kafka脱胎于雅虎项目,在现今的消息系统中,存在着举足轻重的意义。在笔者看来学习Kafka这款系统既有利于思考分布式消息队列的推演,也有利于发掘rabbitmq中的不足,以史为鉴可以知兴替,学习老大哥rabbitmq中的精华,摒弃其中的糟粕,提升下一代消息队列服务的性能,荣幸之至。
不妨看看消息队列的官方介绍
In computer science, message queues and mailboxes are software-engineering components typically used for inter-process communication (IPC), or for inter-thread communication within the same process. They use a queue for messaging – the passing of control or of content. Group communication systems provide similar kinds of functionality.
翻译过来就是,在计算机科学领域,消息队列和邮箱都是软件工程组件,通常用于进程间或同一进程内的线程通信。它们通过队列来传递消息-传递控制信息或内容,群组通信系统提供类似的功能
对于消息队列的看法
消息队列就是一个使用队列来通信的组件,消息队列常常指代的是消息服务中间件,然而它的存在不仅仅只是为了解决通信这个问题。笔者看来其存在至少有三个目的:
消息队列的存在就是为了实现这三个目的,也是围绕这三个目的而进行架构设计实践和功能升级迭代
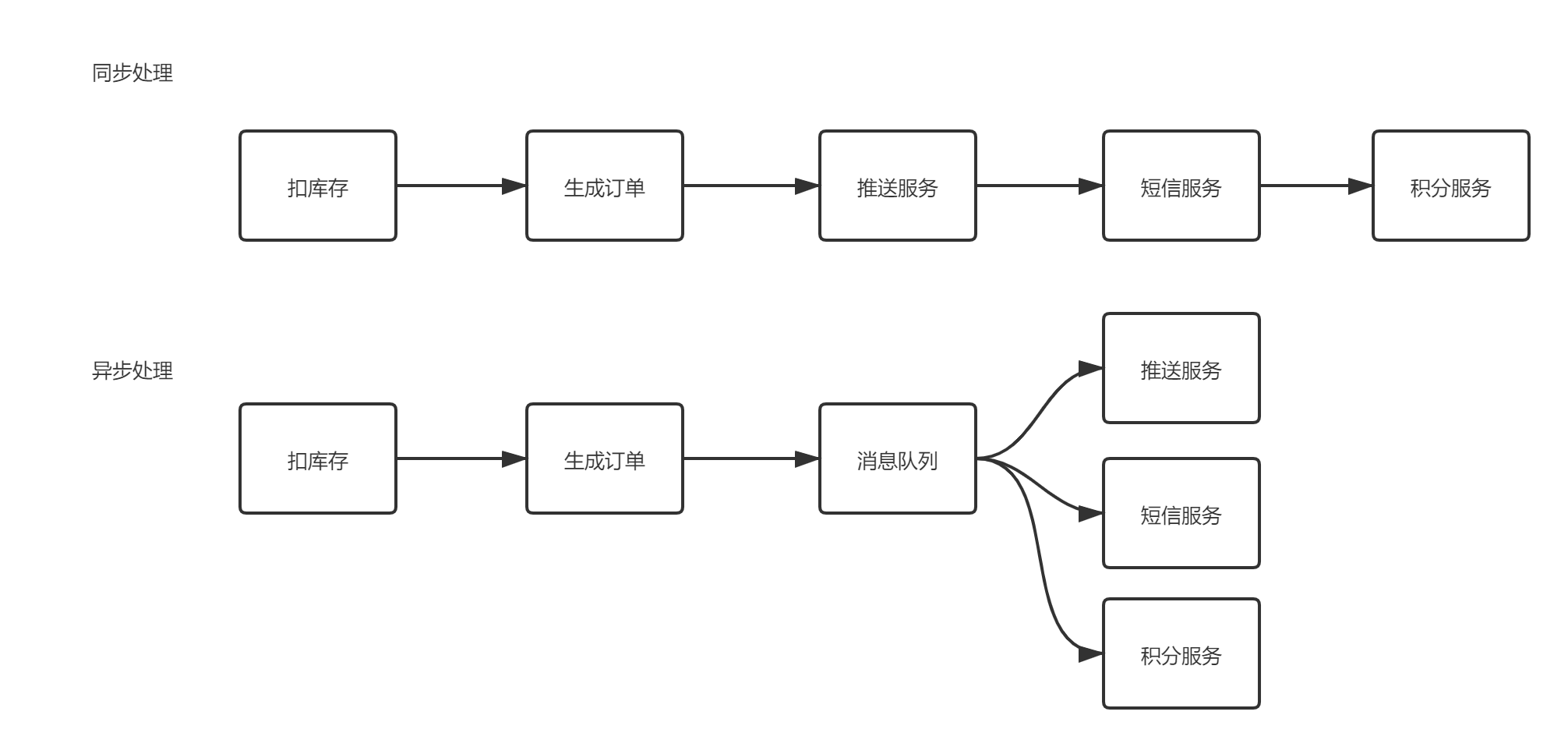
异步处理
减少请求的等待,还能让服务异步并发处理,提升系统总体性能。流程如图所示
![Kafka评传——从kafka的消息生命周期引出的沉思]()
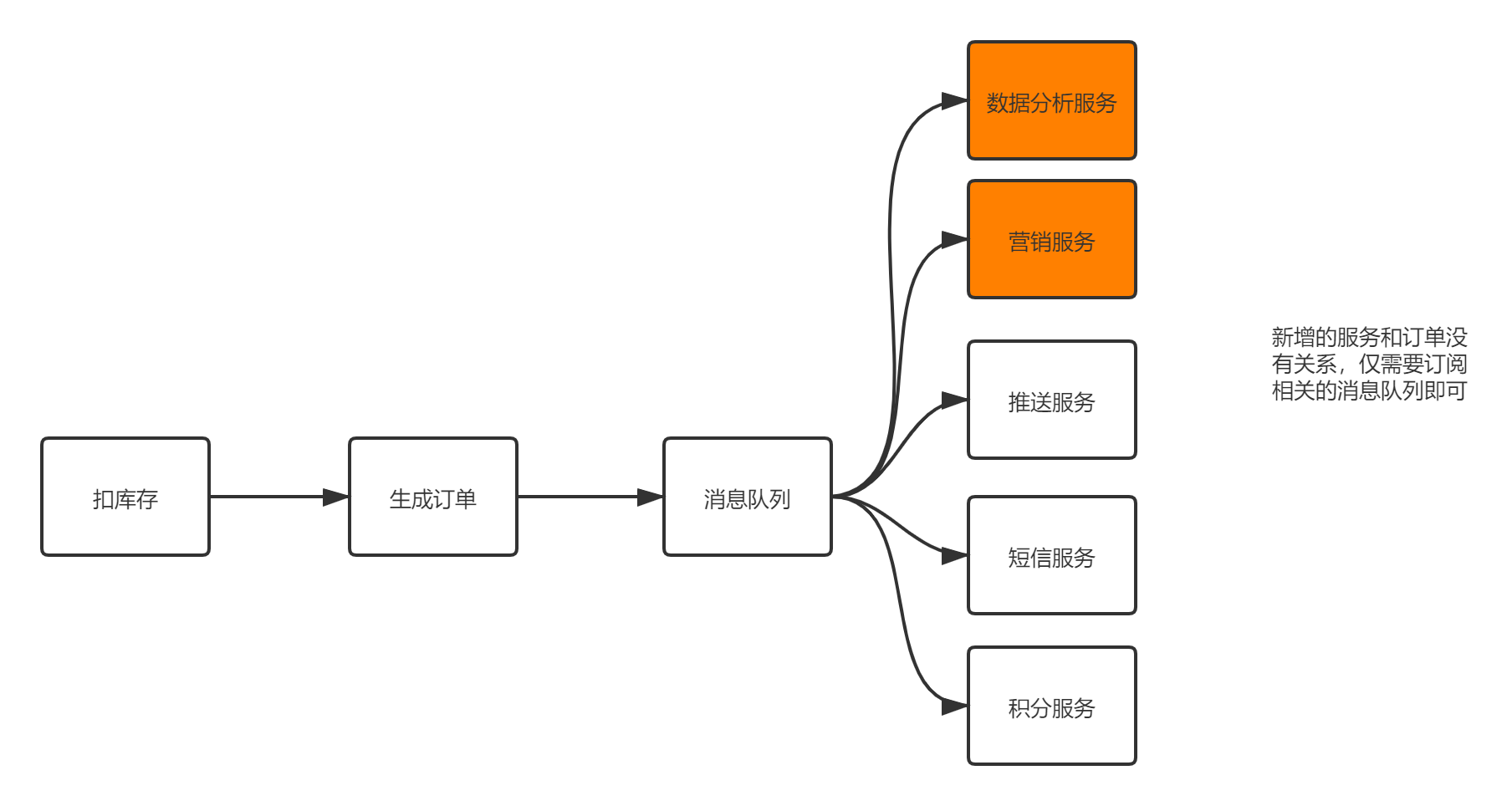
服务解耦
订单服务把订单相关消息塞到消息队列中,下游系统谁要谁就订阅这个主题。这样订单服务就解放啦
![Kafka评传——从kafka的消息生命周期引出的沉思]()
流量控制
后端服务相对而言都是比较弱的,因为业务较重,处理时间较长
![Kafka评传——从kafka的消息生命周期引出的沉思]()
利用消息队列,可以存在一个缓冲的作用
- 生产者生产过快,网关的请求先放入消息队列中,后端服务尽自己最大能力去消息队列中消费请求。超时的请求可以直接返回错误信息
- 消费者消费过慢,当然还有一些服务特别是某些后台任务,不需要及时地响应,并且业务处理复杂且流程长,那么过来的请求先放入消息队列中,后端服务按照自己的节奏处理
kafka消息的生命
一条消息是有生命的,存在出生,亦存在死亡,生死之间的传导也存在着诸多的升华,会历经沉浮,各种纷纷扰扰,有副本,有恢复,有重建,还是很值得探索一番,尝试为其写一篇评传,纪念其短暂又有意义的一生。