欢迎关注公众号【sharedCode】致力于主流中间件的源码分析, 可以直接与我联系
事故现场
202-11-19 系统接收到大量的超时告警, 同时业务群里面也有很多客户反馈服务不可用。
![]()
开始排查
首先上grafana上面查看整体的服务状态,
![]() 从图中可以看出一点问题来,CPU几乎没有波动, tomcat线程数急剧上升, 系统的ops急剧下降。 这种是比较典型的资源阻塞类问题,为了印证这个想法,我们再看下当时的系统的GC情况
从图中可以看出一点问题来,CPU几乎没有波动, tomcat线程数急剧上升, 系统的ops急剧下降。 这种是比较典型的资源阻塞类问题,为了印证这个想法,我们再看下当时的系统的GC情况
![]()
从上面的GC情况下,我们可以看出来,GC还是比较平稳的,整体的停顿市场也不多,平均在100ms以下,虽然不算好,但是肯定不会造成系统有如此大的停顿
服务器出现故障排查方法:
服务器出现故障,先看CPU,如果CPU持续高涨,那么肯定是服务内部出现了问题,这个时候可以按照网上的常规解决方法,top -HP pid 查看耗CPU比较严重的线程,然后导出对应的线程栈信息,就 可以根据实际的业务去分析了, 这种属于比较直观的
比较隐晦的资源阻塞问题,此类问题分为如下两种:
- 比较好排查的,即使接口慢,比如接口调用耗费时间久的外部接口,有大量慢SQL,这些都会间接的导致整体吞吐量下降,最终导致tomcat线程池线程池耗尽
- 第二种就更加隐晦了,CPU,带宽,流量,慢SQL,内存各方面都很正常,但是tomcat线程池直线上升,最终服务器资源耗尽。 这种情况我之前有专门写过一片文章。《tomcat线程池排查》 这种情况可以考虑使用jstack命令,导出堆栈信息,这里推荐一款工具 gceasy , 可以清晰的分析出线程的状态分布,可以很好的知道线程都堵在什么地方了。
通过上面的已知条件和我们过往的经验,基本上可以判定是有一些接口阻塞导致整体系统处理能力急剧下降。 首先想到的就是慢SQL。
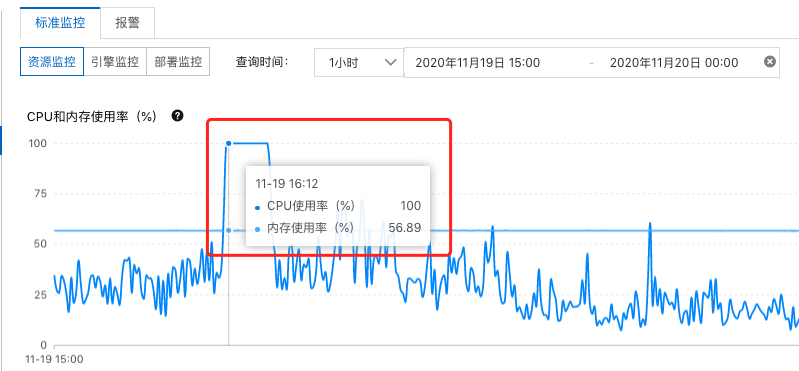
登陆到阿里云的RDS控制台上,查看RDS的运行状况
![]()
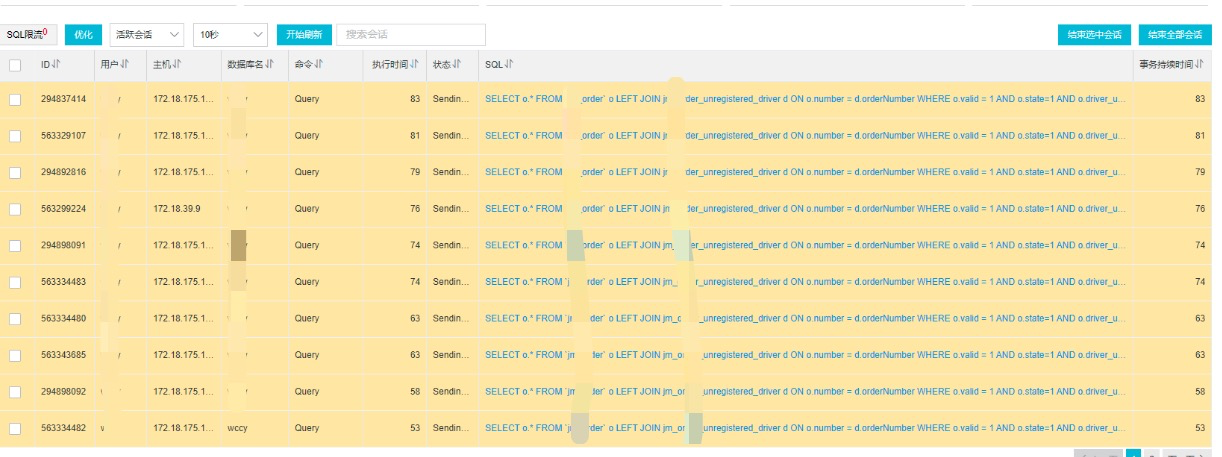
果不其然,在那个时间段,CPU已经到了100%了,基本上可以确定是慢查询的问题, 在慢查询的控制台上,立马可以看到当前系统阻塞的SQL。触目惊心,真的不知道是哪个兔崽子写的SQL。
![]()
罪魁祸首就是这条SQL
SELECT
o.*
FROM
`jm_order` o
LEFT JOIN jm_order_unregistered_driver d ON o.number = d.orderNumber
WHERE
o.valid = 1
AND o.state = 1
AND o.driver_uid = 0
AND o.agents_uid = 0
AND d.driverPhone IS NULL
AND o.is_push_regular_car = 0
AND o.is_lock = 2
AND (
o.from_date > '2020-11-18'
OR (
o.from_date = '2020-11-18'
AND o.from_day >= 16
))
AND o.type IN (
11,
12)
通过explain关键字查询执行计划
![]()
问题一目了然了,看我红线框起来的地方,这个就是问题所在,我们可以分析下这个SQL,这个SQL
里面有两张表,使用了left join , 其他的倒是没什么问题,看索引走向以及扫描函数,其实看上去都没啥问题,不应该耗时这么久。
但是看红色框起来的部分Using where; Using join buffer (Block Nested Loop) , 这句话什么意思?
下面给大家讲一下mysql在表连接的时候使用的算法,同时也让大家理解一下为什么有小表驱动大表的说法
mysql表关联算法
Simple Nested Loop算法
这个算法,属于简单嵌套循环, 说白了就是外层表的结果作为第一层循环,内层表作为第二层循环,然后就这样硬干,
for (Table t:table) {
for(Join x:joinTable){
if(t==x){
//xxxx ,说明匹配到了数据
for(){
// 如果有三种表关联的话。
}
}
}
}
上面这种暴力关联的方法,可想而知效率那是差的一逼,基本上mysql官方也不会使用这种方式的。
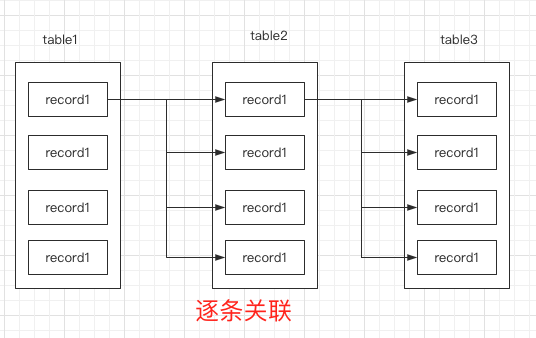
![]() 执行顺序:
执行顺序:
- 先遍历table1
- 遍历table得到的结果,逐条遍历table2
- 遍历完table2之后呢,继续逐条遍历table3, 返回最终的结果
执行次数基本上是: table1 * table2 * table3
Block Nested-Loop
这种算法,就是本文中生产环境实际遇到的,mysql默认在没有建立索引上面使用的算法, 这种做法和简单嵌套循环有一点不同,就是加了 缓存块 , 减少了循环次数 , 将驱动表的数据缓存到 join Buffer里面去,然后拿Join Buffer 里面的数据和内层关联表进行匹配,
for (Table t:table) {
// store t in Join buffer ,
// 当缓冲池满了,执行匹配
if(Join Buffer is full){
for(Join x:joinTable){
if(t in Buffer){
//xxxx ,说明匹配到了数据
for(){
// 如果有三种表关联的话。
}
}
clear join buffer // 清空缓存池
}
}
}
从这里可以看到,使用了缓存池的话,减少了很多次数,比如:驱动表100条数据,被驱动表50条数据,那么如果没有Join Buffer的话,读表次数:100 * 50, 加了Join buffer之后,如果Join buffer的大小可以存储50条数据,那么读表次数就是: 100/50 * 50 , 读表次数减少了一个数量级的。
需要注意的是,只有在 连表键上没有索引的时候会采用这种方式 , 也就是本文出现的情况。
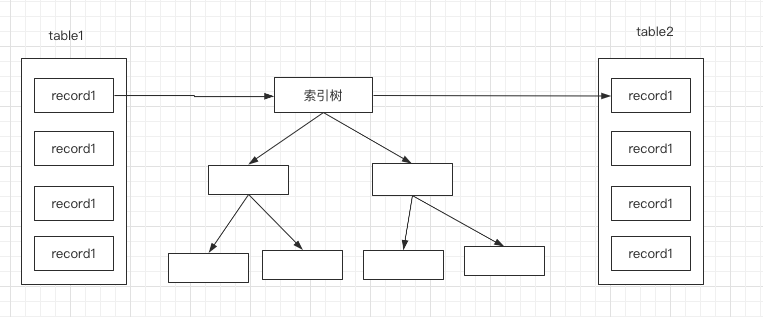
Index Nested-loop
索引嵌套循环,简称 INL, 说白了就是 连表键上有索引,就直接走索引去做嵌套查询 , 下面我画一张图来解释
![]()
驱动表得到结果之后,是直接去索引树上找对应的被驱动表的记录,如果可以使用覆盖索引的话,那么就不用再做回表了,这种情况下,效率是相当高的。
得出以上结果,立马给orderNumber 加上索引,走索引嵌套算法就可以了, 系统马上就恢复正常了。
看完上面的文字,这下大家明白了为啥有小表驱动大表的说法吗?
欢迎关注公众号【sharedCode】致力于主流中间件的源码分析, 可以直接与我联系
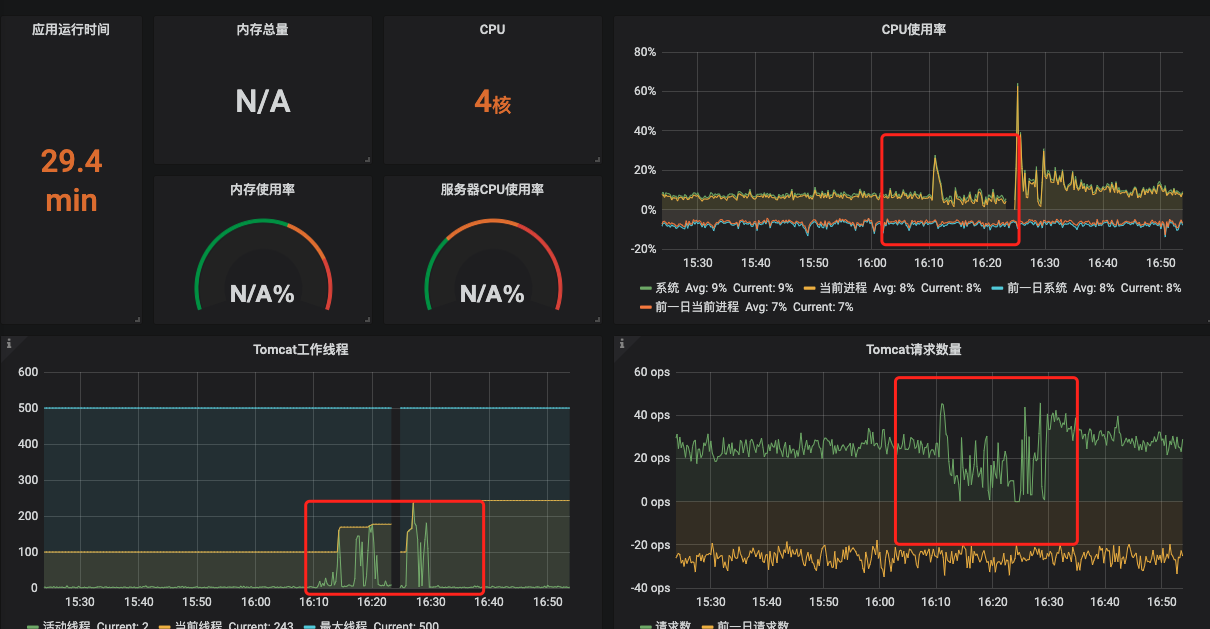 从图中可以看出一点问题来,CPU几乎没有波动, tomcat线程数急剧上升, 系统的ops急剧下降。 这种是比较典型的资源阻塞类问题,为了印证这个想法,我们再看下当时的系统的GC情况
从图中可以看出一点问题来,CPU几乎没有波动, tomcat线程数急剧上升, 系统的ops急剧下降。 这种是比较典型的资源阻塞类问题,为了印证这个想法,我们再看下当时的系统的GC情况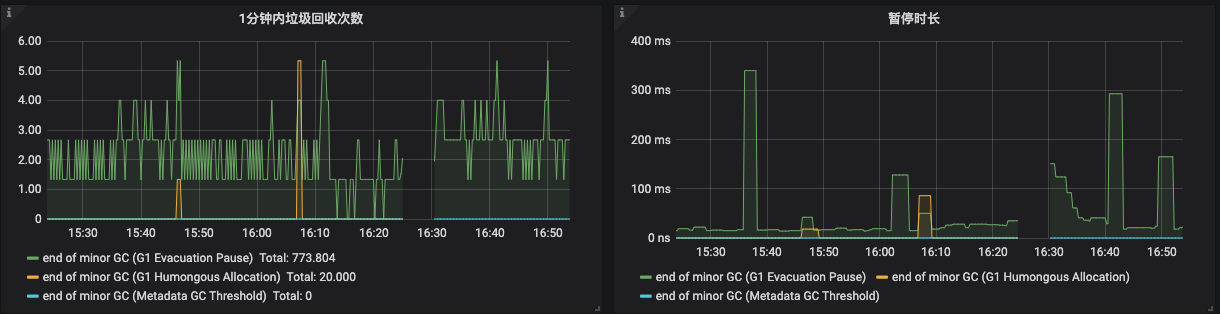

 执行顺序:
执行顺序: