![]()
ConcatAdapter 是 recyclerview: 1.2.0-alpha 04 中提供的一个新组件,它可以帮我们顺序地组合多个 Adapter,并让它们显示在同一个 RecyclerView 中。这使您可以更好地封装 Adapter。您不必再将许多数据源组合到一个 Adapter 中,从而在减少 Adapter 复杂度的同时也让它们可以被复用。
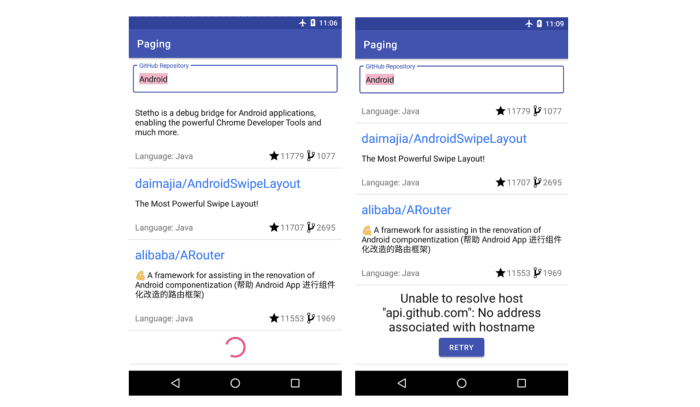
这方面的一个用例,是在列表头部和底部显示加载状态: 当列表从网络中检索数据时,我们想显示一个加载中的图标;如果出现错误,我们要显示错误信息和重试按钮。
![△ 一个带有底部的 RecyclerView,底部显示了加载状态: 加载进度或错误信息]()
△ 一个带有底部的 RecyclerView,底部显示了加载状态: 加载进度或错误信息
ConcatAdapter 简介
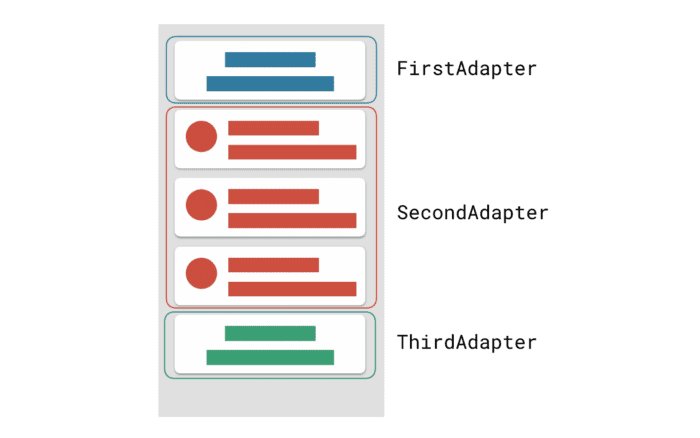
ConcatAdapter 让我们可以顺序显示多个 Adapter 中的内容。例如,假设我们有下面三个 Adapter:
val firstAdapter: FirstAdapter = …
val secondAdapter: SecondAdapter = …
val thirdAdapter: ThirdAdapter = …
val concatAdapter= ConcatAdapter(firstAdapter, secondAdapter,
thirdAdapter)
recyclerView.adapter = concatAdapter
RecyclerView 将会按 Adapter 顺序显示所有的项目。
使用不同的适配器可以使您更好地区分列表的每个部分。例如,如果要显示一个头部,可以将其封装在它自己的 Adapter 中,而无需把头部的逻辑与处理列表显示的 Adapter 混杂在一起。
![△ RecyclerView 和 Adapter 数据]()
△ RecyclerView 和 Adapter 数据
在头部和底部显示加载状态
我们可以在头部或底部显示一个进度条或错误信息。列表成功加载数据后,头部或底部便不应该再显示任何信息。这样一来,它们就可以用 Adapter 实现有 0 个或 1 个项目的列表:
val concatAdapter = ConcatAdapter(headerAdapter, listAdapter,
footerAdapter)
recyclerView.adapter = concatAdapter
如果头部和底部用的是同一布局、ViewHolder 和 UI 逻辑 (例如: 进度条要何时显示、怎么显示),您可以只实现一个 Adapter,然后创建两个实例: 一个作为头部、一个作为底部。
要获得完整的实现,请查看这里 拉取请求,它添加了:
- 从 ViewModel 中暴露出来的 LoadState
- 显示加载状态的头部和底部的布局
- 头部和底部的 ViewHolder 对象
- 一个 ListAdapter,它基于 LoadState 显示 1 或 0 个项目,每次 LoadState 有变动的时候,我们会通知相应条目进行改动、插入或移除 (您可以在 拉取请求 中查看相应的代码)。
🔎 更多关于 ConcatAdapter 的信息
ViewHolder
默认情况下,每个 Adapter 维护它们自己的 ViewHolder 池,在 Adapter 之间不会进行复用。但如果多个 Adapter 使用的是同一种 ViewHolder,我们可能会想要在 Adapter 间复用 ViewHolder 的实例。我们可以在构造 ConcatAdapter 时使用一个 ConcatAdapter.Config 对象来实现这样的效果。只要设置 isolateViewTypes = false,就可以让所有合并进来的 Adapter 使用同一个视图池。在显示加载状态的头部和底部的例子中,两种 ViewHolder 事实上使用的是相同的内容,所以我们可以复用它们。
⚠️ 如果要支持不同的 ViewHolder 类型,您应该实现 Adapter.getItemViewType 方法。当您复用 ViewHolder 时,确保同一视图类型没有对应不同的 ViewHodler!防止出现这个问题的最佳实践之一,便是将布局 ID 作为视图类型返回。
<!-- Copyright 2019 Google LLC.
SPDX-License-Identifier: Apache-2.0 -->
class HeaderAdapter() : RecyclerView.Adapter<LoadingStateViewHolderHeaderViewHolder>() {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): ViewHolder {
return LoadingStateViewHolder(parent)
}
override fun getItemViewType(position: Int): Int {
- return 0
+ return R.layout.list_loading
}
}
class FooterAdapter() : RecyclerView.Adapter<LoadingStateViewHolderFooterViewHolder>() {
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): ViewHolder {
return LoadingStateViewHolder(parent)
}
override fun getItemViewType(position: Int): Int {
- return 0
+ return R.layout.list_loading
}
}
使用 stable id
相比于使用 stable id 搭配 notifyDataSetChanged,我们更建议使用 Adapter 的特定通知事件,该事件可以为RecyclerView 提供更多有关数据集更改的信息,从而使 RecyclerView 可以更有效率地更新 UI,同时也有更好的动画效果。如果您正在使用 ListAdapter 的话,其内部会使用 DiffUtil 回调帮您处理通知事件。但是如果您需要使用 stable id,ConcatAdapter.Config 为其提供了三种不同的配置: NO_STABLE_IDS、ISOLATED_STABLE_IDS 和 SHARED_STABLE_IDS。其中后面两种需要您自己处理 Adapter 中的 stable id。您可以查看 StableIdMode 文档来获得更多关于其工作原理的信息。
数据变更通知
当 ConcatAdapter 中的一个 Adapter 调用了通知函数时,ConcatAdapter 会在更新 RecyclerView 之前计算新的项目位置。
从 RecyclerView 的角度来看,notifyItemRangeChanged 表示更新的项目相同,只是内容有所更改;notifyDataSetChanged 表示前后数据之间没有任何关系。因此,我们无法将 notifyDataSetChanged 映射到 notifyItemRangeChanged 中。
如果一个 Adapter 调用了 Adapter.notifyDataSetChanged,则 ConcatAdapter 也会调用Adapter.notifyDataSetChanged,而不是 Adapter.notifyItemRangeChanged。与 RecyclerViews 一样,我们要选择更精细的更新操作,一般情况下避免调用 Adapter.notifyDataSetChanged()。也可以使用自动执行此操作的 Adapter 实现,例如 ListAdapter 或 SortedList。
查找 ViewHolder 位置
您可能使用过 ViewHolder.getAdapterPosition 来获得 Adapter 中某个 ViewHolder 的位置。现在,因为我们合并了多个 Adapter,作为代替,您需要调用 ViewHolder.getBindingAdapterPosition()。如果您想在共享 ViewHolder 的情况下获得最后一个绑定某个 ViewHolder 的 Adapter,可以使用 ViewHolder.getBindingAdapter()。
以上就是全部了!总结一下: 如果要顺序显示不同类型的数据的同时,也希望这些数据能够封装在它们自己的 Adapter 中,请开始使用 ConcatAdapter;如果想要更进一步对 ViewHolder 池和 statle id 进行高级控制,则要使用 ConcatAdapter.Config。