带有深度限制的按叶子生长 (leaf-wise) 算法。
- 直接支持类别特征(Categorical Feature)
- 支持高效并行
- Cache命中率优化
LightGBM的基本原理
基于Histogram的决策树算法
Histogram algorithm应该翻译为直方图算法,直方图算法的基本思想是:先把连续的浮点特征值离散化成 ![[公式]]() 个整数,同时构造一个宽度为
个整数,同时构造一个宽度为 ![[公式]]() 的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
![]()
直方图算法简单理解为:首先确定对于每一个特征需要多少个箱子(bin)并为每一个箱子分配一个整数;然后将浮点数的范围均分成若干区间,区间个数与箱子个数相等,将属于该箱子的样本数据更新为箱子的值;最后用直方图(#bins)表示。看起来很高大上,其实就是直方图统计,将大规模的数据放在了直方图中。
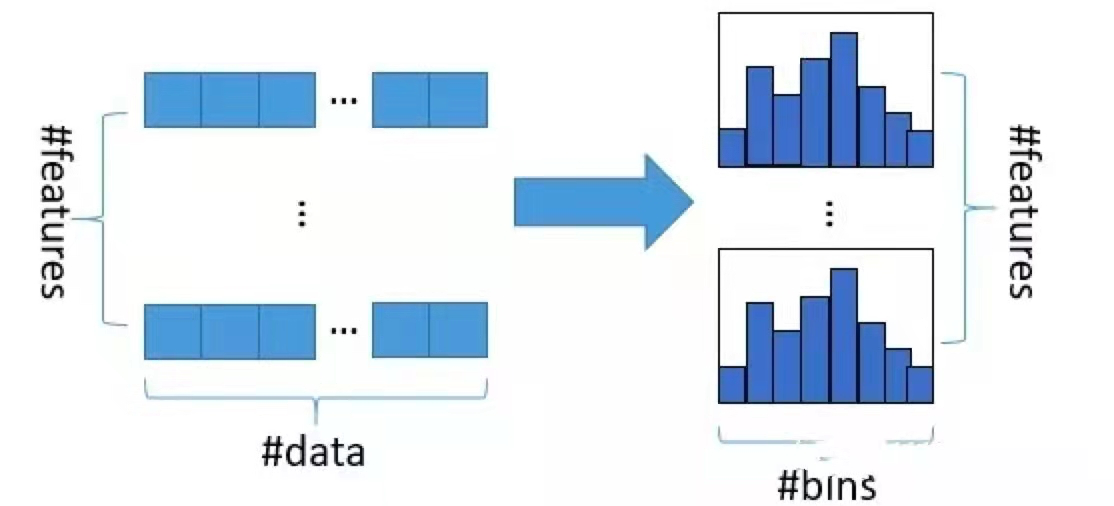
我们知道特征离散化具有很多优点,如存储方便、运算更快、鲁棒性强、模型更加稳定等。对于直方图算法来说最直接的有以下两个优点:
- 内存占用更小:直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用
![[公式]]() 位整型存储就足够了,内存消耗可以降低为原来的
位整型存储就足够了,内存消耗可以降低为原来的 ![[公式]]() 。也就是说XGBoost需要用
。也就是说XGBoost需要用![[公式]]() 位的浮点数去存储特征值,并用
位的浮点数去存储特征值,并用![[公式]]() 位的整形去存储索引,而 LightGBM只需要用
位的整形去存储索引,而 LightGBM只需要用 ![[公式]]() 位去存储直方图,内存相当于减少为
位去存储直方图,内存相当于减少为 ![[公式]]() ;
;
![]()
- 计算代价更小:预排序算法XGBoost每遍历一个特征值就需要计算一次分裂的增益,而直方图算法LightGBM只需要计算
![[公式]]() 次(
次( ![[公式]]() 可以认为是常数),直接将时间复杂度从
可以认为是常数),直接将时间复杂度从![[公式]]() 降低到
降低到![[公式]]() ,而我们知道
,而我们知道![[公式]]() 。
。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
直方图做差加速
LightGBM另一个优化是Histogram(直方图)做差加速。一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到,在速度上可以提升一倍。通常构造直方图时,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。在实际构建树的过程中,LightGBM还可以先计算直方图小的叶子节点,然后利用直方图做差来获得直方图大的叶子节点,这样就可以用非常微小的代价得到它兄弟叶子的直方图。
![]()
注意:XGBoost 在进行预排序时只考虑非零值进行加速,而 LightGBM 也采用类似策略:只用非零特征构建直方图。
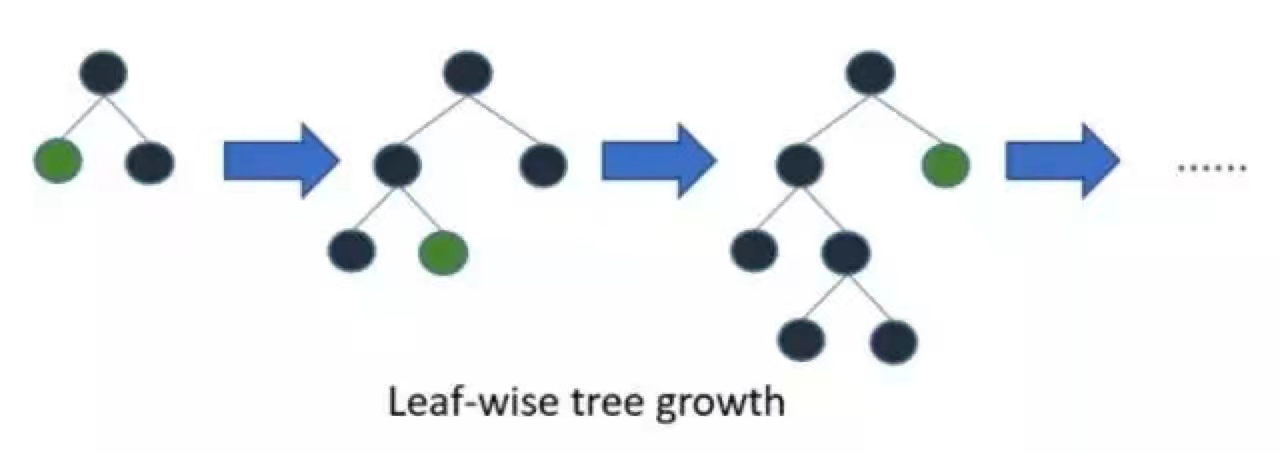
带深度限制的 Leaf-wise 算法
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法。
XGBoost 采用 Level-wise 的增长策略,该策略遍历一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂,因此带来了很多没必要的计算开销。
![]()
LightGBM采用Leaf-wise的增长策略,该策略每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,Leaf-wise的优点是:在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度;Leaf-wise的缺点是:可能会长出比较深的决策树,产生过拟合。因此LightGBM会在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
![]()