数据生产面临的挑战
数据爆炸,每日使用最新维度对历史数据进行回溯计算。在Kylin的MOLAP模式下存在如下问题:
- 历史数据每日刷新,失去了增量的意义。
- 每日回溯历史数据量大,10亿+的历史数据回溯。
- 数据计算耗时3小时+,存储1TB+,消耗大量计算存储资源,同时严重影响SLA的稳定性。
- 预计算的大量历史数据实际使用率低下,实际工作中对历史的回溯80%集中在近1个月左右,但为了应对所有需求场景,业务要求计算近半年以上的历史。
- 不支持明细数据的查询。
引入MPP引擎,数据现用现算
历史数据预计算成本巨大,最好的办法就是现用现算,但现用现算需要强大的并行计算能力。
OLAP的实现有 MOLAP、ROLAP、HOLAP 三种形式。
MOLAP 以Cube为表现形式,但计算与管理成本较高。
ROLAP 需要强大的关系型DB引擎支撑。
长期以来,由于传统关系型DBMS的数据处理能力有限,所以ROLAP模式受到很大的局限性。随着分布式、并行化技术成熟应用,MPP引擎逐渐表现出强大的高吞吐、低时延计算能力,号称“亿级秒开”的引擎不在少数,ROLAP模式可以得到更好的延伸。单从业务实际应用考虑,性能在千万量级关联查询现场计算秒开的情况下,已经可以覆盖到很多应用场景,具备应用的可能性。例如:日数据量的ROLAP现场计算,周、月趋势的计算,以及明细数据的浏览都可以较好的应对。
MOLAP模式的劣势
- 应用层模型复杂,根据业务需要以及Kylin生产需要,还要做较多模型预处理。这样在不同的业务场景中,模型的利用率也比较低。
- Kylin配置过程繁琐,需要配置模型设计,并配合适当的“剪枝”策略,以实现计算成本与查询效率的平衡。
- 由于MOLAP不支持明细数据的查询,在“汇总+明细”的应用场景中,明细数据需要同步到DBMS引擎来响应交互,增加了生产的运维成本。
- 较多的预处理伴随着较高的生产成本。
ROLAP模式的优势
- 应用层模型设计简化,将数据固定在一个稳定的数据粒度即可。比如商家粒度的星形模型,同时复用率也比较高。
- App层的业务表达可以通过视图进行封装,减少了数据冗余,同时提高了应用的灵活性,降低了运维成本。
- 同时支持“汇总+明细”。
- 模型轻量标准化,极大的降低了生产成本。
综上所述,在变化维、非预设维、细粒度统计的应用场景下,使用MPP引擎驱动的ROLAP模式,可以简化模型设计,减少预计算的代价,并通过强大的实时计算能力,可以支撑良好的实时交互体验。
双引擎下的应用场景适配问题
架构上通过MOLAP+ROLAP双引擎模式来适配不同应用场景
技术权衡
MOLAP:通过预计算,提供稳定的切片数据,实现多次查询一次计算,减轻了查询时的计算压力,保证了查询的稳定性,是“空间换时间”的最佳路径。实现了基于Bitmap的去重算法,支持在不同维度下去重指标的实时统计,效率较高。
ROLAP:基于实时的大规模并行计算,对集群的要求较高。
MPP引擎的核心是通过将数据分散,以实现CPU、IO、内存资源的分布,来提升并行计算能力。在当前数据存储以磁盘为主的情况下,数据Scan需要的较大的磁盘IO,以及并行导致的高CPU,仍然是资源的短板。因此,高频的大规模汇总统计,并发能力将面临较大挑战,这取决于集群硬件方面的并行计算能力。传统去重算法需要大量计算资源,实时的大规模去重指标对CPU、内存都是一个巨大挑战。目前Doris最新版本已经支持Bitmap算法,配合预计算可以很好地解决去重应用场景。
MOLAP: 当业务分析维度相对固化,并在可以使用历史状态时,按照时间进行增量生产,加工成本呈线性增长状态,数据加工到更粗的粒度(如组织单元),减少结果数据量,提高交互效率。如上图所示,由A模型预计算到B模型,使用Kylin是一个不错的选择。
ROLAP: 当业务分析维度灵活多变或者特定到最新的状态时(如上图A模型中,始终使用最新的商家组织归属查看历史),预计算回溯历史数据成本巨大。在这种场景下,将数据稳定在商家的粒度,通过现场计算进行历史数据的回溯分析,实现现用现算,可以节省掉预计算的巨大成本,并带来较大的应用灵活性。这种情况下适合MPP引擎支撑下的ROLAP生产模式。
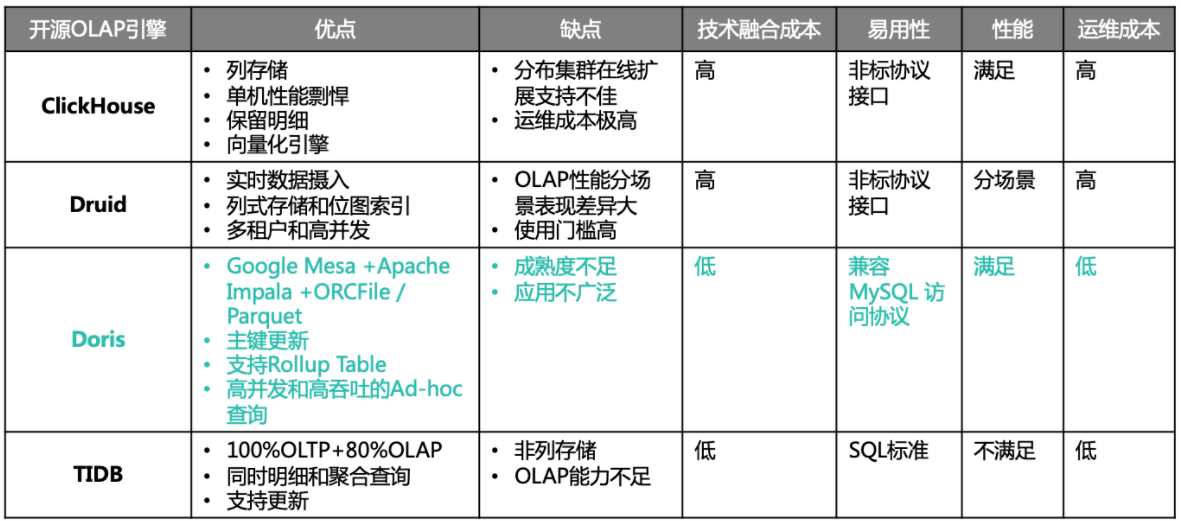
MPP引擎的选型
目前开源的比较受关注的OLAP引擎很多,比如 Greenplum、Apache Impala、Presto、Doris、ClickHouse、Druid、TiDB 等等,但缺乏实践案例的介绍,所以我们也没有太多的经验可以借鉴。于是,我们就结合自身业务的需求,从引擎建设成本出发,并立足于公司技术生态融合、集成、易用性等维度进行综合考虑,作为选型依据,最终我们平台部门选择了2018年刚进入Apache社区的Doris。
![]()
参考
https://tech.meituan.com/2020/04/09/doris-in-meituan-waimai.html