# 一、背景 某一日收到上游调用方的反馈,提供的某一个Dubbo接口,每天在固定的时间点被短时间熔断,抛出的异常信息为提供方dubbo线程池被耗尽。当前dubbo接口日请求量18亿次,报错请求94W/天,至此开始了优化之旅。 # 二、快速应急 ## 2.1 快速定位 首先进行常规的系统信息监控(机器、JVM内存、GC、线程),发现虽稍有突刺,但都在合理范围内,且跟报错时间点对不上,先暂时忽略。 其次进行流量分析,发现每天固定时间点会有流量突增的情况,流量突增的点跟报错的时间点也吻合,初步判断为短时大流量导致。 流量趋势 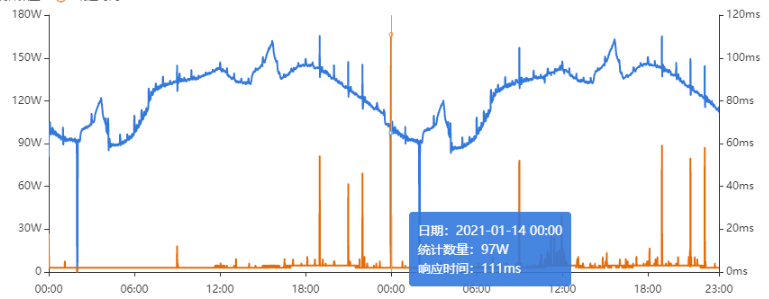 **被降级量** 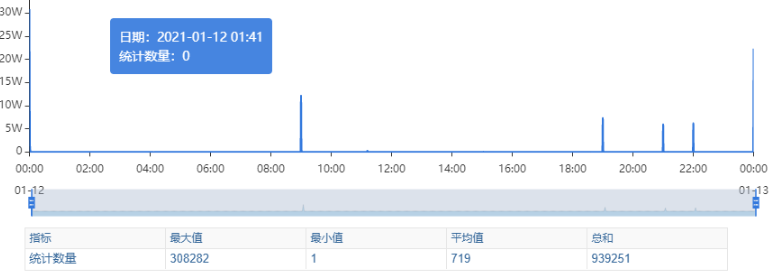 **接口99线** 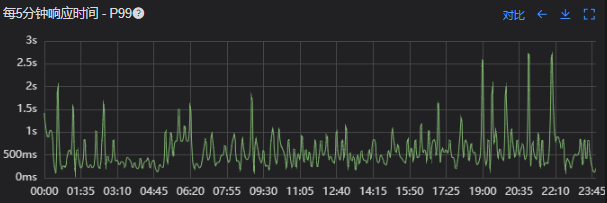 # 三、寻找性能瓶颈点 ## 3.1 接口流程分析 ### 3.1.1 流程图 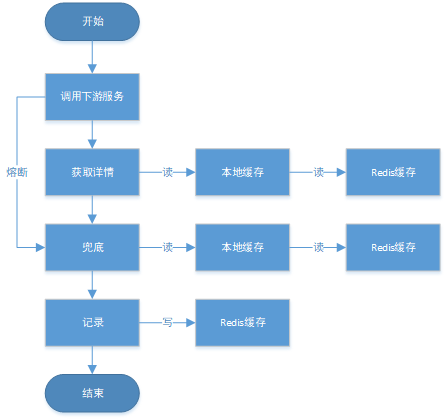 ### 3.1.2 流程分析 > 收到请求后调用下游接口,使用hystrix熔断器,熔断时间为500MS; > 根据下游接口返回的数据,进行详情数据的封装,第一步先到本地缓存中获取,如果本地缓存没有,则从Redis进行回源,Redis中无则直接返回,异步线程从数据库进行回源。 > 如果第一步调用下游接口异常,则进行数据兜底,兜底流程为先到本地缓存中获取,如果本地缓存没有,则从Redis进行回源,Redis中无则直接返回,异步线程从数据库进行回源。 ## 3.2 性能瓶颈点排查 ### 3.2.1 下游接口服务耗时比较长 调用链显示,虽然下游接口的P99线在峰值流量时存在突刺,超出1S,但因为熔断超时的设置(熔断时间500MS,coreSize&masSize=50,下游接口平均耗时10MS以下),判断下游接口不是问题的关键点,为进一步排除干扰,在下游服务存在突刺时能快速失败,调整熔断时间为100MS,dubbo超时时间100MS。 ### 3.2.2 获取详情本地缓存无数据,Redis回源 借助调用链平台,第一步分析Redis请求流量,以此来判断本地缓存的命中率,发现Redis的流量是接口流量的2倍,从设计上来说不应该出现这个现象。开始代码Review,发现在有一处逻辑出现了问题。 没有从本地缓存读取,而是直接从Redis中获取了数据,Redis最大响应时间也确实发现了不合理的突刺,继续分析发现Redis响应时间和Dubbo99线突刺情况基本一致,感觉此时已经找到了问题的原因,心中暗喜。 **Redis请求流量** 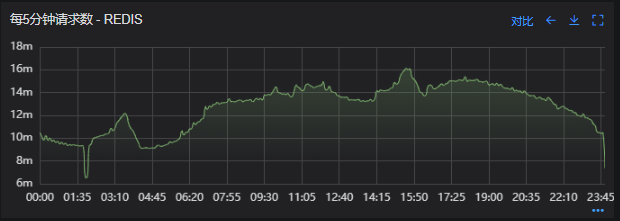 **服务接口请求流量** 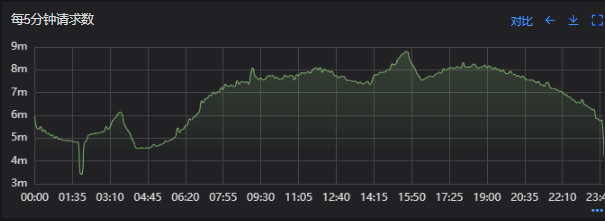 **Dubbo99线** 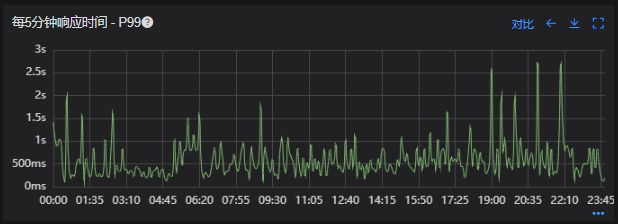 **Redis最大响应时间** 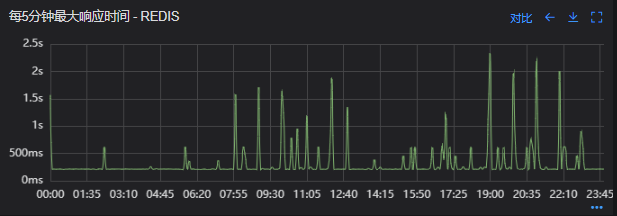 ### 3.2.3 获取兜底数据本地缓存无数据,Redis回源 正常 ### 3.2.4 记录请求结果入Redis 因为当前Redis做了资源隔离,且未在DB后台查询到慢日志,此时分析导致Redis变慢的原因有很多,不过其他的都被主观忽略了,注意力都在请求Redis流量翻倍的问题上了,故优先解决3.2.2中的问题。 # 四、解决方案 ## 4.1 3.3.2中定位的问题上线 **上线前Redis请求量**  **上线后Redis请求量** 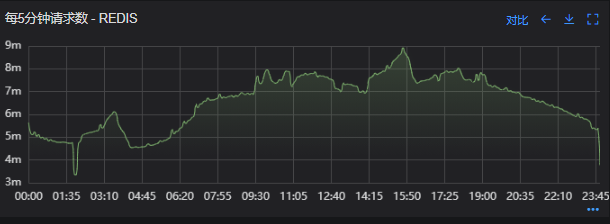 上线后Redis流量翻倍问题得到解决,Redis最大响应时间突刺有所缓解,但依旧没能彻底解决,说明大流量查询不是最根本的原因。 **redis最大响应时间(上线前)** 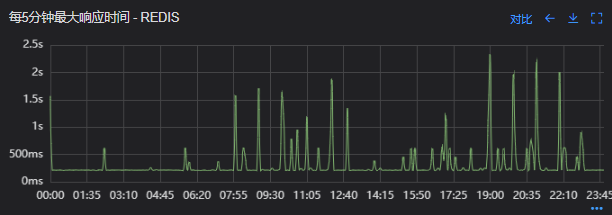 **redis最大响应时间(上线后)** 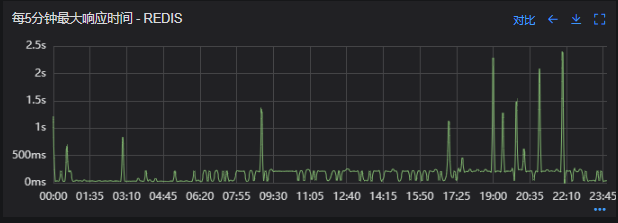 ## 4.2 Redis扩容 在Redis异常流量问题解决后,问题并未得到彻底解决,此时能做的就是静下心来,仔细去梳理导致Redis慢的原因,思路主要从以下三个方面: - 出现了慢查询 - Redis服务出现性能瓶颈 - 客户端配置不合理 基于以上思路,一个个的进行排查;查询Redis慢查询日志,未发现慢查询。 借用调用链平台详细分析慢的Redis命令,没有了大流量导致的慢查询的干扰,问题定位流程很快,大量的耗时请求在setex方法上,偶尔出现查询的慢请求也都是在setex方法之后,根据Redis单线程的特性判断setex是Redis99线突刺的元凶。找到具体语句,定位到具体业务后,首先申请扩容Redis,由6个master扩到8个master。   **Redis扩容前** 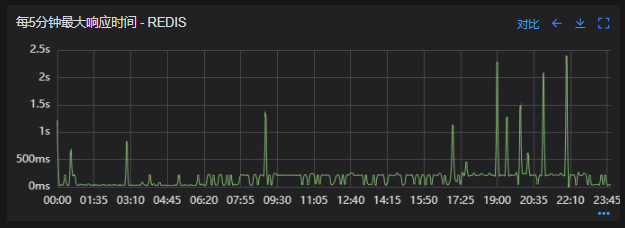 **Redis扩容后** 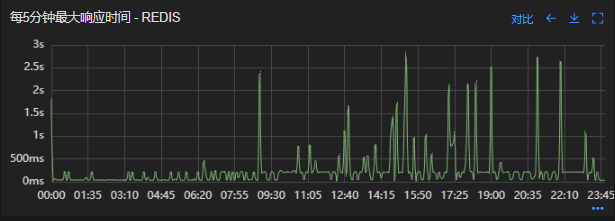 从结果上看,扩容基本上没有效果,说明redis服务本身不是性能瓶颈点,此时剩下的一个就是客户端相关配置了。 ## 4.3 客户端参数优化 ### 4.3.1 连接池优化 Redis扩容没有效果,针对客户端可能出现的问题,此时怀疑的点有两个方向。 第一个是客户端在处理Redis集群模式时,对连接的管理上存在BUG,第二个是连接池参数设置不合理,此时源码分析和连接池参数调整同步进行。 #### 4.3.1.1 判断客户端连接管理上是否有BUG 在分析完,客户端处理连接池的源码后,没有问题,跟预想一致,按照槽位缓存连接池,第一个假设被排除,源码如下。 ```java 1、setEx public String setex(final byte[] key, final int seconds, final byte[] value) { return new JedisClusterCommand
(connectionHandler, maxAttempts) { @Override public String execute(Jedis connection) { return connection.setex(key, seconds, value); } }.runBinary(key); } 2、runBinary public T runBinary(byte[] key) { if (key == null) { throw new JedisClusterException("No way to dispatch this command to Redis Cluster."); } return runWithRetries(key, this.maxAttempts, false, false); } 3、runWithRetries private T runWithRetries(byte[] key, int attempts, boolean tryRandomNode, boolean asking) { if (attempts <= 0) { throw new JedisClusterMaxRedirectionsException("Too many Cluster redirections?"); } Jedis connection = null; try { if (asking) { // TODO: Pipeline asking with the original command to make it // faster.... connection = askConnection.get(); connection.asking(); // if asking success, reset asking flag asking = false; } else { if (tryRandomNode) { connection = connectionHandler.getConnection(); } else { connection = connectionHandler.getConnectionFromSlot(JedisClusterCRC16.getSlot(key)); } } return execute(connection); } 4、getConnectionFromSlot public Jedis getConnectionFromSlot(int slot) { JedisPool connectionPool = cache.getSlotPool(slot); if (connectionPool != null) { // It can't guaranteed to get valid connection because of node // assignment return connectionPool.getResource(); } else { renewSlotCache(); //It's abnormal situation for cluster mode, that we have just nothing for slot, try to rediscover state connectionPool = cache.getSlotPool(slot); if (connectionPool != null) { return connectionPool.getResource(); } else { //no choice, fallback to new connection to random node return getConnection(); } } } ``` **4.3.1.2 分析连接池参数** 通过跟中间件团队沟通,以及参考commons-pool2官方文档修改如下; 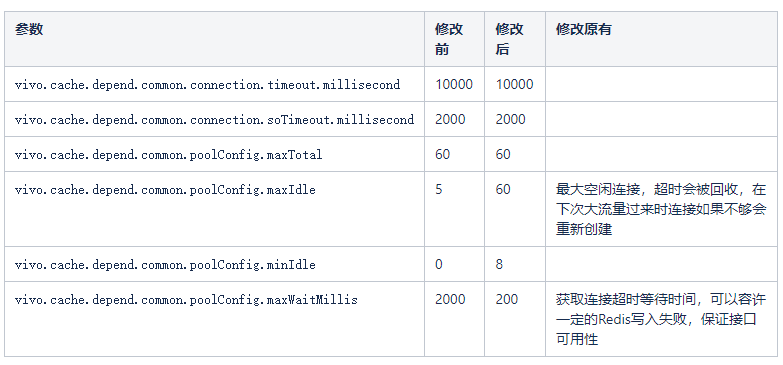 参数调整后,1S以上的请求量得到减少,但还是存在,上游反馈降级量由每天90万左右降到每天6W个(关于maxWaitMillis设置为200MS后为什么还会有超过200MS的请求,下文有解释)。 参数优化后Reds最大响应时间 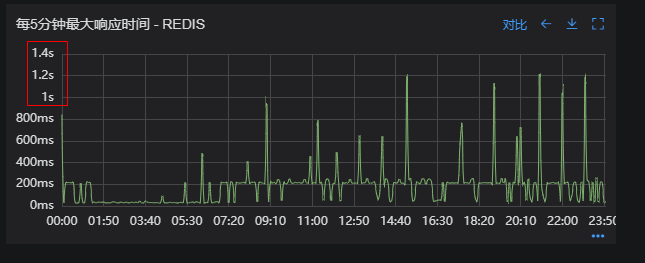 参数优化后接口报错量 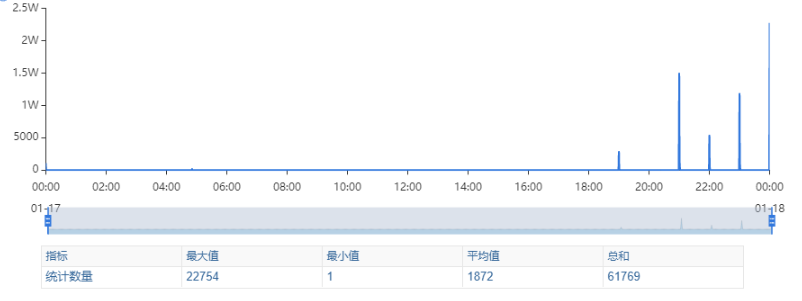 ### 4.3.2 持续优化 优化不能停止,如何把Redis的所有写入请求降低到200MS以内,此时的优化思路还是调整客户端配置参数,分析Jedis获取连接相关源码; **Jedis获取连接源码** ```java final AbandonedConfig ac = this.abandonedConfig; if (ac != null && ac.getRemoveAbandonedOnBorrow() && (getNumIdle() < 2) && (getNumActive() > getMaxTotal() - 3) ) { removeAbandoned(ac); } PooledObject
p = null; // Get local copy of current config so it is consistent for entire // method execution final boolean blockWhenExhausted = getBlockWhenExhausted(); boolean create; final long waitTime = System.currentTimeMillis(); while (p == null) { create = false; p = idleObjects.pollFirst(); if (p == null) { p = create(); if (p != null) { create = true; } } if (blockWhenExhausted) { if (p == null) { if (borrowMaxWaitMillis < 0) { p = idleObjects.takeFirst(); } else { p = idleObjects.pollFirst(borrowMaxWaitMillis, TimeUnit.MILLISECONDS); } } if (p == null) { throw new NoSuchElementException( "Timeout waiting for idle object"); } } else { if (p == null) { throw new NoSuchElementException("Pool exhausted"); } } if (!p.allocate()) { p = null; } if (p != null) { try { factory.activateObject(p); } catch (final Exception e) { try { destroy(p); } catch (final Exception e1) { // Ignore - activation failure is more important } p = null; if (create) { final NoSuchElementException nsee = new NoSuchElementException( "Unable to activate object"); nsee.initCause(e); throw nsee; } } if (p != null && (getTestOnBorrow() || create && getTestOnCreate())) { boolean validate = false; Throwable validationThrowable = null; try { validate = factory.validateObject(p); } catch (final Throwable t) { PoolUtils.checkRethrow(t); validationThrowable = t; } if (!validate) { try { destroy(p); destroyedByBorrowValidationCount.incrementAndGet(); } catch (final Exception e) { // Ignore - validation failure is more important } p = null; if (create) { final NoSuchElementException nsee = new NoSuchElementException( "Unable to validate object"); nsee.initCause(validationThrowable); throw nsee; } } } } } updateStatsBorrow(p, System.currentTimeMillis() - waitTime); return p.getObject(); ``` 获取连接的大致流程如下: > 是否有空闲连接,有空闲连接就直接返回,没有就创建; > 创建时如果超出最大连接数,则判断是否有其他线程在创建连接,如果没则直接返回,如果有则等待maxWaitMis时间(其他线程可能创建失败),如果未超出最大连接,则执行创建连接操作(此时获取连接等待时间可能会大于maxWaitMs)。 > 如果创建不成功,则判断是否是阻塞获取连接,如果不是则直接抛出异常,连接池不够用,如果是则判断maxWaitMillis是否小于0,如果小于0则阻塞等待,如果大于0则阻塞等待maxWaitMillis。 > 后续就是根据参数来判断是否需要做连接check等。 根据以上流程分析,maxWaitMills目前设置的为200,以上流程加起来最大阻塞时间为400MS,大部分情况为200MS,不应该出现超出400MS的突刺。 此时问题可能出现在创建连接上,因为创建连接比较耗时,且创建时间不定,重点分析是否有这个场景,通过DB后台监控Redis连接情况。 **DB后台监控Redis服务连接**  分析上图发现,确实在几个时间点(9:00,12:00,19:00...),redis连接数存在上涨情况,跟Redis突刺时间基本吻合。感觉(之前的各种尝试后,已经不敢用确定了)问题到此定位清晰(在突增流量过来时,连接池可用连接满足不了需求,会创建连接,造成请求等待)。 此时的想法是在服务启动时就进行连接池的创建,尽量减少新连接的创建,修改连接池参数vivo.cache.depend.common.poolConfig.minIdle,结果竟然无效??? 啥都不说了,开始撸源码,jedis底层使用的是commons-poll2来管理连接的,查看项目中使用的commons-pool2-2.6.2.jar部分源码; **CommonPool2源码** ```java public GenericObjectPool(final PooledObjectFactory
factory, final GenericObjectPoolConfig
config) { super(config, ONAME_BASE, config.getJmxNamePrefix()); if (factory == null) { jmxUnregister(); // tidy up throw new IllegalArgumentException("factory may not be null"); } this.factory = factory; idleObjects = new LinkedBlockingDeque<>(config.getFairness()); setConfig(config); } ``` 竟然发现没有初始化连接的地方,开始咨询中间件团队,中间件团队给出的源码(commons-pool2-2.4.2.jar)如下,方法执行后多了一次startEvictor方法的调用? ```java 1、初始化连接池 public GenericObjectPool(PooledObjectFactory
factory, GenericObjectPoolConfig config) { super(config, ONAME_BASE, config.getJmxNamePrefix()); if (factory == null) { jmxUnregister(); // tidy up throw new IllegalArgumentException("factory may not be null"); } this.factory = factory; idleObjects = new LinkedBlockingDeque
>(config.getFairness()); setConfig(config); startEvictor(getTimeBetweenEvictionRunsMillis()); } ``` 为啥不一样???开始检查Jar包,版本不一样,中间件给出的版本是在V2.4.2,项目实际使用的是V2.6.2,分析startEvictor有一步逻辑正是处理连接池预热逻辑。 **Jedis连接池预热** ```java 1、final void startEvictor(long delay) { synchronized (evictionLock) { if (null != evictor) { EvictionTimer.cancel(evictor); evictor = null; evictionIterator = null; } if (delay > 0) { evictor = new Evictor(); EvictionTimer.schedule(evictor, delay, delay); } } } 2、class Evictor extends TimerTask { /** * Run pool maintenance. Evict objects qualifying for eviction and then * ensure that the minimum number of idle instances are available. * Since the Timer that invokes Evictors is shared for all Pools but * pools may exist in different class loaders, the Evictor ensures that * any actions taken are under the class loader of the factory * associated with the pool. */ @Override public void run() { ClassLoader savedClassLoader = Thread.currentThread().getContextClassLoader(); try { if (factoryClassLoader != null) { // Set the class loader for the factory ClassLoader cl = factoryClassLoader.get(); if (cl == null) { // The pool has been dereferenced and the class loader // GC'd. Cancel this timer so the pool can be GC'd as // well. cancel(); return; } Thread.currentThread().setContextClassLoader(cl); } // Evict from the pool try { evict(); } catch(Exception e) { swallowException(e); } catch(OutOfMemoryError oome) { // Log problem but give evictor thread a chance to continue // in case error is recoverable oome.printStackTrace(System.err); } // Re-create idle instances. try { ensureMinIdle(); } catch (Exception e) { swallowException(e); } } finally { // Restore the previous CCL Thread.currentThread().setContextClassLoader(savedClassLoader); } } } 3、 void ensureMinIdle() throws Exception { ensureIdle(getMinIdle(), true); } 4、 private void ensureIdle(int idleCount, boolean always) throws Exception { if (idleCount < 1 || isClosed() || (!always && !idleObjects.hasTakeWaiters())) { return; } while (idleObjects.size() < idleCount) { PooledObject
p = create(); if (p == null) { // Can't create objects, no reason to think another call to // create will work. Give up. break; } if (getLifo()) { idleObjects.addFirst(p); } else { idleObjects.addLast(p); } } if (isClosed()) { // Pool closed while object was being added to idle objects. // Make sure the returned object is destroyed rather than left // in the idle object pool (which would effectively be a leak) clear(); } } ``` 修改Jar版本,配置中心增加vivo.cache.depend.common.poolConfig.timeBetweenEvictionRunsMillis(检查一次连接池中空闲的连接,把空闲时间超过minEvictableIdleTimeMillis毫秒的连接断开,直到连接池中的连接数到minIdle为止)。 vivo.cache.depend.common.poolConfig.minEvictableIdleTimeMillis(连接池中连接可空闲的时间,毫秒)两个参数,重启服务后,连接池正常预热,最终从Redis层面上解决问题。 优化结果如下,性能问题基本得到解决; **Redis响应时间(优化前)**  **Redis响应时间(优化后)** 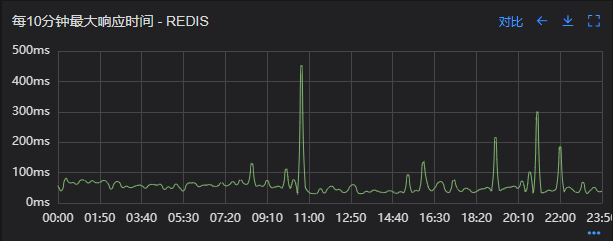 **接口99线(优化前)**  **接口99线(优化后)** 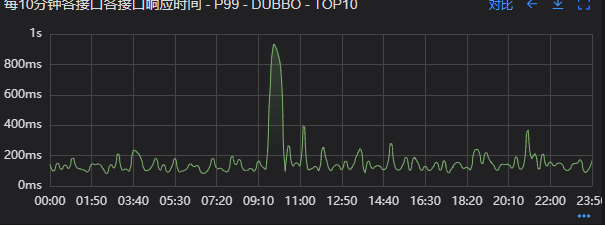 # 五、总结 出现线上问题时,首先要考虑的还是快速恢复线上业务,将业务的影响度降到最低,所以针对线上的业务,要提前做好限流、熔断、降级等策略,在线上出现问题时能快速找到恢复方案。对公司各监控平台的熟练使用程度,决定了定位问题的速度,每个开发都要把熟练使用监控平台(机器、服务、接口、DB等)作为一个基本能力。 Redis出现响应慢时,可以优先从Redis集群服务端(机器负载、服务是否有慢查询)、业务代码(是否有BUG)、客户端(连接池配置是否合理)三个方面去排查,基本上能排查出大部分Redis慢响应问题。 Redis连接池在系统冷启动时,对连接池的预热,不同commons-pool2的版本,冷启动的策略也不同,但都需要配置minEvictableIdleTimeMillis参数才会生效,可以看下common-pool2官方文档,对常用参数都做到心中有数,在问题出现时能快速定位。 连接池默认参数在解决大流量的业务上稍显乏力,需要针对大流量场景进行调优处理,如果业务上流量不是很大直接使用默认参数即可。 具体问题要具体分析,不能解决问题的时候要变通思路,通过各种方法去尝试解决问题。 > 作者:vivo互联网服务器团队-Wang Shaodong
