PyTorch 1.9 现已发布,该版本包含了自 1.8 以来的 3400 多个 commit ,有 398 位贡献者参与更新。主要亮点内容包括:
- 支持科学计算方面的重大改进,现已支持 torch.linalg、torch.special 以及 Complex Autograd;
- 使用 Mobile Interpreter 对设备上的二进制大小进行重大改进;
- 通过 TorchElastic 向 PyTorch Core 上游提供对弹性容错训练的本地支持;
- PyTorch RPC 框架的更新,以支持 GPU 的大规模分布式训练;
- 为模型推理部署优化性能和封装的新 API;
- 支持 PyTorch Profiler 中的分布式训练、GPU 利用率和 SM efficiency。
![]()
除了 PyTorch 1.9 外,PyTorch 团队还发布了针对 PyTorch 库的重大更新,点此查看关于库更新的详细消息。
PyTorch 版本中的功能分为稳定版 (Stable)、测试版 (Beta) 和原型版 (Prototype)。
前端 API
在 1.9 版本中,torch.linalg 模块正在向稳定版本过渡。线性代数对于深度学习和科学计算至关重要,torch.linalg 模块扩展了 PyTorch 对线性代数的支持,实现了 NumPy 的线性代数模块(现在支持 accelerators 和 autograd)中的每一个函数等等。
- (Stable) Complex Autograd
在 PyTorch 1.8 中作为测试版发布的 Complex Autograd 功能现在已经稳定。自测试版发布以来,开发团队在 PyTorch 1.9 中为 98% 以上的运算符扩展了对 Complex Autograd 的支持,通过增加更多的 OpInfos 改进了对复杂运算符的测试,并通过 TorchAudio 迁移到本地复杂张量增加了更多的验证。
该功能为用户提供了计算复杂梯度和优化具有复杂变量的实值损失函数的功能。
- (Stable) torch.use_deterministic_algorithms()
为了帮助调试和编写可重现的程序,PyTorch 1.9 增加了一个 torch.use_determinstic_algorithms 选项。启用此设置后,如果可能,操作的行为将是确定性的;如果操作的行为不可确定,则抛出运行时错误。举例如下:
>>> a = torch.randn(100, 100, 100, device='cuda').to_sparse()
>>> b = torch.randn(100, 100, 100, device='cuda')
# Sparse-dense CUDA bmm is usually nondeterministic
>>> torch.bmm(a, b).eq(torch.bmm(a, b)).all().item()
False
>>> torch.use_deterministic_algorithms(True)
# Now torch.bmm gives the same result each time, but with reduced performance
>>> torch.bmm(a, b).eq(torch.bmm(a, b)).all().item()
True
# CUDA kthvalue has no deterministic algorithm, so it throws a runtime error
>>> torch.zeros(10000, device='cuda').kthvalue(1)
RuntimeError: kthvalue CUDA does not have a deterministic implementation...
类似于 SciPy 的 special 模块的 torch.special 模块,现在是测试版本。这个模块包含了许多对科学计算和处理 IV、VE、ERFCX、logerfc 和 logerfcx 等分布有用的功能。
PyTorch Mobile
- (Beta) Mobile Interpreter
PyTorch 团队正在发布 Beta 版 Mobile Interpreter,一个 PyTorch 运行时的简化版本。Interpreter 将在边缘设备中执行 PyTorch 程序,减少二进制大小的占用。
从 PyTorch 1.9 开始,用户可以在 iOS/Android 应用程序上使用 TorchVision 库。Torchvision 库包含了 C++ 的 Torchvision 操作,需要与 iOS 的主 PyTorch 库链接在一起,对于 Android,可以将其作为一个 gradle 依赖添加。这允许使用 TorchVision 预先构建的 MaskRCNN 操作符进行对象检测和分割。
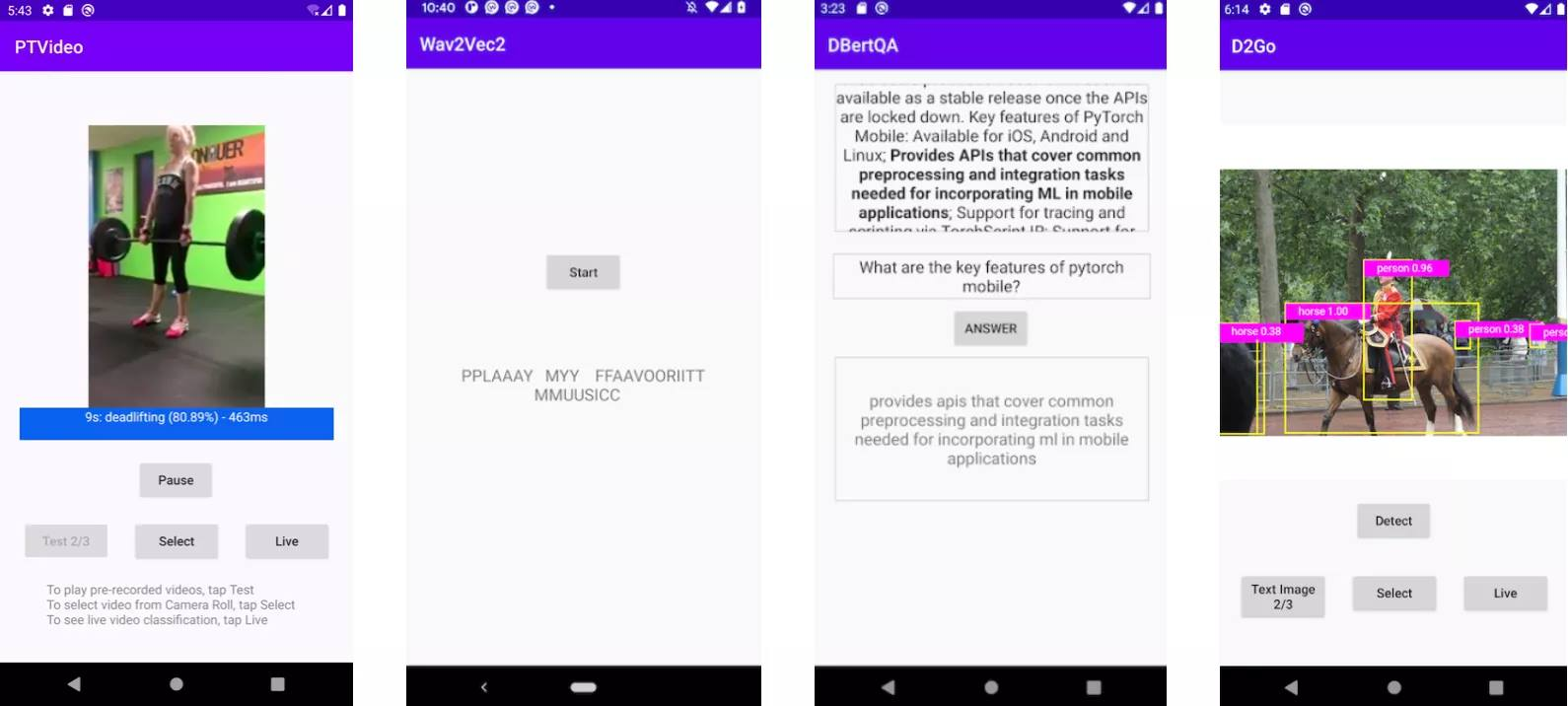
PyTorch 团队正在发布一个基于 PyTorch Video 库的新视频应用程序和一个基于最新 torchaudio、wave2vec 模型的更新语音识别应用程序。这两个版本都可以在 iOS 和 Android 上使用。此外,研究团队还更新了 7 个计算机视觉和 3 个自然语言处理演示应用程序,包括 HuggingFace DistilBERT 和 DeiT Vision transformer 模型,以及 PyTorch Mobile v1.9。随着这两个应用程序的加入,现在提供了一整套演示应用程序,包括图像、文本、音频和视频。
![]()
分布式训练
TorchElastic 现在是 PyTorch 的一个核心功能,它能够让用户在抢占式实例上运行分布式训练,而不需要 gang scheduler。开发团队还添加了一个基于 c10d::Store 的“独立”集合点,能够在本地支持弹性、容错分布式训练。 除 TorchElastic 外,现在还可在 RPC 中支持 CUDA,并支持对分布式训练进行分析等。
性能优化和工具
模块冻结是将模块参数和属性值作为常量内联到 TorchScript 内部表示中的过程。这允许进一步优化和专门化程序,包括 TorchScript 优化。optimize_for_mobile API、ONNX 等都使用了这种方法。 官方建议在部署模型时进行 Freezing。
![]()
新的 PyTorch Profiler 已升级到测试版,并利用 Kineto 进行 GPU 分析,利用 TensorBoard 进行可视化。
PyToch 1.9 对 torch.profiler API 的支持扩展到更多版本,包括 Windows 和 Mac;并在大多数情况下推荐使用,而不是以前的 torch.autograd.profiler API。新 API 支持现有的 profiler 功能,与 CUPTI 库(仅限 Linux)集成,跟踪设备上的 CUDA 内核,并支持长期运行作业,例如:
def trace_handler(p):
output = p.key_averages().table(sort_by="self_cuda_time_total", row_limit=10)
print(output)
p.export_chrome_trace("/tmp/trace_" + str(p.step_num) + ".json")
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
# schedule argument specifies the iterations on which the profiler is active
schedule=torch.profiler.schedule(
wait=1,
warmup=1,
active=2),
# on_trace_ready argument specifies the handler for the traces
on_trace_ready=trace_handler
) as p:
for idx in range(8):
model(inputs)
# profiler will trace iterations 2 and 3, and then 6 and 7 (counting from zero)
p.step()
PyTorch Profiler Tensorboard 插件具有以下新功能:
- 带有 NCCL 通信概览的分布式训练摘要视图
- 跟踪视图和 GPU operators 视图中的 GPU 利用率和 SM efficiency
- 内存分析视图
- 从 Microsoft VSCode 启动时跳转到源代码
- 能够从云对象存储系统中进行负载跟踪
更多详情可查看:https://pytorch.org/blog/pytorch-1.9-released/