背景
外呼系统需要每天处理几百万外呼 ,短信 , 等任务,而系统并发有限。因此任务需要排队执行,不同的任务有不同的优先级,因为需要引入优先级队列。
队列选型
不考虑引入新的中间件,目前系统可以实现优先级的中间件有 RabbitMQ 和 redis。而业务需求比较麻烦,需要可以根据条件删除优先级队列里的数据 ,数据可以容忍在极端情况下丢失(redis集群不可用 mongodb不可用), RabbitMQ不符合业务场景, 因此决定使用 redis + mongoDB实现优先级队列
具体实现
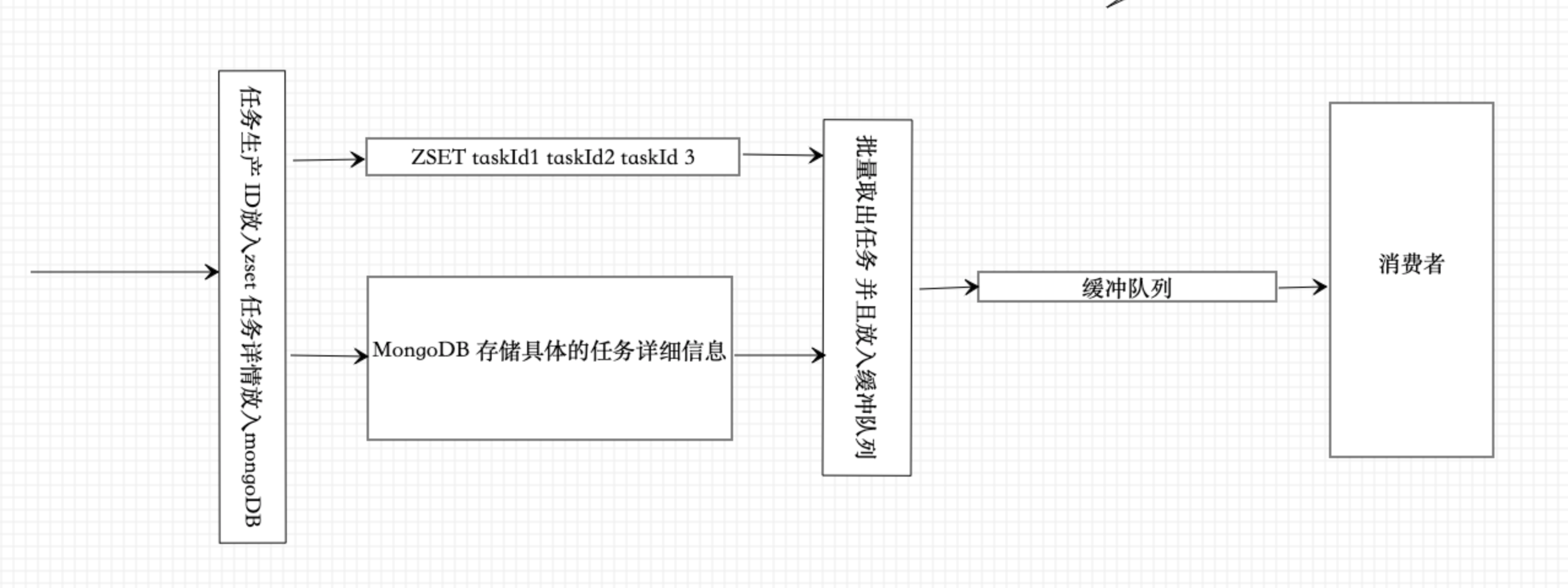
具体中使用了zset数据类型,zset的分数作为优先级。具体任务的id存在了zset中,任务携带的数据存在了mongoDB中。id使用了 SnowFlake 算法生成,又保证了同一优先级下的任务可以根据先后顺序执行。
zset没有提供 list类型LPOP等原子性的弹出元素的操作,因此加入和取出都需要你加锁。因此给予redis实现了分布式锁 实际使用时每个队列都有自己对应的锁。
public static void lock(String key){
String redisKey= RedisKey.LOCK+key;
long id=Thread.currentThread().getId();
String value=String.valueOf(id);
for (int i=0;i<TRY;i++){
Boolean res= stringRedisTemplate.opsForValue().setIfAbsent(redisKey,value,30,TimeUnit.SECONDS);
if (Boolean.TRUE.equals(res)){
return;
}
ThreadUtil.sleep(100,TimeUnit.MINUTES);
}
}
- 任务加入 zset
public void pushPriorityQueue(String queueName, List<Long> resultIdList, Integer priority){
Set<ZSetOperations.TypedTuple<Long>> set= Sets.newHashSet();
Double score=priority.doubleValue();
for (Long resultId:resultIdList){
ZSetOperations.TypedTuple<Long> z=new DefaultTypedTuple<>(resultId,score);
set.add(z);
}
try {
RedisLock.lock(queueName);
resultRedisTemplate.opsForZSet().add(queueName,set);
}finally {
RedisLock.unlock(queueName);
}
}
2.任务在zset中取出
public List<Long> popPriorityQueue(String queueName){
try {
RedisLock.lock(queueName);
Set<Long> resultIdSet= resultRedisTemplate.opsForZSet().range(queueName,0, Constant.QUEUE_SIZE);
resultRedisTemplate.opsForZSet().removeRange(queueName,0,Constant.QUEUE_SIZE);
if (resultIdSet!=null){
return Lists.newArrayList(resultIdSet);
}
}finally {
RedisLock.unlock(queueName);
}
return null;
}
为提高性能,在实际项目中还存在缓冲队列,系统在优先级队列中取数据每次批量取出,放入缓冲队列中 整个流图如下 。
![]()
下一步会在缓冲队列前引入filter概念,用来实现复杂的逻辑。比如阻断机器人和某个用户的所有联系方式,比如发短信 邮件 电话等等。
实际生产环境中,还会根据业务特性,增加各种补偿机制 。
完结