前提概要
如果没有冬天,春天不会如此悦人;如果没有偶尔的不幸,幸运不会如此受人欢迎。
CMS垃圾回收的6个重要阶段
-
initial-mark 初始标记(CMS的第一个STW阶段),标记GC Root直接引用的对象,GC Root直接引用的对象不多,所以很快。
-
concurrent-mark并发标记阶段,由第一阶段标记过的对象出发,所有可达的对象都在本阶段标记。
-
concurrent-preclean 并发预清理阶段,也是一个并发执行的阶段。在本阶段,会查找前一阶段执行过程中,[从新生代晋升或新分配或被更新的对象]。通过并发地重新扫描这些对象,预清理阶段可以减少下一个stop-the-world 重新标记阶段的工作量。
-
concurrent-abortable-preclean,并发可中止的预清理阶段。这个阶段其实跟上一个阶段做的东西一样,也是为了减少下一个STW重新标记阶段的工作量。增加这一阶段是为了让我们可以控制这个阶段的结束时机,比如扫描多长时间(默认5秒)或者Eden区使用占比达到期望比例(默认50%)就结束本阶段。
-
remark重标记阶段(CMS的第二个STW阶段),暂停所有用户线程,从GC Root开始重新扫描整堆,标记存活的对象。需要注意的是,虽然CMS只回收老年代的垃圾对象,但是这个阶段依然需要扫描新生代,因为很多GC Root都在新生代,而这些GC Root指向的对象又在老年代,这称为“跨代引用”。
-
concurrent-sweep ,并发清理。
分析
分析其GC日志,发现GC发生在CMS的收集阶段。
![]()
-
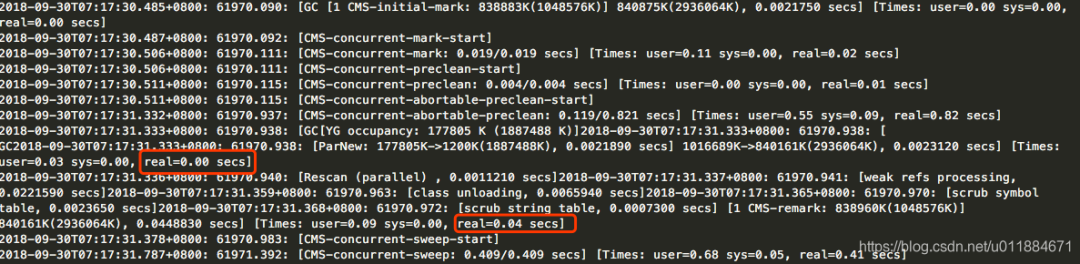
箭头1 显示abortable-preclean阶段耗时4.04秒。
-
箭头2 显示的是remark阶段,耗时0.11秒。
-
虽然abortable-preclean阶段是concurrent的,不会暂停其他的用户线程。就算不优化,可能影响也不大。
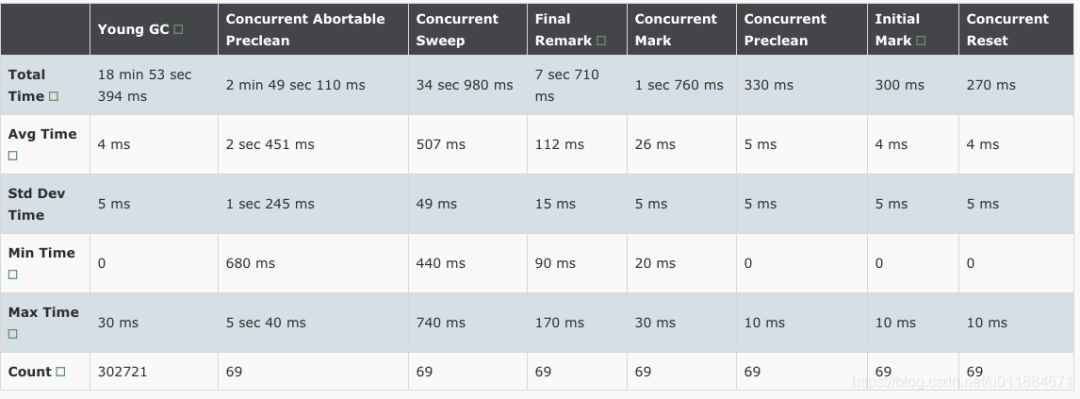
调优之前先看下该应用的GC统计数据,包括GC次数,耗时:
![]()
统计期间内(18天)发生CMS GC 69次,其中abortable preclean阶段平均耗时2.45秒,final remark阶段平均112ms,最大耗时170ms。
优化目标
降低abortable preclean时间,而且不增加final remark的时间(因为remark是STW的)。
JVM参数调优
第一次调优
先尝试调低abortable preclean阶段的时间,看看效果。
有两个参数可以控制这个阶段何时结束:
-XX:CMSMaxAbortablePrecleanTime=5000
默认值5s,代表该阶段最大的持续时间
-XX:CMSScheduleRemarkEdenPenetration=50
默认值50%,代表Eden区使用比例超过50%就结束该阶段进入remark
调整为最大持续时间为1s,Eden区使用占比10%,如下:
-XX:CMSMaxAbortablePrecleanTime=1000
-XX:CMSScheduleRemarkEdenPenetration=10
为什么调整成这样两个值:首先每次CMS都发生在老年代使用占比达到80%时,因为这是由下面两个参数决定的:
-XX:CMSInitiatingOccupancyFraction=80
-XX:+UseCMSInitiatingOccupancyOnly
这两个设置一般配合使用,一般用于『降低CMS GC频率或者增加频率、减少GC时长』的需求
-
-XX:CMSInitiatingOccupancyFraction=80 是指设定CMS在对内存占用率达到80%的时候开始GC(因为CMS会有浮动垃圾,所以一般都较早启动GC);
-
-XX:+UseCMSInitiatingOccupancyOnly :标志来命令JVM不基于运行时收集的数据来启动CMS垃圾收集周期。
当该标志被开启时,JVM通过CMSInitiatingOccupancyFraction的值进行每一次CMS收集,而不仅仅是第一次。(否则后续会动态控制回收阈值)
(慎用) 因此,只有当我们充足的理由(比如测试)并且对应用程序产生的对象的生命周期有深刻的认知时,才应该使用该标志。
老年代的增长是由于部分对象在Minor GC后仍然存活,被晋升到老年代,导致老年代使用占比增长的,也就是在每次CMS GC发生之前刚刚发生过一次Minor GC,所以在那一刻新生代的使用占比是很低的。
那么我们预计这个时候尽快结束abortable preclean阶段,在remark时就不需要扫描太多的Eden区对象,remark STW的时间也就不会太长。
第一次调整参数
![]()
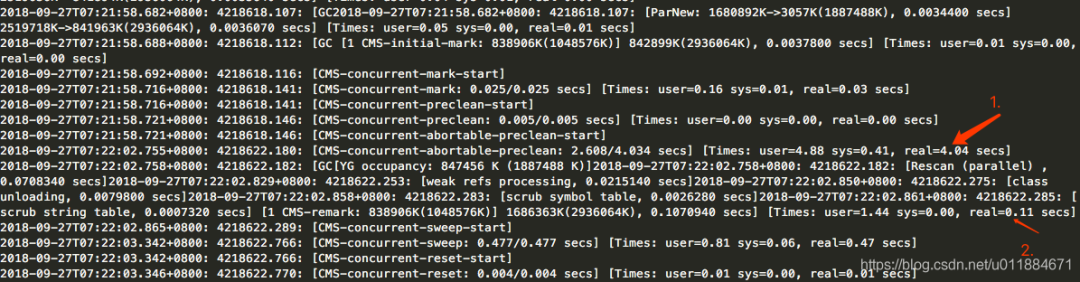
在统计期间(17小时左右)内,发生过2次CMS GC。Abortable Preclean 平均耗时835ms,这是预期内的。但是Final Remark 平均耗时495ms(调整前是112ms),其中一次是80ms,另一次是910ms!将近1秒钟!Remark是STW的!对于要求低延时的应用来说这是无法接受的!
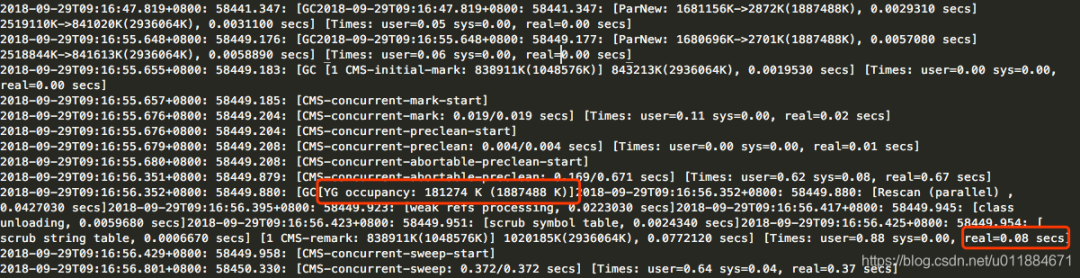
![]()
[YG occupancy: 181274 K (1887488 K)] - 年轻代当前占用情况和总容量
耗时80ms的这次remark发生时(早上9点,非高峰时段),新生代(YG)占用181.274M。
remark耗时910ms的那次GC日志
[YG occupancy: 773427 K (1887488 K)]
耗时910ms的这次remark发生时(晚上10点左右,高峰时段),新生代(YG)占用773.427M。因为这个时候高峰期,新生代的占用量上升的非常快,几乎同样的时间内,非高峰时段仅上升到181M,但是高峰时段就上升到773M。
对于这种情况,CMS提供了CMSScavengeBeforeRemark参数,尝试在remark阶段之前进行一次Minor GC,以降低新生代的占用。
第二次调优
增加 -XX:+CMSScavengeBeforeRemark 不是没有代价的,因为这会增加一次Minor GC停顿。所以这个方案好或者不好的判断标准就是:增加CMSScavengeBeforeRemark参数之后的minor GC停顿时间 + remark 停顿时间如果比增加之前的remark GC停顿时间要小,这才是好的方案。
-XX:+CMSScavengeBeforeRemark: 在CMS GC前启动一次ygc,目的在于减少old gen对ygc gen的引用,降低remark时的开销-----一般CMS的GC耗时 80%都在remark阶段
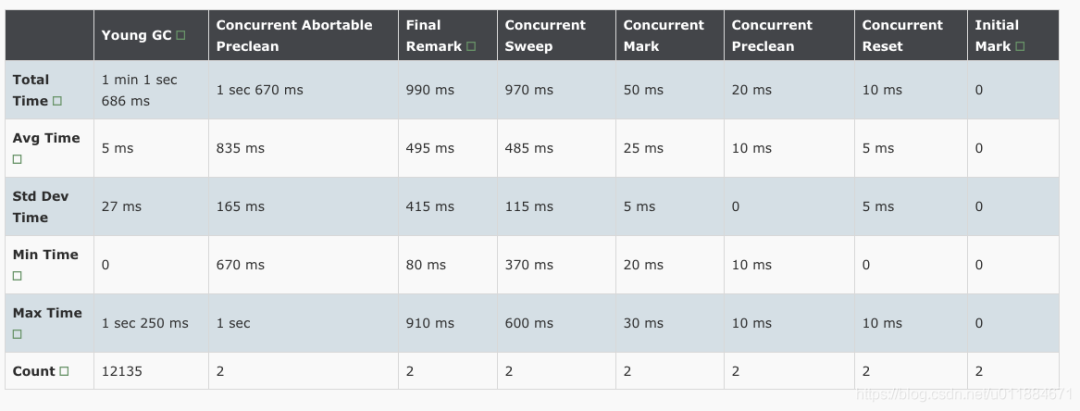
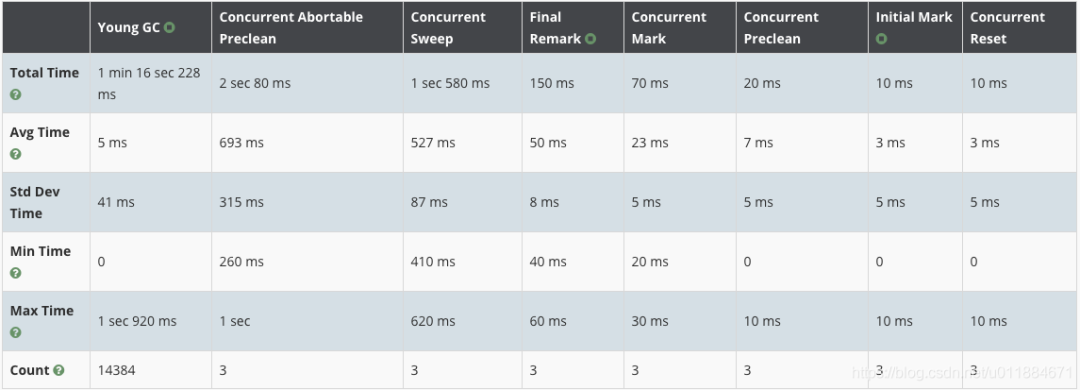
第二次调整的结果
在统计期间(20小时左右)内,发生3次CMS GC。Abortable preclean 平均耗时693ms。Final remark平均耗时50ms,最大耗时60ms。Final remark的时间比调优前的平均时间(112ms)更低。
![]() 3次CMS GC remark前的Minor GC日志分析
3次CMS GC remark前的Minor GC日志分析
第1次是非高峰时段的表现,Minor GC 耗时 0.01s + remark耗时 0.06s = 0.07s = 70ms,如下 ![]() 第2次是高峰时段,Minor GC 耗时 0.01s + remark耗时 0.05s = 0.06s = 60ms,如下
第2次是高峰时段,Minor GC 耗时 0.01s + remark耗时 0.05s = 0.06s = 60ms,如下 ![]() 第3次是非高峰时段,Minor GC 耗时 0.00s + remark耗时 0.04s = 0.04s = 40ms,如下
第3次是非高峰时段,Minor GC 耗时 0.00s + remark耗时 0.04s = 0.04s = 40ms,如下 ![]()
所以,3次Minor GC + remark耗时的平均耗时 < 60ms,这比第一次调优时remark平均耗时495ms好得多了。
总结
解决abortable preclean 时间过长的方案可以归结为两步:
缩短abortable preclean 时长,通过调整这两个参数:
-XX:CMSMaxAbortablePrecleanTime=xxx
-XX:CMSScheduleRemarkEdenPenetration=xxx
-
调整为多少的一个判断标准是:abortable preclean阶段结束时,新生代的空间占用不能大于某个参考值。 在前面第一次调优后,新生代(YG)占用181.274M,remark耗时80ms;新生代(YG)占用773.427M时,remark耗时910ms。所以这个参考值可以是300M。
-
而如果新生代增长过快,像这次调优应用2秒内就能用光2G新生代堆空间的,就只能通过CMSScavengeBeforeRemark做一次Minor GC了。
增加CMSScavengeBeforeRemark参数开启remark前进行Minor GC的尝试
虽然官方说明这个增加这个参数是尝试进行Minor GC,不一定会进行。但实际使用起来,几乎每次remark前都会Minor GC。
 3次CMS GC remark前的Minor GC日志分析
3次CMS GC remark前的Minor GC日志分析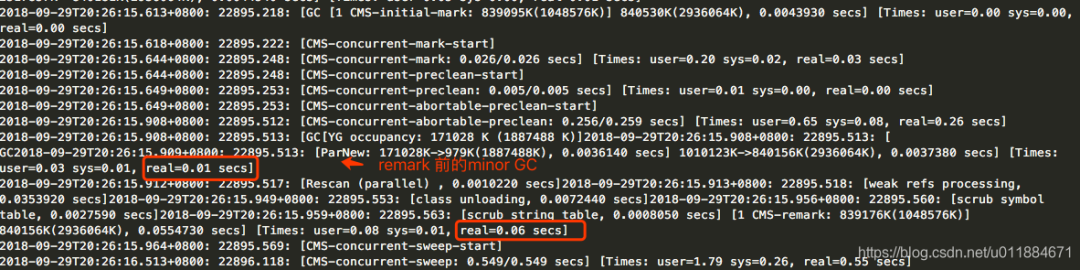 第2次是高峰时段,Minor GC 耗时 0.01s + remark耗时 0.05s = 0.06s = 60ms,如下
第2次是高峰时段,Minor GC 耗时 0.01s + remark耗时 0.05s = 0.06s = 60ms,如下  第3次是非高峰时段,Minor GC 耗时 0.00s + remark耗时 0.04s = 0.04s = 40ms,如下
第3次是非高峰时段,Minor GC 耗时 0.00s + remark耗时 0.04s = 0.04s = 40ms,如下