Jina —— 基于深度学习的云原生搜索框架
Jina 让你在几分钟内即可构建基于深度学习的搜索即服务。它具有以下特性: 支持所有数据类型:大规模的索引数据及查询诸如视频、图像、源代码等非结构化数据 云原生:一开始就采用分布式架构,支持容器化、分布式、数据流、并发及 REST/gRPC/WebSocket 等异步调度方式 省时:几分钟之内即可搭建一个搜索服务 架构
Join 是 SQL 中的常用操作。在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时我们就可以使用 SQL 语句中的连接(join),在两个或多个数据表中查询数据。
常用的多表连接算法主要有三类,分别是 Nested-Loop Join、Hash Join 和 Sort Merge Join。
Simple Nested-Loop Join 是最简单粗暴的 Join 算法 ,即通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有 1 万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。
在 Simple Nested-Loop Join 算法的基础上,延申出了 Index Nested-Loop Join 和 block Nested-Loop Join。前者通过减少内层表数据的匹配次数优化查询效率;后者则是通过一次性缓存外层表的多条数据,以此来减少内层表的扫表次数,从而达到提升性能的目的。
Batched Key Access Join (BKA Join) 可以看作是一个性能优化版的 Index Nested-Loop Join。之所以称为 Batched,是因为它的实现使用了存储引擎提供的 MRR(Multi-Range Read) 接口批量进行索引查询,并通过 PK 排序的方法,将随机索引回表转化为顺序回表,一定程度上加速了查索引的磁盘 IO。
两个表若是元组数目过多,逐个遍历开销就很大,Hash Join(哈希连接)是一种提高连接效率的方法。哈希连接主要分为两个阶段:建立阶段(build phase)和探测阶段(probe phase)。
在建立阶段,首先选择一个表(一般情况下是较小的那个表,以减少建立哈希表的时间和空间),对其中每个元组上的连接属性(join attribute)采用哈希函数得到哈希值,从而建立一个哈希表。
在探测阶段,对另一个表,扫描它的每一行并计算连接属性的哈希值,与 bulid phase 建立的哈希表对比,若有落在同一个 bucket 的,如果满足连接谓词(predicate)则连接成新的表。
在内存足够大的情况下,建立哈希表的整个过程都在内存中完成,完成连接操作后才放到磁盘里。因此这个过程也会带来很多的内存消耗。
Merge join 第一个步骤是确保两个关联表都是按照关联的字段进行排序。如果关联字段有可用的索引,并且排序一致,则可以直接进行 merge join 操作;否则需要先对关联的表按照关联字段进行一次排序(就是说在 merge join 前的两个输入上,可能都需要执行一个排序操作,再进行 merge join)。
两个表都按照关联字段排序好之后,merge join 操作从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。
Merge join 操作本身是非常快的,但是 merge join 前进行的排序可能会带来较大的性能损耗。
ZNBase 是由浪潮开源的一款分布式 NewSQL 数据库,其采用的 Join 算法包括 Merge join、Hash join 和 Lookup join 。
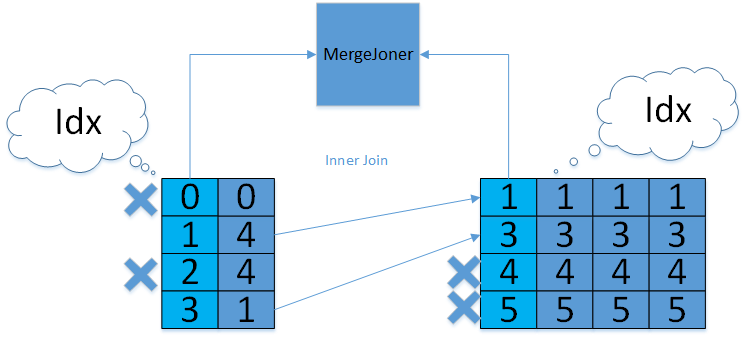
在两个表索引排序相同的情况下,Merge joins 比 Hash joins 在计算和内存方面更高效,性能更好。Merge joins 要求在相等列上索引两个表,并且索引必须具有相同的顺序。如果不满足这些条件,ZNBase 才会转向较慢的 Hash joins。
Merge joins 在两个表的索引列上执行,如下所示:
如果无法使用一个 Merge join,ZNBase 将使用一个 Hash join。Hash joins 的计算量很大,需要额外的内存。
Hash joins 在两个表上执行,如下所示:

对于普通的 join 算法,我们注意到,没有必要对于 Outer 表中每行数据,都对 Inner 表进行一次全表扫操作,很多时候可以通过索引减少数据读取的代价,这就用到了 Lookup join。
Lookup join 的适配前提是,在 join 的两个表中,Outer 表上的对应索引列存在索引。在执行过程中,首先读取小表的数据,然后去大表的索引中找到大概的 scan 范围,拿大表的数据与小表的数据比较,推进大表最后就可以得出结果。其执行过程简述如下:

Lookup Join 在执行时会不断变更状态,在不同阶段进入不同的状态做 join 处理:
阶段一: jrReadingInput 阶段
这个阶段读取小表的一块块数据,并对每一行数据开始构建对于大表的 index scan 的范围(命名为 span),构建完成后进入下一个阶段。当小表的这一块数据被读完后会回到这个状态继续读取,重复直到小表被读完。
阶段二: jrPerformingLookup 阶段
这个阶段通过阶段一得到的 span,将这个 span 中的数据取出放在一个容器中,让小表读出的一块数据每一行去这个容器中的每一行数据做 lookup 查找,执行 join 操作并将结果存储在容器中。当数据匹配完成后进入下一阶段。
阶段三: jrEmittingRows 阶段
从阶段二中的容器中取出 join 结果输出到上层。
与传统数据库相比,分布式数据库的架构有很大的不同。以 ZNBase 为例,数据库架构可以分为 SQL 层和存储层,SQL 层的计算节点需要计算数据所在的分片,然后从多个存储节点拉取所需的数据。
目前 ZNBase 采用两种办法实现分布式计算时表的关联:
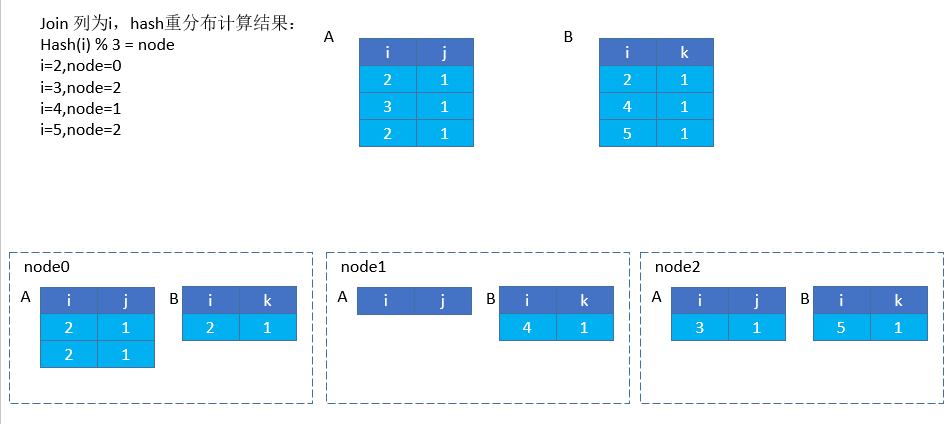
将两表按 join 的列,按 hash 特征重新分布到每个节点上。执行分布式的 join 时,如果各个执行节点的数据没有按照 join 列的特征进行分布,这个时候就会将数据进行 hash 重分布,具体操作如下:
1)选取一个 hash 函数对该行数据进行 join 列的 hash 值计算
2)对参与计算的节点数取余
根据取余结果将特定行数据分发至对应计算节点进行 join 计算。
将数据量较小的表进行广播。
相关的代价计算为:
M + N > min(M,N) * L:广播;
M + N <= min(M,N) * L:重分布。
M 和 N 分别为左右表的行数,L 为参与计算的节点个数。

总结
本文介绍了常用的多表连接 Join 算法,以及分布式数据库 ZNBase 采用的 Join 算法和分布式 Join 策略。对相关技术或产品有任何问题欢迎提 issue 或在社区中留言讨论。同时欢迎广大对分布式数据库感兴趣的开发者共同参与 ZNBase 项目的建设。
关于 ZNBase 的更多详情可以查看:ZNBase 官网:http://www.znbase.com/联系邮箱:haojingyi@inspur.com

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273