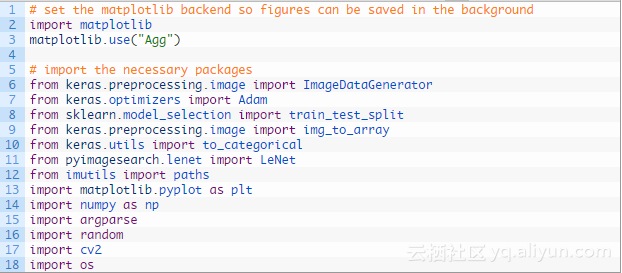
首发地址:https://yq.aliyun.com/articles/288077
2017年已到最后一个月的尾巴,那圣诞节还会远吗?不知道各位对于圣诞节有什么安排或一些美好的回忆,我记得最清楚的还是每年圣诞节前一晚那些包装好的苹果,寓意平平安安。那谈到圣诞节,不可或缺的主角——“圣诞老人”会出现在各地的大街小巷、各种画册上,本文将带领读者使用Keras完成“圣诞老人”图像的分类,算是圣诞节前的预热活动吧。
![ca45244ee5e44c57cd134224a63a939d2267c6ad]()
在介绍正式内容前,读者可以先看这篇内容:
如何利用谷歌图片获得训练数据
在本教程的第一部分,将介绍本文使用的数据集;其次使用Python和Keras训练一个卷积神经网络模型,该模型能够检测一个图像中是否存在圣诞老人,
所选的网络结构类似于LeNet网络;最后,在一系列的图像上评估本文搭建的模型,然后讨论一下本文方法的局限性以及如何拓展等。
“圣诞老人”和“非圣诞老人”数据集
为了训练搭建的模型,本文需要两类图像集:
- 图像含圣诞老人(“圣诞老人”);
- 图像不包含圣诞老人(“不是圣诞老人”)
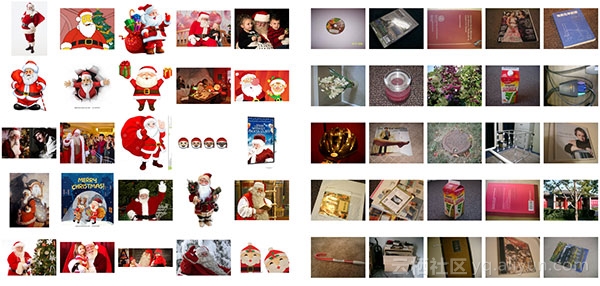
上周我们用谷歌图片迅速获取训练图像数据集,数据集中包含461张有圣诞老人的图像中,如图1(左)所示;此外从UKBench数据集中随机获取461张不包含圣诞老人,如图1(右)所示。
基于卷积神经网络和Keras搭建的第一个图像分类器
![150719573d00f7ad726c7858acff2dcaccefdf8f]()
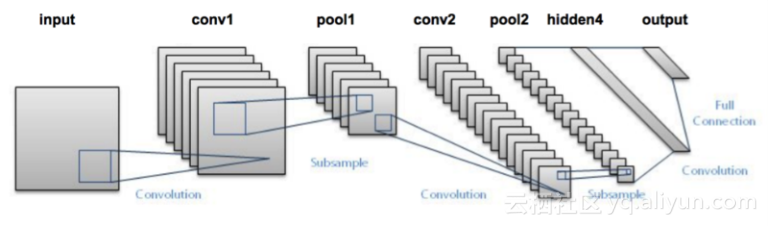
如图2所示,该图是一个典型的Lenet网络结构,最初被用来数字手写体的分类,现将其扩展到其他类型的图像。
本教程主要是介绍如何将深度学习应用于图像分类中,所以不会对Keras和Python语句介绍得非常详细,感兴趣的读者可以看下Deep Learning for Computer Vison with Python这本书。
首先先定义网络架构。创建一个新文件并命名为lenetpy,并插入以下代码:
![7e098bc8c6debdac033d14903c51fbbdb900cf74]()
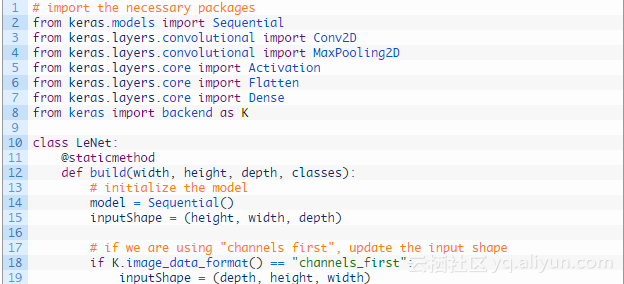
第2-8行是需要导入的Python包,其中conv2d表示执行卷积,maxpooling2d表示执行最大池化,Activation表示特定的激活函数类型,Flatten层用来将输入“压平”,用于卷积层到全连接层的过渡,Dense表示全连接层。
真正创建Lenet网络结构是代码的第10-12行,每当定义了一个新的卷积神经网络结构时,我喜欢:
- 把它放在自己的类中(为了命名空间及便于组织)
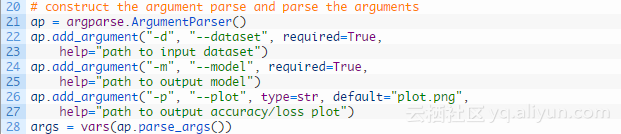
- 创建一个静立建造函数,来完成整个模型的建立
建立的模型时需要大量的参数:
- weight:输入图像的宽度
- height:输入图像的高度
- depth:输入图像的通道数(1表示单通道图像灰度,3表示标准的RGB图像)
- claclasses:想要组织的层类别总数
第1第4行定义我们的模型,第15行初始化inputshape,第18-19行正常更新inputshape
现在我们已经初始化我们的模型,可以开始添加其它层,代码如下:
![4ec53448ee702e6d428bed68ebc346d593f6e1e1]()
第21-25行创建第一个CONV->RELU->POOL层,卷积层使用20个大小5x5的滤波器,之后紧跟RELU激活函数,最后使用窗口大小为2x2的最大池化操作;
之后定义第二个CONV->RELU->POOL层:
![a4f0b0625b6df7469b472232754ba2c791b3cf3d]()
这次卷积层使用50个滤波器,滤波器个数的增加加深整个网络体系结构。
最终的代码块是将数据“压平”以连接全连接层:
![5b700e1a6f1914ef441931c2b6e9d1cbef63871d]()
第33行能将maxpooling2d层的输出压扁成一个单向量;
第34行显示全连接层包含500个节点,然后紧跟一个ReLU激活函数;
第38行定义另一个全连接层,该层的节点数等于分类的类别数,Dense
层送入softmax分类器输出每类的概率值;
第42行返回模型的调用函数;
使用Keras训练卷积神经网络图像分类器
打开一个新的文件并命名为train_networkpy,并插入以下代码打开
![a48db281781b1c5c56b2e69232e0ecb5237a0e5b]()
第2 - 18行导入程序需要的数据包;
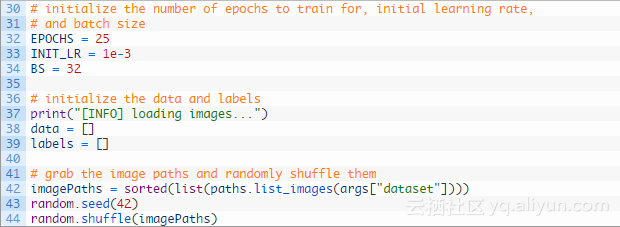
下面开始解析命令行参数:
![cd76407f865d888a849b1af970e6d8c3a81e3181]()
这里有两个需要命令行参数,--dataset和--model,以及accuracy/loss图的路径选择。其中--dataset表示模型的训练集,--model表示训练分类器后保存的模型,如果--plot未指定,则默认为plot.PNG。
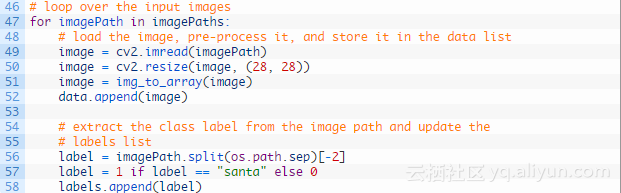
接下来,设置一些训练变量、初始化列表并设置图像路径:
![da8f4c1fc977e644724810074f81ceb9f926b3c1]()
第32-34行定义模型的训练次数、初始学习率以及批量大小;
第38和39行初始化数据和标签列表,这些列表对应存储图像以及类别标签;
第42-44行获取输入图像路径并将图像随机打乱;
现在对图像进行预处理:
![291e97447a8e5e621f674e0947fa3f36a866c5b0]()
该循环简单的将每个图像的尺寸重新调整为28×28大小(为LeNet所需要的空间尺寸)
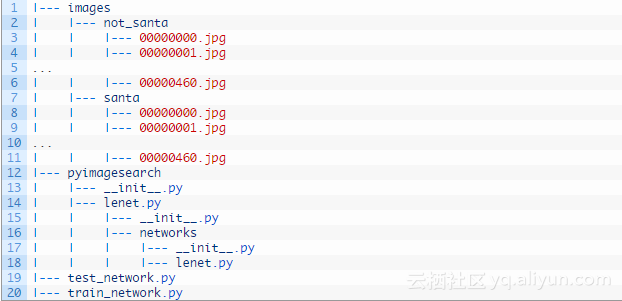
能够提取标签是由于我们的数据目录结构如下所示:
![11bf89631e64bebe6d10aed38542e674cc09ddec]()
因此,imagePath的一个例子为:
![553b927b15916c1998bf9ea1486efaffad827285]()
从ImagePath提取标签,结果为:
![505c24a50c9a24a372d4c933ca711ddb71cc4e80]()
下一步,将数据集分为训练数据集和测试数据集:
![820577bce7f3aa93791c9ea6f5fea2a5d5144a58]()
第61行进一步预处理输入数据,按比例将数据点[ 0, 255 ]缩放到[ 0, 1 ]范围内;
然后第66-67行将75%数据作为训练集,25%数据作为测试集;第70-71行对标签进行独热编码;随后,通过以下操作增加数据量:
![ec05ddb47634423e87fa721b29114a55d957ce82]()
第74-76行创建一个图像发生器,对数据集图像进行随机旋转、移动、翻转、剪切等,通过这种操作允许我们能用一个较小的数据集实现好的结果。
继续深入学习Keras训练图像分类器:
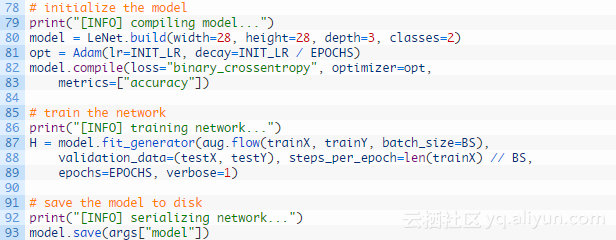
第80-83行使用Adam优化器,由于本文是一个二分类问题,可以使用二进制交叉熵损失函数(binary cross-entropy)。但如果执行的分类任务多于两类,损失函数更换为类别交叉熵(categorical_crossentropy)
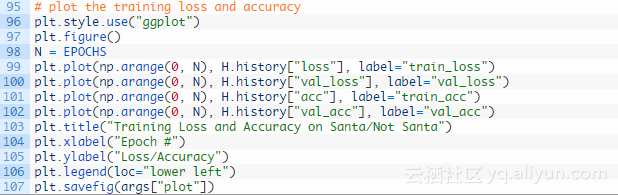
第87-89行调用model.fit_generator开始训练网络,第93行保存模型参数,最后画出图像分类器的性能结果:
![bb43119155aa0a9adb643f9030683d3dcb675d62]()
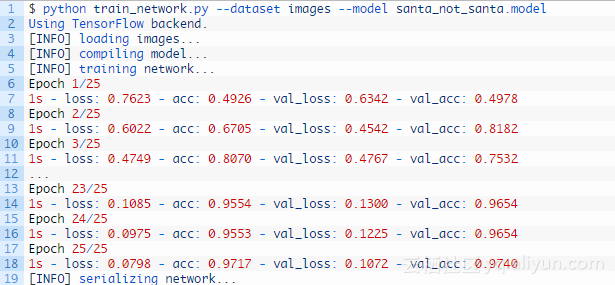
为了训练网络模型,需要打开一个终端执行以下命令:
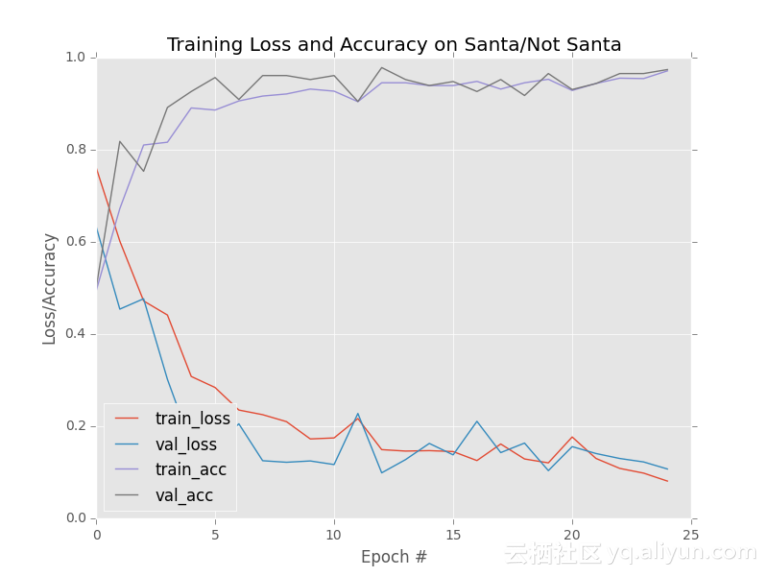
可以看到,当网络训练了25个回合后,模型的测试精度为97.40%,损失函数也很低,如下图所示:
![40aa6bc8c87caf1078e2135a494f7cc6bb85cd90]()
评估卷积神经网络图像分类器
打开一个新的文件并命名为test_networkpy,然后开始进行评估:
第2-7行导入需要的数据包,另外注意导入的load_model是训练过程中保存的模型。
下一步,解析命令行参数:
![c6d6a24f7ce0fc95e7b21992d9af19ce0bbda9c6]()
需要两个命令行参数:--model和输入--image,然后加载图像预处理:
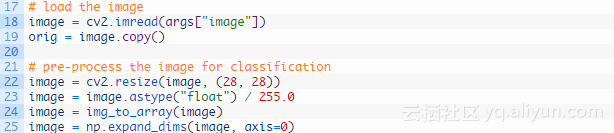
预处理与前面几乎一模一样,这里不做过多的解释,只是第25行通过np.expand_dims对数据额外添加了一个维度,如果忘记添加维度,它将导致调用model.predict时出现错误。现在加载图像分类器模型并进行预测:
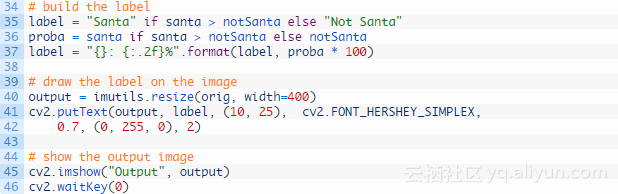
第29行加载模型,第32行做出预测。最后画出头像以及预测标签:
![e5d9a9d5f9397cfe151833a65f0d55180d247ffa]()
第35行建立标签,第36行选择对应的概率值,第37行将标签文本显示在图像的左上角,第40-42行调整图像大小为标准的宽度以确保它适应电脑屏幕,最后,第45行显示输出图像,第46行表示当一个键被按下结束显示。
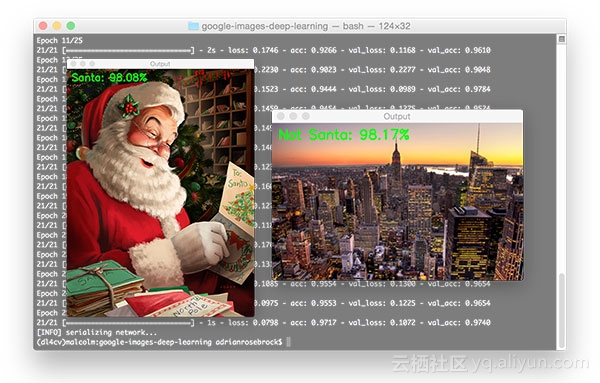
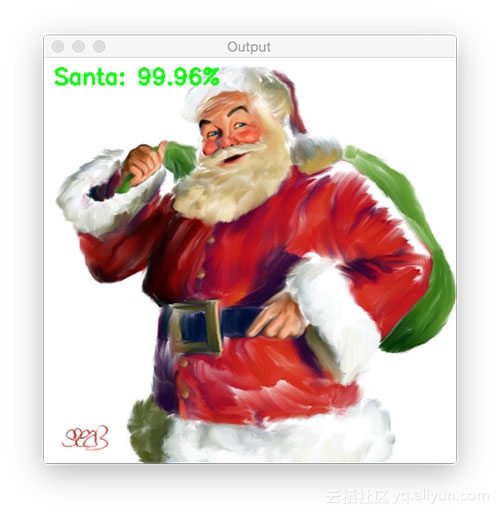
以下是包含圣诞老人图像的实验结果:
![dbf05757ac76ff9eaffb6561bbe6e57771d32b0b]()
![1371eb19a5095b7cd6566382bc0cc530456425cd]()
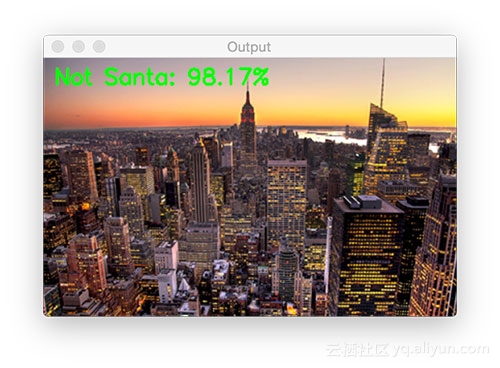
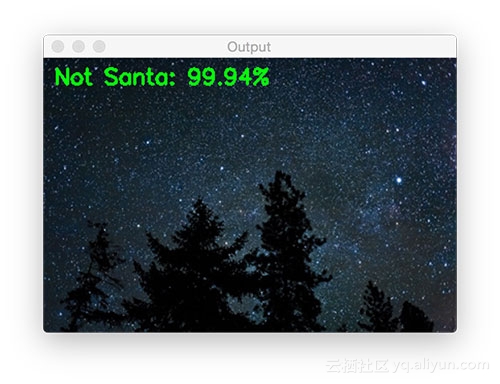
以下是不包含圣诞老人图像的实验结果:
![0a46ad8dd516e87af55b4c83ae6a163d4269aa61]()
![8b641c89cb08c3c898aa80aeb3df2889140cfbf5]()
本文图像分类模型的局限性
本文图像分类器有一些局限性:
第一个是输入图像尺寸28×28很小。一些示例图像(图像中圣诞老人本身已经很小)调整尺寸为28×28后大大降低圣诞老人的尺寸。
最优的卷积神经网络正常接受输入图像大小一般为200-300像素,因此一些较大尺寸的图像将帮助我们建立一个更强大的图像分类器。然而,使用更大的分辨率的图像会加深网络模型的深度和复杂度,这将意味着需要收集更多的训练数据,以及昂贵的计算训练过程。
因此,如果各位读者想提高本文模型的精度话,有以下四点建议:
总结
作者信息
![03539ed1f7341cc0bfddc238a9d505bf21bb3799]()
Adrain Rosebrock,企业家、博士,专注于图像搜索引擎。
Linkedin: https://www.linkedin.com/in/adrian-rosebrock-59b8732a/
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《Image classification with Keras and deep learning》,作者:Adrain Rosebrock,译者:海棠,审阅:董邵男。
文章为简译,更为详细的内容,请查看原文
翻译者: 海棠
Wechat:269970760
Email:duanzhch@tju.edu.cn
微信公众号:AI科技时讯
![157f33dddfc596ede3681e0a2a0e7068dc288cc1]()