之所以有这么大的差距,是因为二维数组 array 所占用的内存是连续的,比如长度 N 的指是 2 的话,那么内存中的数组元素的布局顺序是这样的:
形式一用 array[i][j] 访问数组元素的顺序,正是和内存中数组元素存放的顺序一致。当 CPU 访问 array[0][0] 时,由于该数据不在 Cache 中,于是会「顺序」把跟随其后的 3 个元素从内存中加载到 CPU Cache,这样当 CPU 访问后面的 3 个数组元素时,就能在 CPU Cache 中成功地找到数据,这意味着缓存命中率很高,缓存命中的数据不需要访问内存,这便大大提高了代码的性能。
而如果用形式二的 array[j][i] 来访问,则访问的顺序就是:
你可以看到,访问的方式跳跃式的,而不是顺序的,那么如果 N 的数值很大,那么操作 array[j][i] 时,是没办法把 array[j+1][i] 也读入到 CPU Cache 中的,既然 array[j+1][i] 没有读取到 CPU Cache,那么就需要从内存读取该数据元素了。很明显,这种不连续性、跳跃式访问数据元素的方式,可能不能充分利用到了 CPU Cache 的特性,从而代码的性能不高。
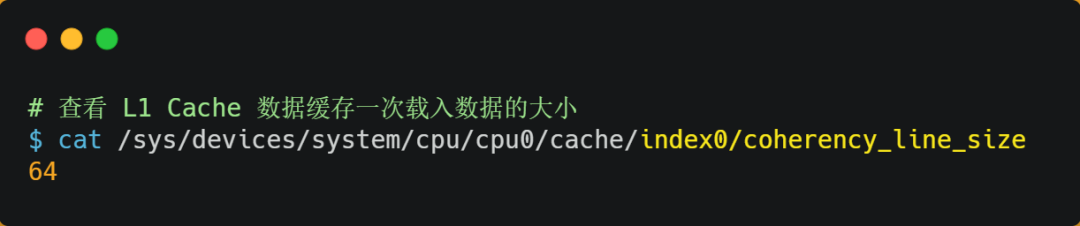
那访问 array[0][0] 元素时,CPU 具体会一次从内存中加载多少元素到 CPU Cache 呢?这个问题,在前面我们也提到过,这跟 CPU Cache Line 有关,它表示 CPU Cache 一次性能加载数据的大小,可以在 Linux 里通过 coherency_line_size 配置查看 它的大小,通常是 64 个字节。
也就是说,当 CPU 访问内存数据时,如果数据不在 CPU Cache 中,则会一次性会连续加载 64 字节大小的数据到 CPU Cache,那么当访问 array[0][0] 时,由于该元素不足 64 字节,于是就会往后顺序读取 array[0][0]~array[0][15] 到 CPU Cache 中。顺序访问的 array[i][j] 因为利用了这一特点,所以就会比跳跃式访问的 array[j][i] 要快。
因此,遇到这种遍历数组的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升,
如何提升指令缓存的命中率?
提升数据的缓存命中率的方式,是按照内存布局顺序访问,那针对指令的缓存该如何提升呢?
我们以一个例子来看看,有一个元素为 0 到 100 之间随机数字组成的一维数组:
接下来,对这个数组做两个操作:
第一个操作,循环遍历数组,把小于 50 的数组元素置为 0;
第二个操作,将数组排序;
那么问题来了,你觉得先遍历再排序速度快,还是先排序再遍历速度快呢?
在回答这个问题之前,我们先了解 CPU 的分支预测器。对于 if 条件语句,意味着此时至少可以选择跳转到两段不同的指令执行,也就是 if 还是 else 中的指令。那么,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
而现代 CPU 都是多核心的,进程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个进程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果进程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
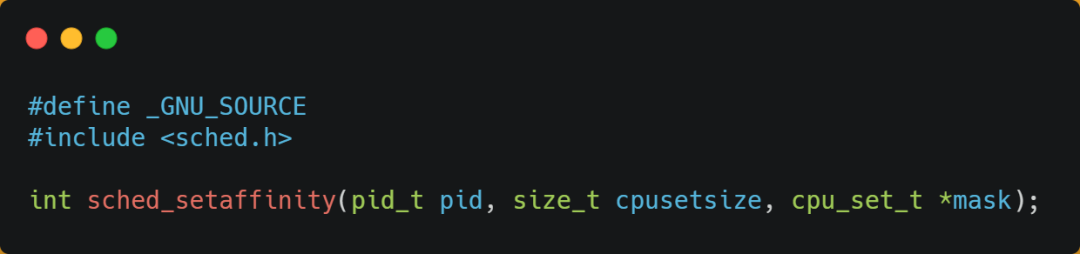
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
总结
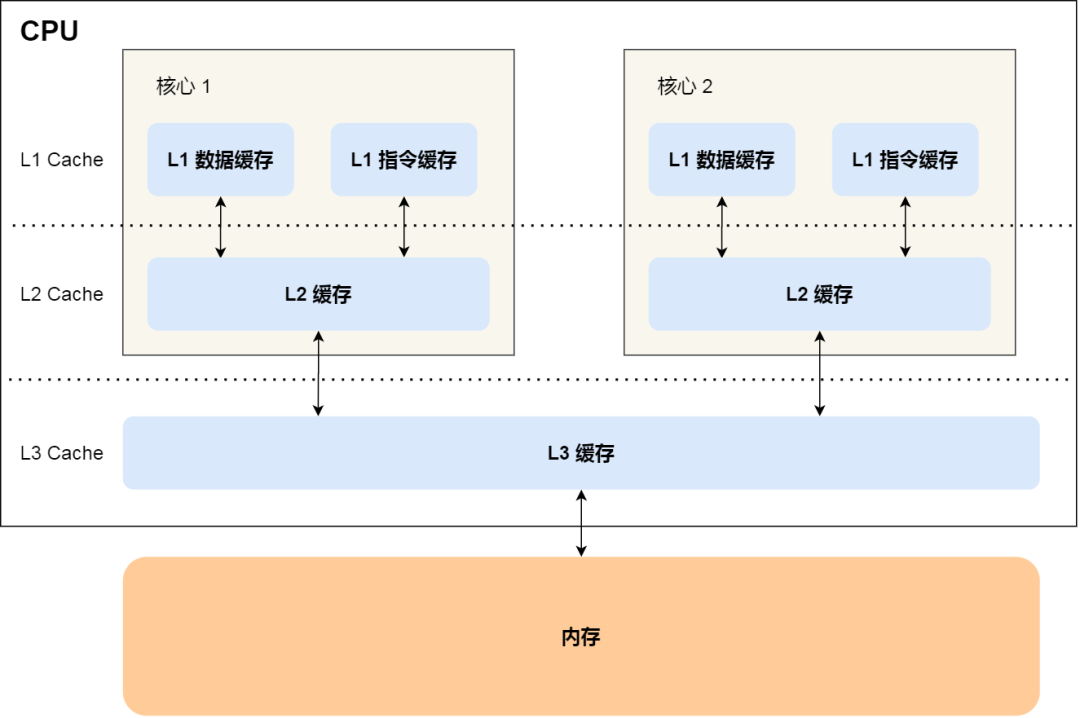
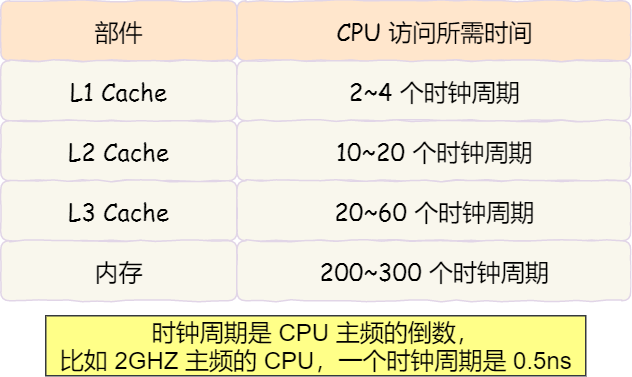
由于随着计算机技术的发展,CPU 与 内存的访问速度相差越来越多,如今差距已经高达好几百倍了,所以 CPU 内部嵌入了 CPU Cache 组件,作为内存与 CPU 之间的缓存层,CPU Cache 由于离 CPU 核心很近,所以访问速度也是非常快的,但由于所需材料成本比较高,它不像内存动辄几个 GB 大小,而是仅有几十 KB 到 MB 大小。
当 CPU 访问数据的时候,先是访问 CPU Cache,如果缓存命中的话,则直接返回数据,就不用每次都从内存读取速度了。因此,缓存命中率越高,代码的性能越好。
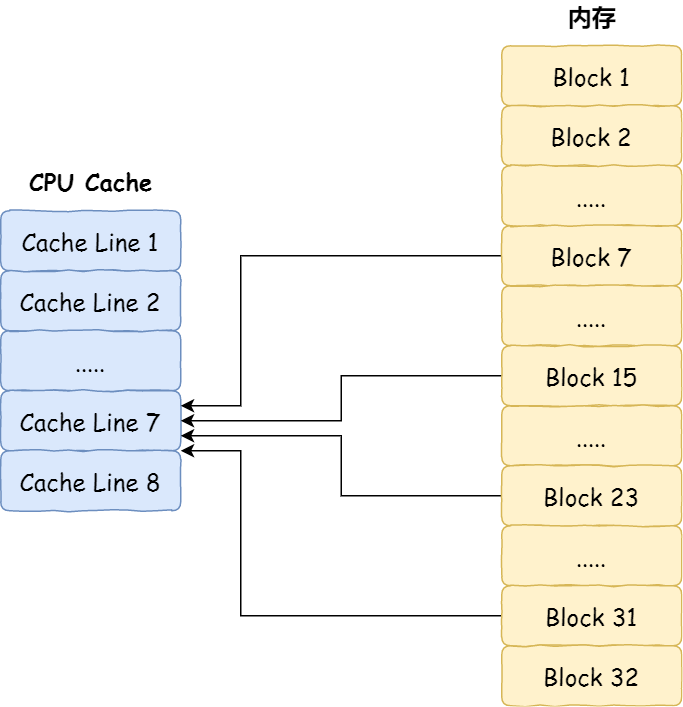
但需要注意的是,当 CPU 访问数据时,如果 CPU Cache 没有缓存该数据,则会从内存读取数据,但是并不是只读一个数据,而是一次性读取一块一块的数据存放到 CPU Cache 中,之后才会被 CPU 读取。
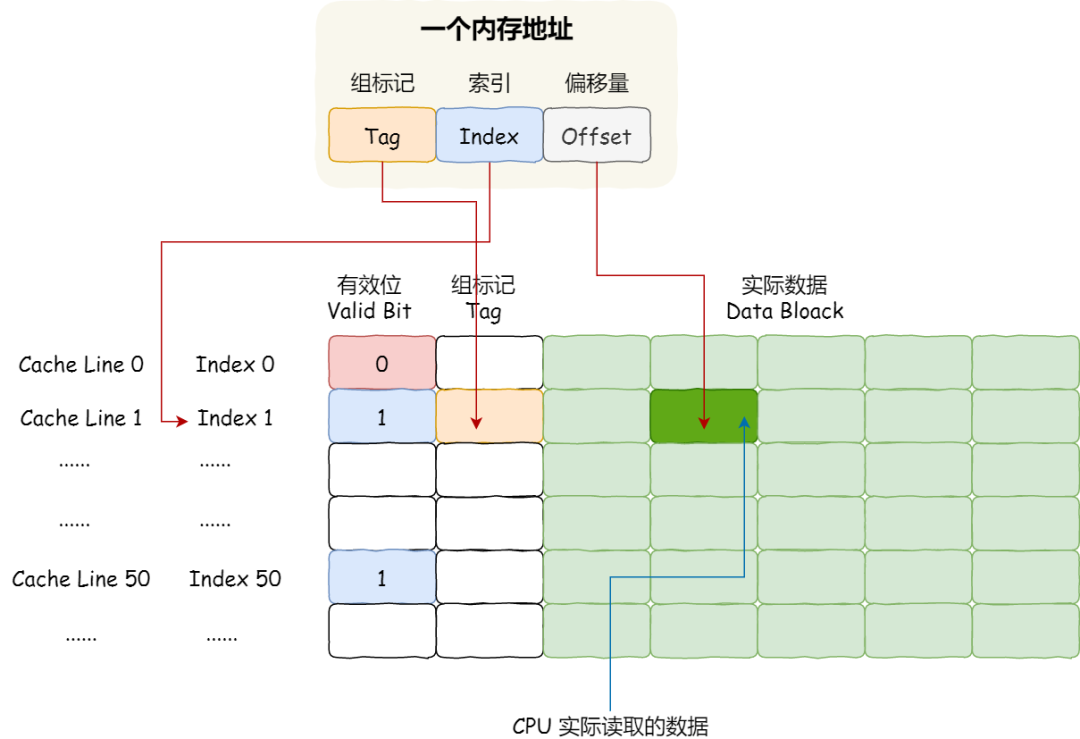
内存地址映射到 CPU Cache 地址里的策略有很多种,其中比较简单是直接映射 Cache,它巧妙的把内存地址拆分成「索引 + 组标记 + 偏移量」的方式,使得我们可以将很大的内存地址,映射到很小的 CPU Cache 地址里。
要想写出让 CPU 跑得更快的代码,就需要写出缓存命中率高的代码,CPU L1 Cache 分为数据缓存和指令缓存,因而需要分别提高它们的缓存命中率:
对于数据缓存,我们在遍历数据的时候,应该按照内存布局的顺序操作,这是因为 CPU Cache 是根据 CPU Cache Line 批量操作数据的,所以顺序地操作连续内存数据时,性能能得到有效的提升;
对于指令缓存,有规律的条件分支语句能够让 CPU 的分支预测器发挥作用,进一步提高执行的效率;
另外,对于多核 CPU 系统,线程可能在不同 CPU 核心来回切换,这样各个核心的缓存命中率就会受到影响,于是要想提高进程的缓存命中率,可以考虑把线程绑定 CPU 到某一个 CPU 核心。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。