回溯法(Back Tracking Method) (探索与回溯法)是一种选优搜索法,又称为试探法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
可以把回溯法看成是递归调用的一种特殊形式。
代码方面,回溯算法的框架:
result = []def backtrack (路径 , 选择列表 ):if 满足结束条件 :. add(路径 )return for 选择 in 选择列表 :做选择 路径 , 选择列表 )撤销选择 其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」 ,特别简单。
总结就是:
循环 + 递归 = 回溯引言 回溯算法 实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。
回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
算法思想 回溯(backtracking) 是一种系统地搜索问题解答的方法。为了实现回溯,首先需要为问题定义一个解空间(solution space),这个空间必须至少包含问题的一个解(可能是最优的)。下一步是组织解空间以便它能被容易地搜索。典型的组织方法是图(迷宫问题)或树(N皇后问题)。一旦定义了解空间的组织方法,这个空间即可按深度优先的方法从开始节点进行搜索。
回溯方法的步骤如下:
用深度优先法搜索该空间,利用限界函数避免移动到不可能产生解的子空间。
回溯算法的一个有趣的特性是在搜索执行的同时产生解空间。在搜索期间的任何时刻,仅保留从开始节点到当前节点的路径。因此,回溯算法的空间需求为O(从开始节点起最长路径的长度)。这个特性非常重要,因为解空间的大小通常是最长路径长度的指数或阶乘。所以如果要存储全部解空间的话,再多的空间也不够用。
算法应用 回溯算法 的求解过程实质上是一个先序遍历一棵"状态树"的过程,只是这棵树不是遍历前预先建立的,而是隐含在遍历过程中.
如对于集合A={1,2,3},则A的幂集为幂集的每个元素是一个集合,它或是空集,或含集合A中的一个元素,或含A中的两个元素,或者等于集合A。反之,集合A中的每一个元素,它只有两种状态:属于幂集的元素集,或不属于幂集元素集。则求幂集P(A)的元素的过程可看成是依次对集合A中元素进行“取”或“舍”的过程,并且可以用一棵状态树来表示。求幂集元素的过程即为先序遍历这棵状态树的过程。
递归和迭代回溯 一般情况下可以用递归函数实现回溯法,递归函数模板如下:
void BackTrace (int t) if (t>n)else for (int i = f (n, t); i <= g (n, t); i++ ) {if (Constraint(t) && Bound (t))1 );其中,t 表示递归深度,即当前扩展结点在解空间树中的深度;n 用来控制递归深度,即解空间树的高度。当 t>n时,算法已搜索到一个叶子结点,此时由函数Output(x)对得到的可行解x进行记录或输出处理。
用 f(n, t)和 g(n, t)分别表示在当前扩展结点处未搜索过的子树的起始编号和终止编号;h(i)表示在当前扩展结点处x[t] 的第i个可选值;函数 Constraint(t)和 Bound(t)分别表示当前扩展结点处的约束函数和限界函数。
若函数 Constraint(t)的返回值为真,则表示当前扩展结点处x[1:t] 的取值满足问题的约束条件;否则不满足问题的约束条件。若函数Bound(t)的返回值为真,则表示在当前扩展结点处x[1:t] 的取值尚未使目标函数越界,还需由BackTrace(t+1)对其相应的子树做进一步地搜索;否则,在当前扩展结点处x[1:t]的取值已使目标函数越界,可剪去相应的子树。
采用迭代的方式也可实现回溯算法,迭代回溯算法的模板如下:
void IterativeBackTrace (void ) int t = 1 ;while (t>0 ) {if (f(n, t) <= g( n, t))for (int i = f(n, t); i <= g(n, t); i++ ) {if (Constraint(t) && Bound(t)) {if ( Solution(t))else else t−−;在上述迭代算法中,用Solution(t)判断在当前扩展结点处是否已得到问题的一个可行解,若其返回值为真,则表示在当前扩展结点处x[1:t] 是问题的一个可行解;否则表示在当前扩展结点处x[1:t]只是问题的一个部分解,还需要向纵深方向继续搜索。用回溯法解题的一个显著特征是问题的解空间是在搜索过程中动态生成的,在任何时刻算法只保存从根结点到当前扩展结点的路径。如果在解空间树中,从根结点到叶子结点的最长路径长度为 h(n),则回溯法所需的计算空间复杂度为 O(h(n)),而显式地存储整个解空间复杂度则需要O(2h(n))或O(h(n)!)。
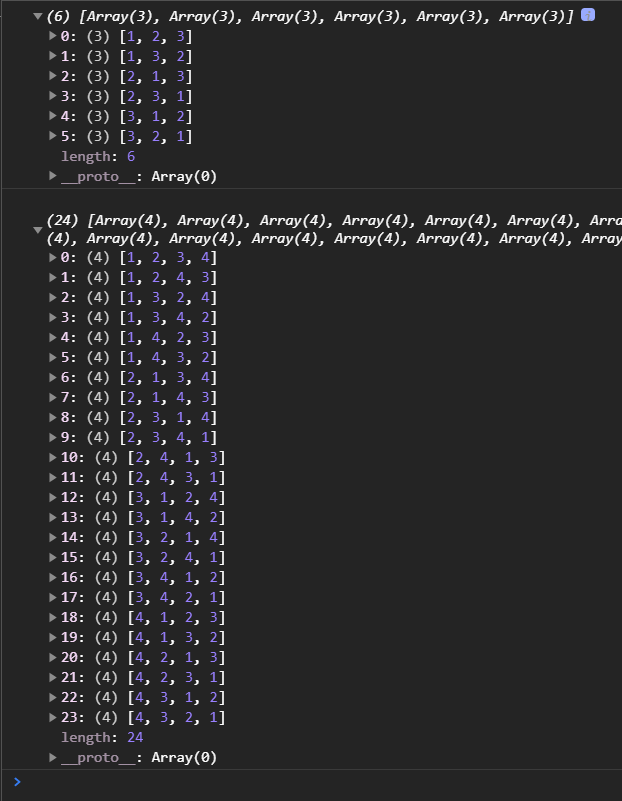
全排列 function DFS (nums = [] ) let res = [];const dfs = (path = [] ) => {if (path.length == nums.length) {return ;for (let i = 0 ; i < nums.length; i++) {if (path.includes(nums[i])) {continue ;return res;console .log(DFS([1 , 2 , 3 ]));console .log(DFS([1 , 2 , 3 , 4 ]));
function permuts (nums = [] ) let res = [];const swap = (p, q ) => {if (p == q) return ;const dfs = (p, q ) => {if (p == q) {return ;for (let i = p; i <= q; i++) {1 , q);0 , nums.length - 1 );return res;console .log(permuts([1 , 2 , 3 ]));