一、Druid概述
1、Druid简介
Druid是一款基于分布式架构的OLAP引擎,支持数据写入、低延时、高性能的数据分析,具有优秀的数据聚合能力与实时查询能力。在大数据分析、实时计算、监控等领域都有相关的应用场景,是大数据基础架构建设中重要组件。
与现在相对热门的Clickhouse引擎相比,Druid对高并发的支持相对较好和稳定,但是Clickhouse在任务队列模式中的数据查询能力十分出色,但是对高并发支持不够友好,需要做好很多服务监控和预警。大数据组件中OLAP引擎的选型有很多,在数据的查询引擎层通常都具有两种或者以上的OLAP引擎,选择合适的组件解决业务需求是优先原则。
2、基本特点
分布式
分布式的OLAP数据引擎,数据分布在多个服务节点中,当数据量激烈增长的时候,可以通过增加节点的方式进行水平扩容,数据在多个节点相互备份,如果单个节点出现故障,则可基于Zookeeper调度机制重新构建数据,这是分布式OLAP引擎的基本特点,在之前Clickhouse系列中也说过这个策略。
聚合查询
主要针对时间序列数据提供低延时数据写入和快速聚合查询,时序数据库特点写入即可查询,Druid在数据写入时就会对数据预聚合,进而减少原始数据量,节省存储空间并提升查询效率;数据聚合粒度可以基于特定策略,例如分钟、小时、天等。必须要强调Druid适合数据分析场景,并不适合单条数据主键查询的业务。
列式存储
Druid面向列的存储方式,并且可以在集群中进行大规模的并行查询,这意味在只需要加载特定查询所需要的列情况下,查询速度可以大幅度提升。
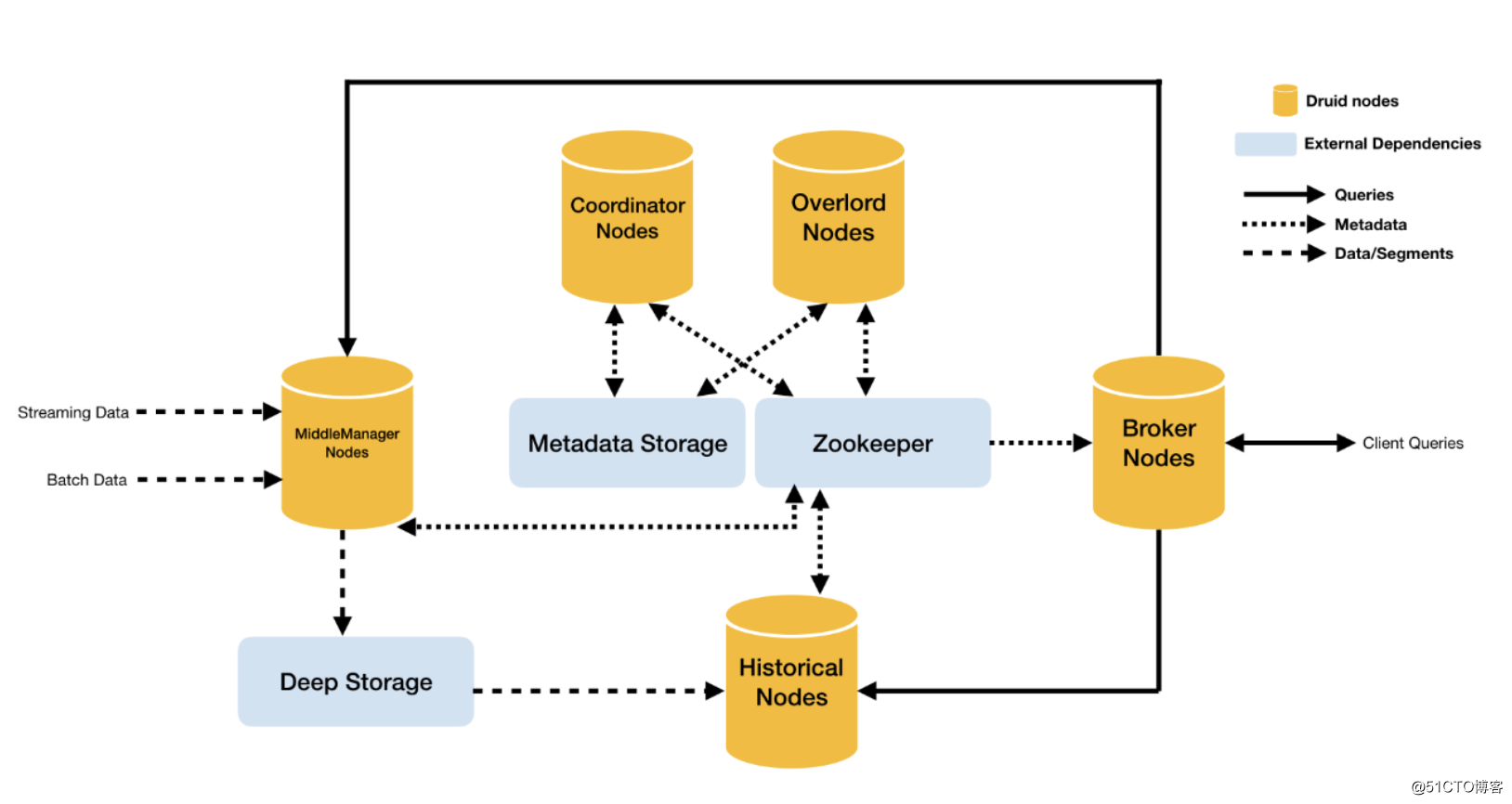
3、基础架构
![OLAP引擎:基于Druid组件进行数据统计分析]()
统治者节点
即Overlord-Node,任务的管理节点,进程监视MiddleManager进程,并且是数据摄入Druid的控制器,负责将提取任务分配给MiddleManagers并协调Segement发布。
协调节点
即Coordinator-Node,主要负责数据的管理和在历史节点上的分布,协调节点告诉历史节点加载新数据、卸载过期数据、复制数据、和为了负载均衡移动数据。
中间管理节点
即MiddleManager-Node,摄入实时数据,已生成Segment数据文件,可以理解为overlord节点的工作节点。
历史节点
即Historical-Node,主要负责历史数据存储和查询,接收协调节点数据加载与删除指令,historical节点是整个集群查询性能的核心所在,因为historical会承担绝大部分的segment查询。
查询节点
即Broker-Node,扮演着历史节点和实时节点的查询路由的角色,接收客户端查询请求,并将这些查询转发给Historicals和MiddleManagers,当Brokers从这些子查询中收到结果时,它们会合并这些结果并将它们返回给调用者。
数据文件存储库
即DeepStorage,存放生成的Segment数据文件。
元数据库
即MetadataStorage,存储Druid集群的元数据信息,比如Segment的相关信息。
协调中间件
即Zookeeper,为Druid集群提供协调服务,如内部服务的监控,协调和领导者选举。
二、Druid部署
1、安装包
imply对druid做了集成,并提供从部署到配置到各种可视化工具的完整的解决方案。
https://static.imply.io/release/imply-2.7.10.tar.gz
解压并重新命名。
[root@hop01 opt]# tar -zxvf imply-2.7.10.tar.gz
[root@hop01 opt]# mv imply-2.7.10 imply2.7
2、Zookeeper配置
配置Zookeeper集群各个节点,逗号分隔。
[root@hop01 _common]# cd /opt/imply2.7/conf/druid/_common
[root@hop01 _common]# vim common.runtime.properties
druid.zk.service.host=hop01:2181,hop02:2181,hop03:2181
关闭Zookeeper内置校验并且不启动。
[root@hop01 supervise]# cd /opt/imply2.7/conf/supervise
[root@hop01 supervise]# vim quickstart.conf
注释掉如下内容:
![OLAP引擎:基于Druid组件进行数据统计分析]()
3、服务启动
依次启动相关组件:Zookeeper、Hadoop相关组件,然后启动imply服务。
[root@hop01 imply2.7]# /opt/imply2.7/bin/supervise -c /opt/imply2.7/conf/supervise/quickstart.conf
注意虚拟机内存问题,在如下的目录中Druid各个组件的JVM配置,条件不允许的话适当拉低,并且要拉高JVM相关内存参数。
[root@hop01 druid]# cd /opt/imply2.7/conf/druid
启动默认端口:9095,访问界面如下:
![OLAP引擎:基于Druid组件进行数据统计分析]()
三、基础用法
1、数据源配置
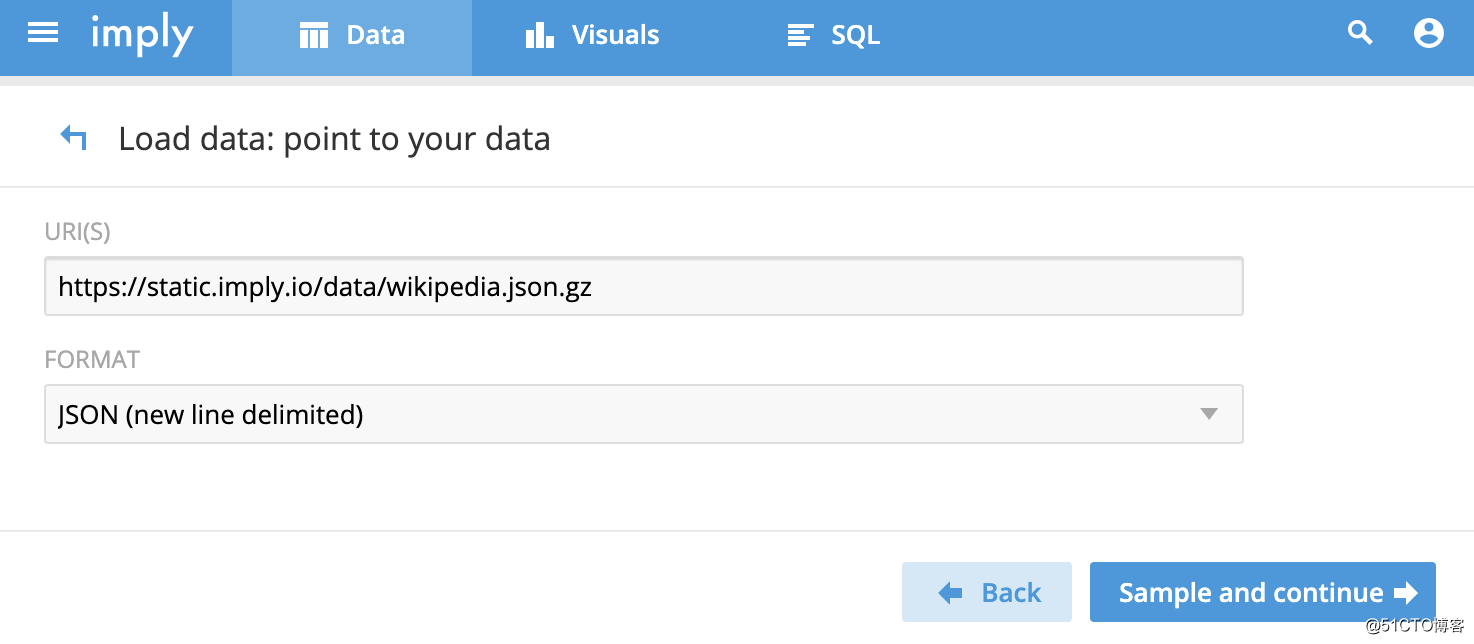
选择上述Http的方式,基于imply提供的JSON测试文件。
https://static.imply.io/data/wikipedia.json.gz
![OLAP引擎:基于Druid组件进行数据统计分析]()
2、数据在线加载
执行上述:Sample and continue。
![OLAP引擎:基于Druid组件进行数据统计分析]()
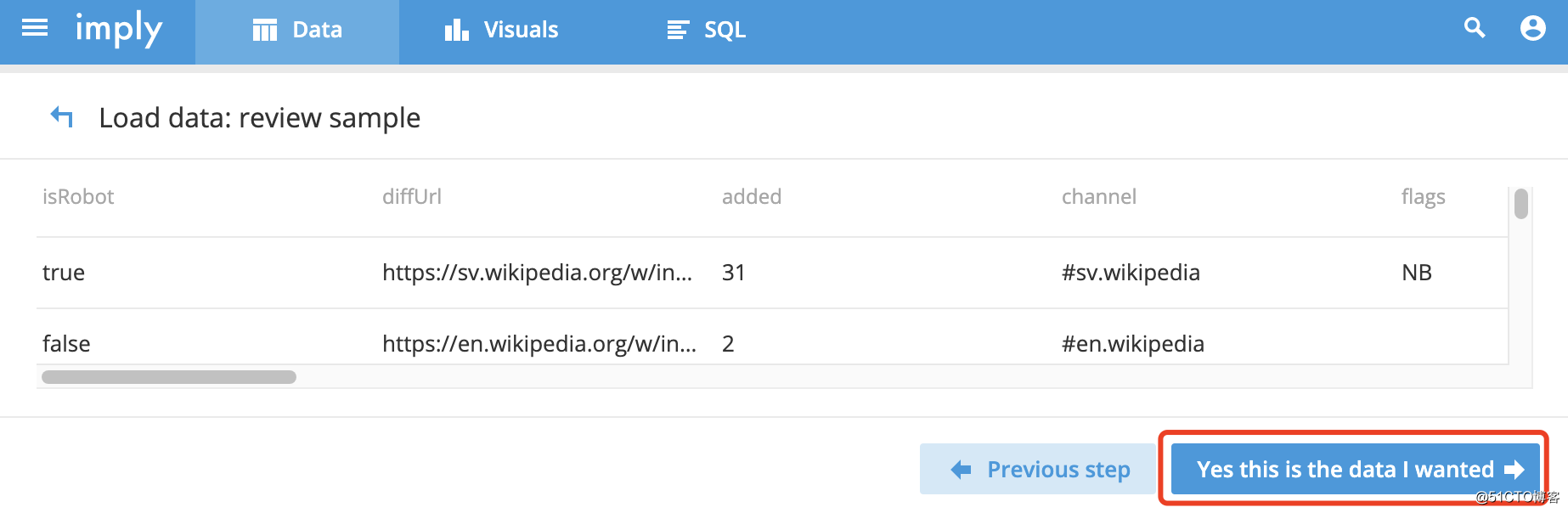
样本数据加载配置:
![OLAP引擎:基于Druid组件进行数据统计分析]()
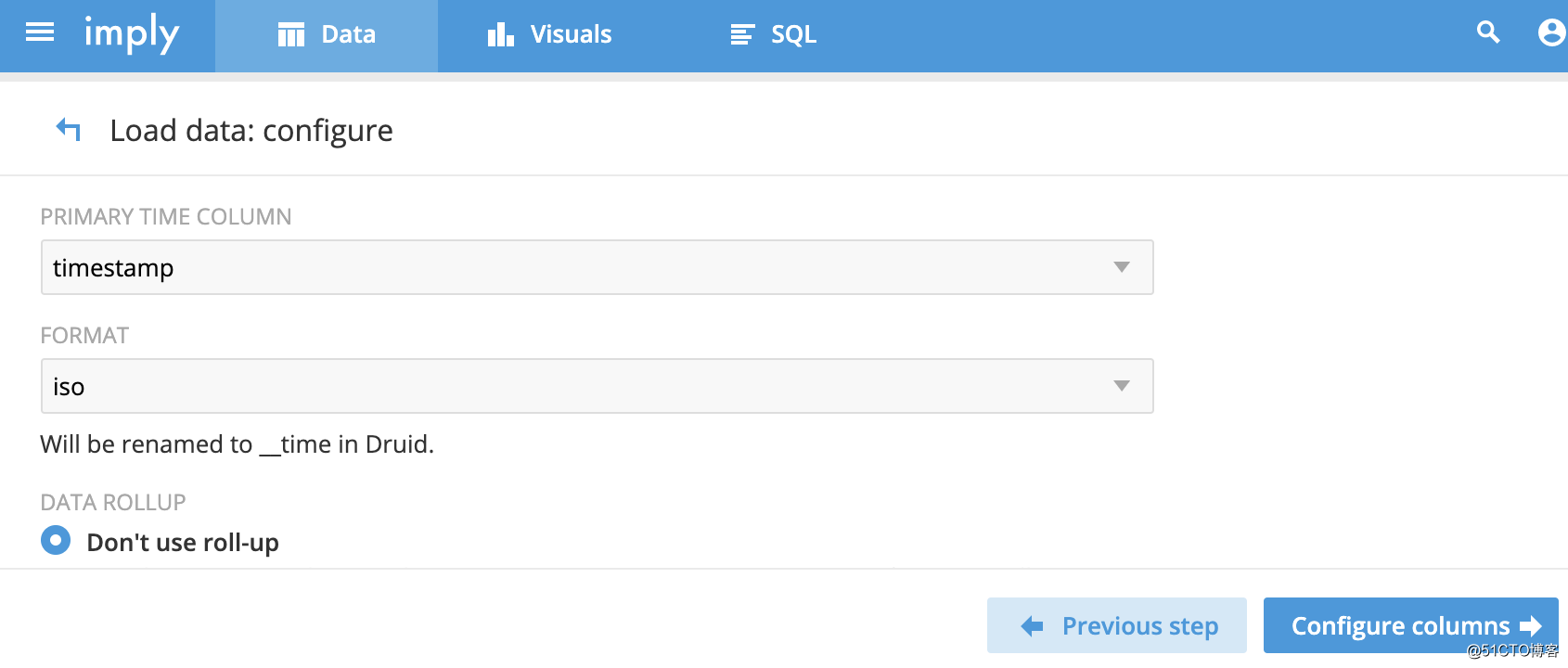
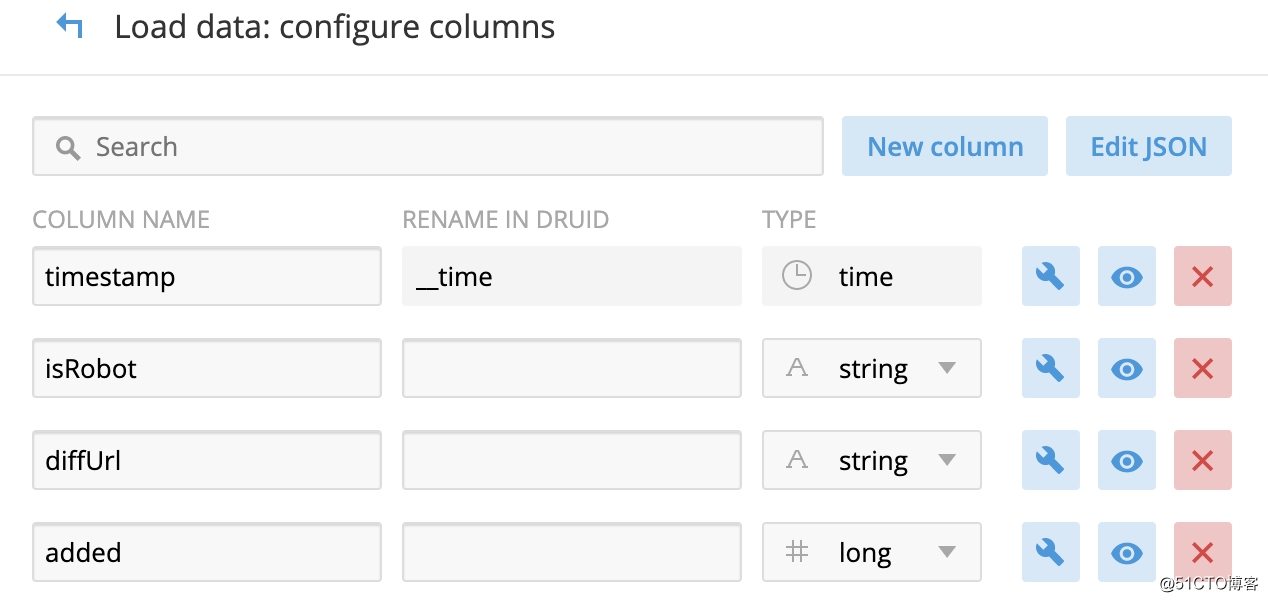
数据列的配置:
![OLAP引擎:基于Druid组件进行数据统计分析]()
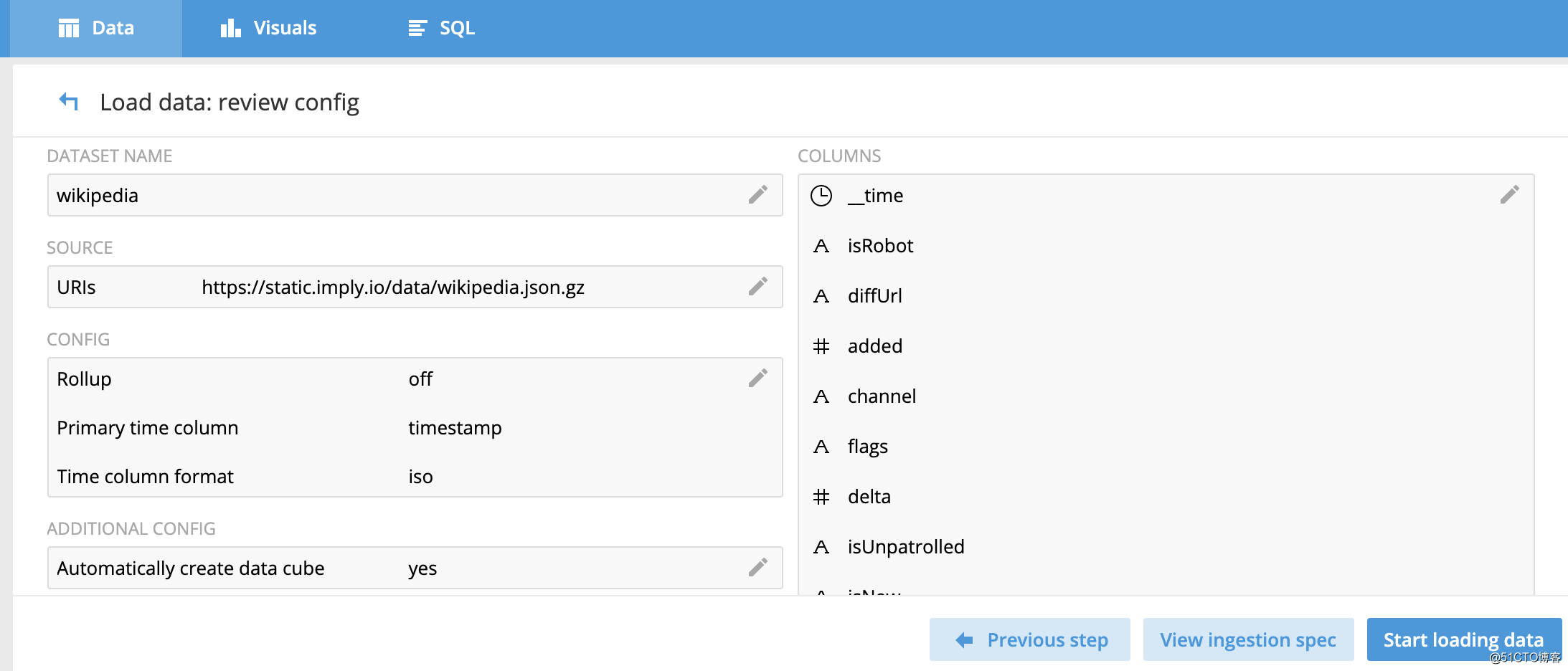
配置项总体概览:
![OLAP引擎:基于Druid组件进行数据统计分析]()
最后执行数据加载任务即可。
3、本地样本加载
[root@hop01 imply2.7]# bin/post-index-task --file quickstart/wikipedia-index.json
这样读取两份数据脚本。
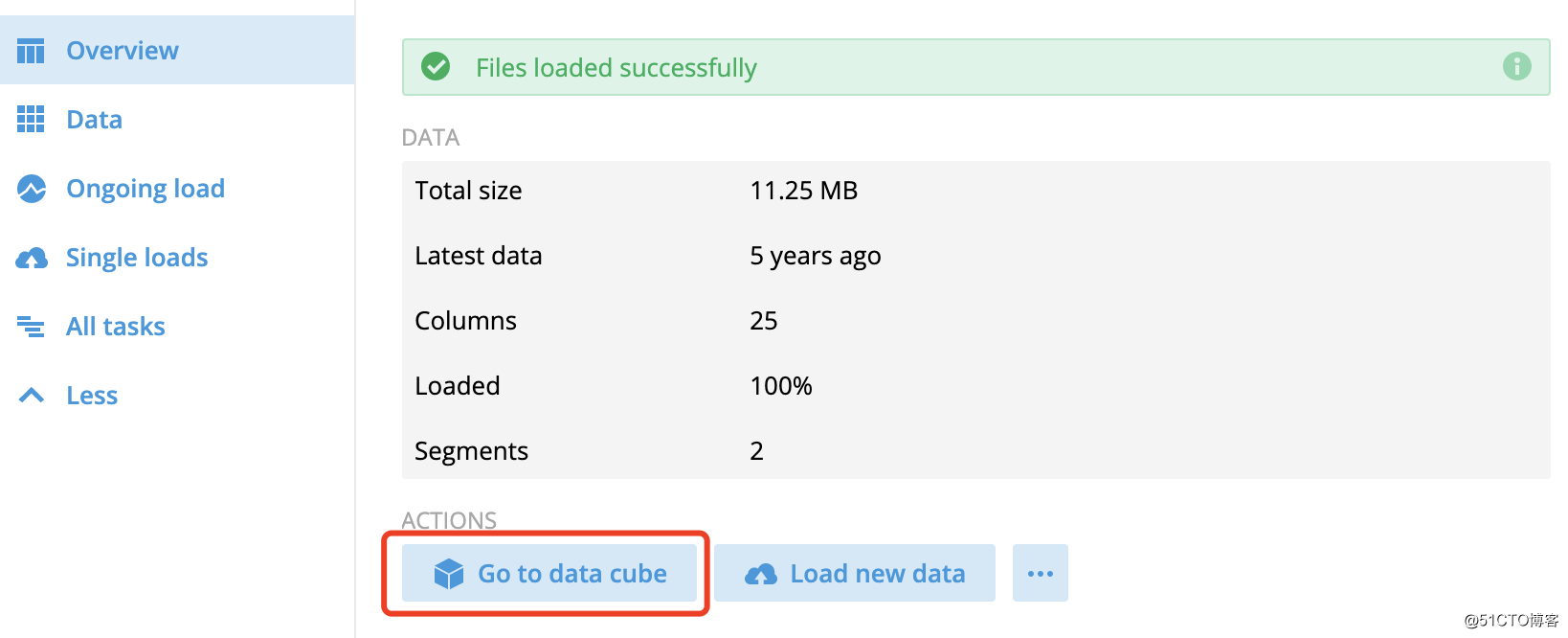
4、数据立方体
数据加载完成后,查看可视化数据立方体:
![OLAP引擎:基于Druid组件进行数据统计分析]()
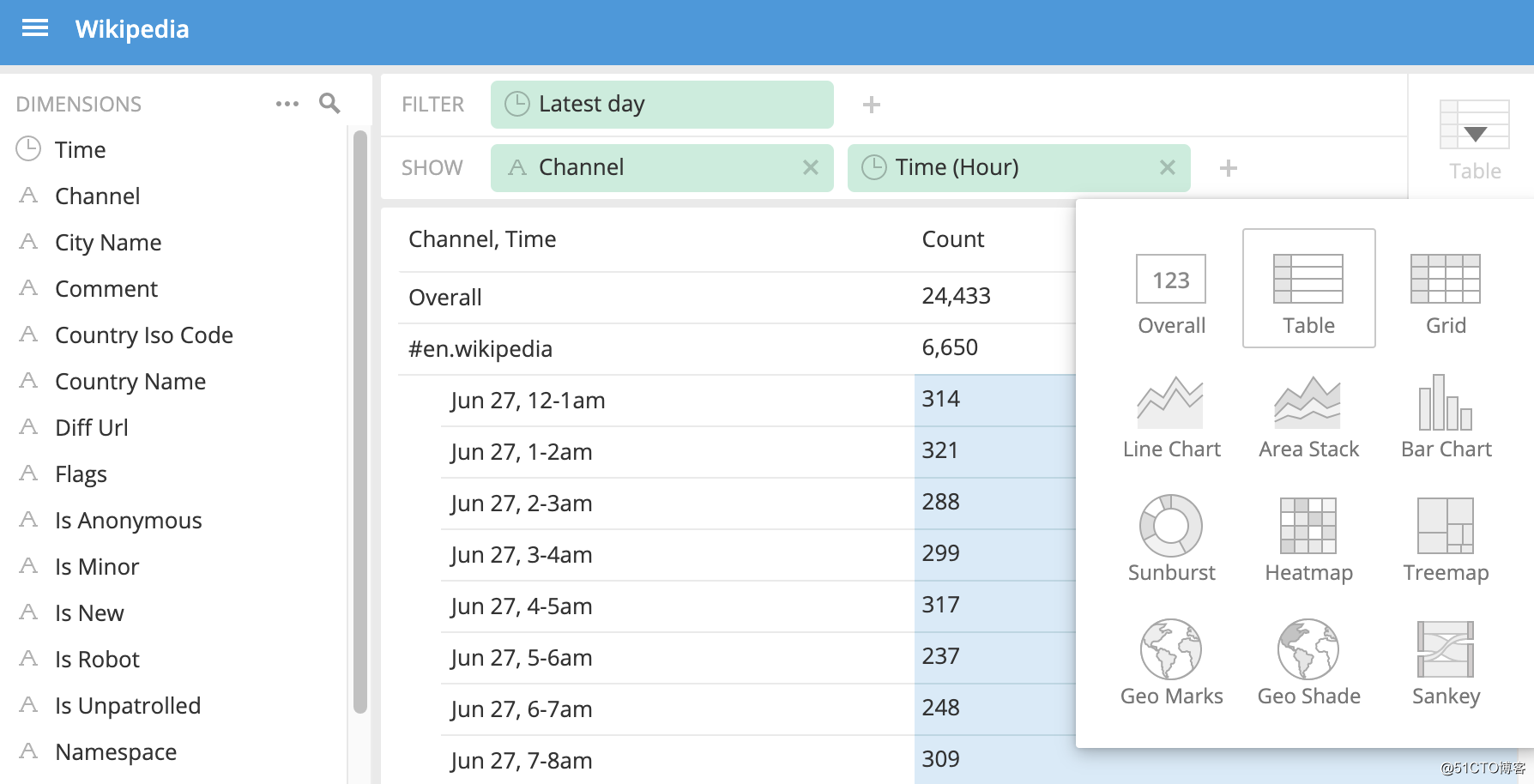
数据立方体中提供一些基础的视图分析,可以在多个维度上拆分数据集并进行数据分析:
![OLAP引擎:基于Druid组件进行数据统计分析]()
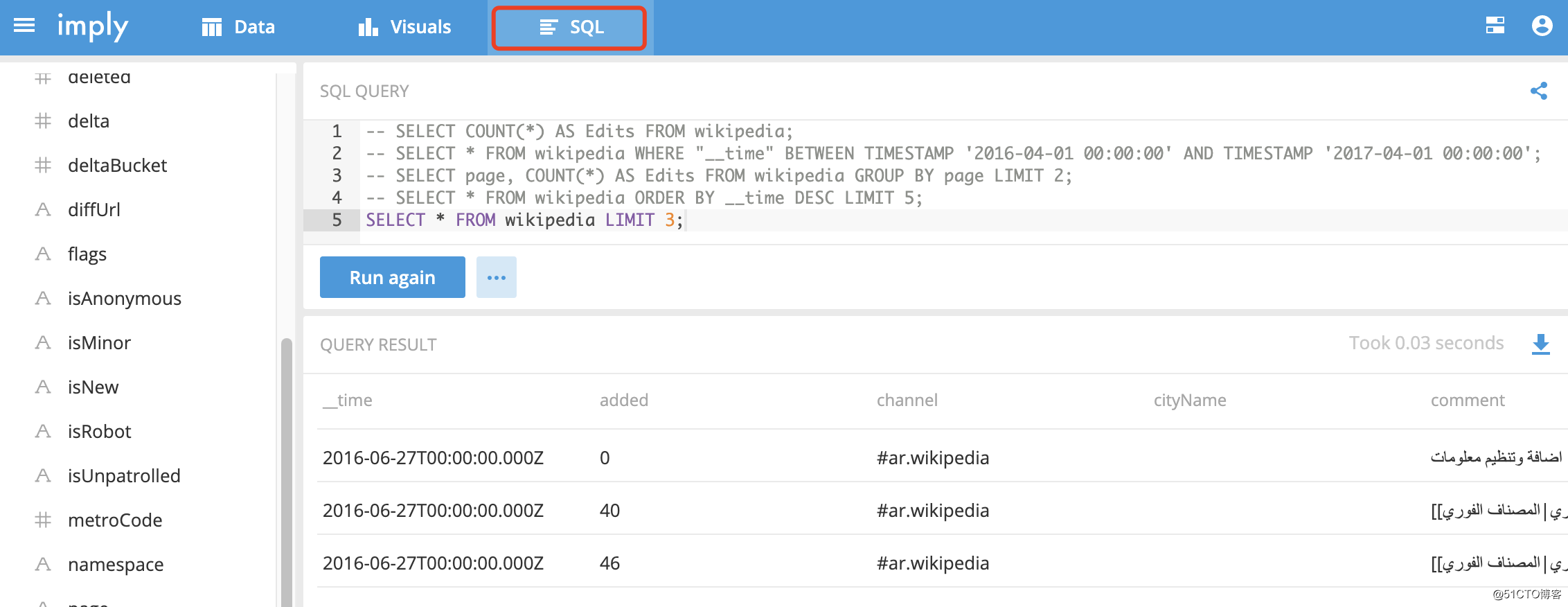
5、SQL查询
可以基于可视化工具对Druid进行SQL查询,语法与常用规则几乎一样:
SELECT COUNT(*) AS Edits FROM wikipedia;
SELECT * FROM wikipedia WHERE "__time" BETWEEN TIMESTAMP '开始' AND TIMESTAMP '结束';
SELECT page, COUNT(*) AS Edits FROM wikipedia GROUP BY page LIMIT 2;
SELECT * FROM wikipedia ORDER BY __time DESC LIMIT 5;
SELECT * FROM wikipedia LIMIT 3;
![OLAP引擎:基于Druid组件进行数据统计分析]()
6、Segment文件
文件位置:
/opt/imply2.7/var/druid/segments/wikipedia/
Druid基于Segment实现对数据的切割,数据按时间的时序分布,将不同时间范围内的数据存储在不同的Segment数据块中,按时间范围查询数据时,可以避免全数据扫描效率可以极大的提高,同时面向列进行数据压缩存储,提高分析的效率。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
![OLAP引擎:基于Druid组件进行数据统计分析]()
往期推荐
☞ OLAP查询引擎,ClickHouse集群化管理
☞ HBase集群环境搭建和应用案例
☞ 搜索引擎框架,ElasticSearch集群应用
☞ 分布式NoSQL系统,Cassandra集群管理