目录
一、前言
二、面试题
三、ThreadLocal 分析
1. 应用场景
2. 数据结构
3. 散列算法
4. 源码解读
四、总结
五、系列推荐
一、前言 说到底,你真的会造火箭吗?
常说面试造火箭,入职拧螺丝。但你真的有造火箭的本事吗,大部分都是不敢承认自己的知识盲区和技术瓶颈以及经验不足的自嘲。
「面试时」 :
我希望你懂数据结构,因为这样的你在使用HashMap、ArrayList、LinkedList,更加得心应手。
我希望你懂散列算法,因为这样的你在设计路由时,会有很多选择; 除法散列法、 平方散列法、 斐波那契(Fibonacci)散列法等。
我希望你懂开源代码,因为这样的你在遇到问题时,可以快速定位,还可能创造出一些系统服务的中间件,来更好的解耦系统。
我希望你懂设计模式,因为这样的你可以写出可扩展、易维护的程序,让整个团队都能向更好的方向发展。
「所以」 ,从不是CRUD选择了你,也不是造螺丝让你成为工具人。而是你的技术能力决定你的眼界,眼界又决定了你写出的代码!
二、面试题 谢飞机,小记 还没有拿到 offer 的飞机,早早起了床,吃完两根油条,又跑到公司找面试官取经!
「面试官」 :飞机,听坦克说,你最近贪黑起早的学习呀。
「谢飞机」 :嗯嗯,是的,最近头发都快掉没了!
「面试官」 :那今天我们聊聊 ThreadLocal,一般可以用在什么场景中?
「谢飞机」 :嗯,ThreadLocal 要解决的是线程内资源共享 (This class provides thread-local variables. ),所以一般会用在全链路监控中,或者是像日志框架 MDC 这样的组件里。
「面试官」 :飞机不错哈,最近确实学习了。那你知道 ThreadLocal是怎样的数据结构吗,采用的是什么散列方式?
「谢飞机」 :数组?嗯,怎么散列的不清楚...
「面试官」 :那 ThreadLocal 有内存泄漏的风险,是怎么发生的呢?另外你了解在这个过程的,探测式清理和启发式清理吗?
「谢飞机」 :这...,盲区了,盲区了,可乐我放桌上了,我回家再看看书!
三、ThreadLocal 分析 ThreadLocal,作者:Josh Bloch and Doug Lea,两位大神👍
如果仅是日常业务开发来看,这是一个比较冷门的类,使用频率并不高。并且它提供的方法也非常简单,一个功能只是潦潦数行代码。「但」 ,如果深挖实现部分的源码,就会发现事情并不那么简单。这里涉及了太多的知识点,包括;数据结构、拉链存储、斐波那契散列、神奇的0x61c88647、弱引用Reference、过期key探测清理和启发式清理等等。
接下来,我们就逐步学习这些「盲区知识」 。本文涉及了较多的代码和实践验证图稿,欢迎关注公众号:bugstack虫洞栈,回复下载得到一个链接打开后,找到ID:19🤫获取!*
private SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss" );public void seckillSku () new Date());// 业务流程 你写过这样的代码吗?如果还在这么写,那就已经犯了一个线程安全的错误。SimpleDateFormat,并不是一个线程安全的类。
private static SimpleDateFormat f = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss" );public static void main (String[] args) while (true ) {new Thread(() -> {new Date());try {boolean equals = dateStr.equals(dateStrCheck);if (!equals) {" " + dateStr + " " + dateStrCheck);else {catch (ParseException e) {这是一个多线程下 SimpleDateFormat 的验证代码。当 equals 为false 时,证明线程不安全。运行结果如下;
true true false 2020 -09 -23 11 :40 :42 2230 -09 -23 11 :40 :42 true true false 2020 -09 -23 11 :40 :42 2020 -09 -23 11 :40 :00 false 2020 -09 -23 11 :40 :42 2020 -09 -23 11 :40 :00 false 2020 -09 -23 11 :40 :00 2020 -09 -23 11 :40 :42 true false 2020 -09 -23 11 :40 :42 2020 -08 -31 11 :40 :42 true 为了线程安全最直接的方式,就是每次调用都直接 new SimpleDateFormat。但这样的方式终究不是最好的,所以我们使用 ThreadLocal ,来优化这段代码。
private static ThreadLocal<SimpleDateFormat> threadLocal = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss" ));public static void main (String[] args) while (true ) {new Thread(() -> {new Date());try {boolean equals = dateStr.equals(dateStrCheck);if (!equals) {" " + dateStr + " " + dateStrCheck);else {catch (ParseException e) {如上我们把 SimpleDateFormat ,放到 ThreadLocal 中进行使用,即不需要重复new对象,也避免了线程不安全问题。测试结果如下;
true true true true true true true 近几年基于谷歌Dapper论文实现非入侵全链路追踪,使用的越来越广了。简单说这就是一套监控系统,但不需要你硬编码的方式进行监控方法,而是基于它的设计方案采用 javaagent + 字节码 插桩的方式,动态采集方法执行信息。如果你想了解字节码插桩技术,可以阅读我的字节码编程专栏:https://bugstack.cn/itstack-demo-agent/itstack-demo-agent.html
「重点」 ,动态采集方法执行信息。这块是主要部分,跟 ThreadLocal 相关。字节码插桩解决的是非入侵式编程,那么在一次服务调用时,在各个系统间以及系统内多个方法的调用,都需要进行采集。这个时候就需要使用 ThreadLocal 记录方法执行ID,当然这里还有跨线程调用使用的也是增强版本的 ThreadLocal,但无论如何基本原理不变。
「这里举例全链路方法调用链追踪,部分代码」
public class TrackContext private static final ThreadLocal<String> trackLocal = new ThreadLocal<>();public static void clear () public static String getLinkId () return trackLocal.get();public static void setLinkId (String linkId) @Advice .OnMethodEnter()public static void enter (@Advice.Origin("#t" ) String className, @Advice.Origin ("#m" ) String methodName) if (null == currentSpan) {@Advice .OnMethodExit()public static void exit (@Advice.Origin("#t" ) String className, @Advice.Origin ("#m" ) String methodName) if (null == exitSpan) return ;"链路追踪(MQ):" + exitSpan.getLinkId() + " " + className + "." + methodName + " 耗时:" + (System.currentTimeMillis() - exitSpan.getEnterTime().getTime()) + "ms" );
这也只是其中一个实现方式,字节码插桩使用的是 byte-buddy,其实还是使用, ASM 或者 Javassist。
「测试方法」
配置参数:-javaagent:E:\itstack\GIT\itstack.org\itstack-demo-agent\itstack-demo-agent-06\target\itstack-demo-agent-06-1.0.0-SNAPSHOT.jar=testargs
public void http_lt1 (String name) try {long ) (Math.random() * 500 ));catch (InterruptedException e) {"测试结果:hi1 " + name);public void http_lt2 (String name) try {long ) (Math.random() * 500 ));catch (InterruptedException e) {"测试结果:hi2 " + name);「运行结果」
onTransformation:class org .itstack .demo .test .ApiTest hi2 悟空hi3 悟空MQ ):90c7d543 -c7b8 -4ec3 -af4d -b4d4f5cff760 org .itstack .demo .test .ApiTest .http_lt3 耗时:104ms init : 256MB max : 3614MB used : 44MB committed : 245MB use rate : 18%init : 2MB max : 0MB used : 13MB committed : 14MB use rate : 95%name : PS Scavenge count :0 took :0 pool name :[PS Eden Space , PS Survivor Space ]name : PS MarkSweep count :0 took :0 pool name :[PS Eden Space , PS Survivor Space , PS Old Gen ]MQ ):90c7d543 -c7b8 -4ec3 -af4d -b4d4f5cff760 org .itstack .demo .test .ApiTest .http_lt2 耗时:233ms init : 256MB max : 3614MB used : 44MB committed : 245MB use rate : 18%init : 2MB max : 0MB used : 13MB committed : 14MB use rate : 96%name : PS Scavenge count :0 took :0 pool name :[PS Eden Space , PS Survivor Space ]name : PS MarkSweep count :0 took :0 pool name :[PS Eden Space , PS Survivor Space , PS Old Gen ]
以上是链路追踪的测试结果,可以看到两个方法都会打出相应的编码ID: 90c7d543-c7b8-4ec3-af4d-b4d4f5cff760。
这部分也就是全链路追踪的核心应用,而且还可以看到这里打印了一些系统简单的JVM监控指标,这也是监控的一部分。
「咳咳」 ,除此之外所有需要活动方法调用链的,都需要使用到 ThreadLocal,例如 MDC 日志框架等。接下来我们开始详细分析 ThreadLocal 的实现。
了解一个功能前,先了解它的数据结构。这就相当于先看看它的地基,有了这个根本也就好往后理解了。以下是 ThreadLocal 的简单使用以及部分源码。
new ThreadLocal<String>().set("小傅哥");
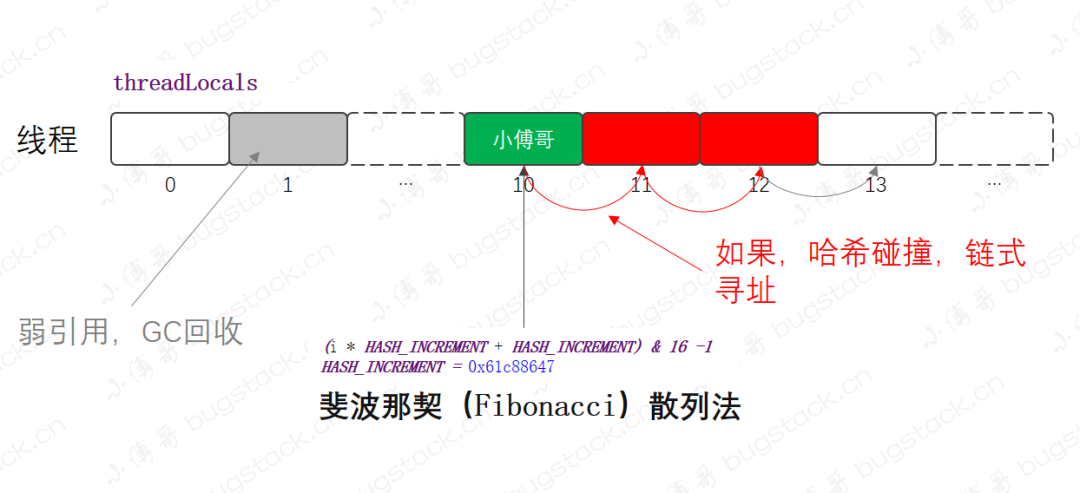
private void set (ThreadLocal<?> key, Object value) int len = tab.length;int i = key.threadLocalHashCode & (len-1 );for (Entry e = tab[i];null ;从这部分源码中可以看到,ThreadLocal 底层采用的是数组结构存储数据,同时还有哈希值计算下标,这说明它是一个散列表的数组结构,演示如下图;
如上图是 ThreadLocal 存放数据的底层数据结构,包括知识点如下;
Entry,这里没用再打开,其实它是一个弱引用实现, static class Entry extends WeakReference<ThreadLocal<?>>。这说明只要没用强引用存在,发生GC时就会被垃圾回收。
数据元素采用哈希散列方式进行存储,不过这里的散列使用的是 斐波那契(Fibonacci)散列法,后面会具体分析。
另外由于这里不同于HashMap的数据结构,发生哈希碰撞不会存成链表或红黑树,而是使用拉链法进行存储。也就是同一个下标位置发生冲突时,则 +1向后寻址,直到找到空位置或垃圾回收位置进行存储。
既然 ThreadLocal 是基于数组结构的拉链法存储,那就一定会有哈希的计算。但我们翻阅源码后,发现这个哈希计算与 HashMap 中的散列求数组下标计算的哈希方式不一样。如果你忘记了HashMap,可以翻阅文章《HashMap 源码分析,插入、查找》 、《HashMap 扰动函数、负载因子》
当我们查看 ThreadLocal 执行设置元素时,有这么一段计算哈希值的代码;
private static final int HASH_INCREMENT = 0x61c88647 ;private static int nextHashCode () return nextHashCode.getAndAdd(HASH_INCREMENT);「看到这里你一定会有这样的疑问,这是什么方式计算哈希?这个数字怎么来的?」
讲到这里,其实计算哈希的方式,绝不止是我们平常看到 String 获取哈希值的一种方式,还包括;除法散列法、平方散列法、斐波那契(Fibonacci)散列法、随机数法等。
而 ThreadLocal 使用的就是 斐波那契(Fibonacci)散列法 + 拉链法存储数据到数组结构中。之所以使用斐波那契数列,是为了让数据更加散列,减少哈希碰撞。具体来自数学公式的计算求值,「公式」 :f(k) = ((k * 2654435769) >> X) << Y对于常见的32位整数而言,也就是 f(k) = (k * 2654435769) >> 28
「第二个问题」 ,数字 0x61c88647,是怎么来的?
其实这是一个哈希值的黄金分割点,也就是 0.618,你还记得你学过的数学吗?计算方式如下;
// 黄金分割点:(√5 - 1) / 2 = 0.6180339887 1.618:1 == 1:0.618 2 , 32 ) * 0.6180339887 ).intValue()); //-1640531527
学过数学都应该知道,黄金分割点是, (√5 - 1) / 2,取10位近似 0.6180339887。
之后用 2 ^ 32 * 0.6180339887,得到的结果是: -1640531527,也就是 16 进制的,0x61c88647。 这个数呢也就是这么来的
既然,Josh Bloch 和 Doug Lea,两位老爷子选择使用斐波那契数列,计算哈希值。那一定有它的过人之处,也就是能更好的散列,减少哈希碰撞。
接下来我们按照源码中获取哈希值和计算下标的方式,把这部分代码提出出来做验证。
private static AtomicInteger nextHashCode = new AtomicInteger();private static final int HASH_INCREMENT = 0x61c88647 ;// 计算哈希 private static int nextHashCode () return nextHashCode.getAndAdd(HASH_INCREMENT);// 获取下标 int i = key.threadLocalHashCode & (len-1 );如上,源码部分采用的是 AtomicInteger,原子方法计算下标。我们不需要保证线程安全,只需要简单实现即可。另外 ThreadLocal 初始化数组长度是16,我们也初始化这个长度。
@Test public void test_idx () int hashCode = 0 ;for (int i = 0 ; i < 16 ; i++) {int idx = hashCode & 15 ;"斐波那契散列:" + idx + " 普通散列:" + (String.valueOf(i).hashCode() & 15 ));测试代码部分,采用的就是斐波那契数列,同时我们加入普通哈希算法进行比对散列效果。当然String 这个哈希并没有像 HashMap 中进行扰动
「测试结果」 :
斐波那契散列:7 普通散列:0 14 普通散列:1 5 普通散列:2 12 普通散列:3 3 普通散列:4 10 普通散列:5 1 普通散列:6 8 普通散列:7 15 普通散列:8 6 普通散列:9 13 普通散列:15 4 普通散列:0 11 普通散列:1 2 普通散列:2 9 普通散列:3 0 普通散列:4 0 「发现没?」 ,斐波那契散列的非常均匀,普通散列到15个以后已经开发生产碰撞。这也就是斐波那契散列的魅力,减少碰撞也就可以让数据存储的更加分散,获取数据的时间复杂度基本保持在O(1)。
new ThreadLocal<>()
初始化的过程也很简单,可以按照自己需要的泛型进行设置。但在 ThreadLocal 的源码中有一点非常重要,就是获取 threadLocal 的哈希值的获取,threadLocalHashCode。
private final int threadLocalHashCode = nextHashCode();/** private static int nextHashCode () return nextHashCode.getAndAdd(HASH_INCREMENT);如源码中,只要实例化一个 ThreadLocal ,就会获取一个相应的哈希值,则例我们做一个例子。
@Test public void test_threadLocalHashCode () throws Exception for (int i = 0 ; i < 5 ; i++) {new ThreadLocal<>();"threadLocalHashCode" );true );"objectThreadLocal:" + threadLocalHashCode.get(objectThreadLocal));因为 threadLocalHashCode ,是一个私有属性,所以我们实例化后通过上面的方式进行获取哈希值。
objectThreadLocal:-1401181199 239350328 1879881855 774553914 865977613 0 这个值的获取,也就是计算 ThreadLocalMap,存储数据时,ThreadLocal 的数组下标。只要是这同一个对象,在set、get时,就可以设置和获取对应的值。
new ThreadLocal<>().set("小傅哥");
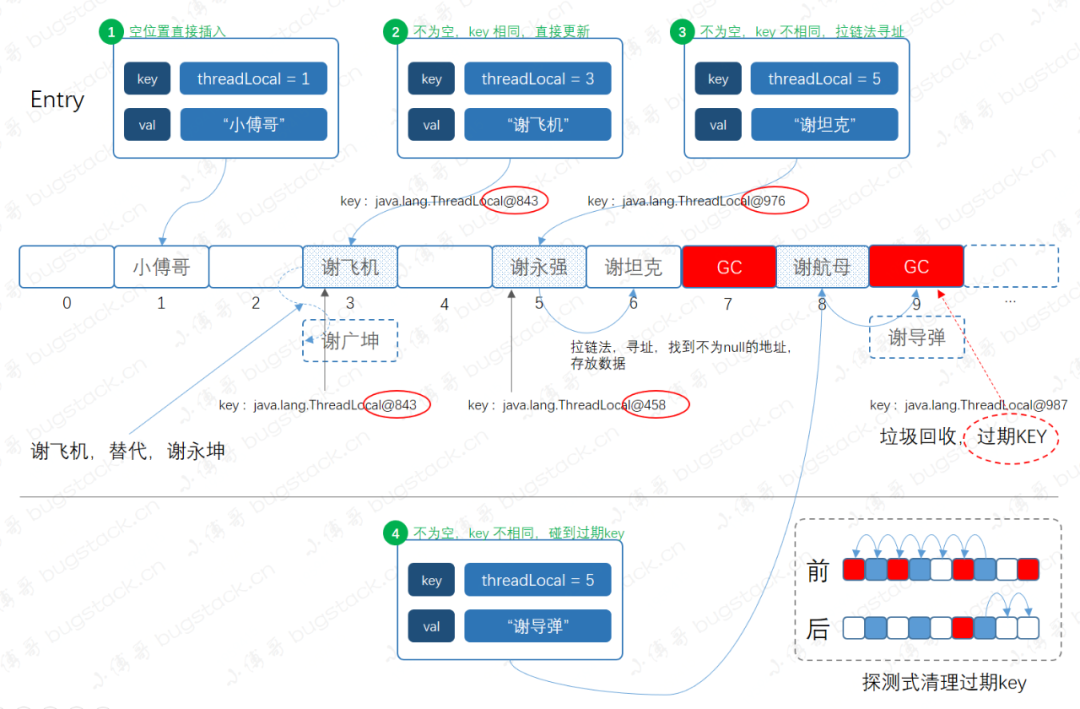
设置元素的方法,也就这么一句代码。但设置元素的流程却涉及的比较多,在详细分析代码前,我们先来看一张设置元素的流程图,从图中先了解不同情况的流程之后再对比着学习源码。流程图如下;
乍一看可能感觉有点晕,我们从左往右看,分别有如下知识点;0. 中间是 ThreadLocal 的数组结构,之后在设置元素时分为四种不同的情况,另外元素的插入是通过斐波那契散列计算下标值,进行存放的。
情况2,待插入的下标,不为空,key 相同,直接更新
情况3,待插入的下标,不为空,key 不相同,拉链法寻址
情况4,不为空,key 不相同,碰到过期key。其实情况4,遇到的是弱引用发生GC时,产生的情况。碰到这种情况, ThreadLocal 会进行探测清理过期key,这部分清理内容后续讲解。
private void set (ThreadLocal<?> key, Object value) int len = tab.length;int i = key.threadLocalHashCode & (len-1 );for (Entry e = tab[i];null ;if (k == key) {return ;if (k == null ) {return ;new Entry(key, value);int sz = ++size;if (!cleanSomeSlots(i, sz) && sz >= threshold)在有了上面的图解流程,再看代码部分就比较容易理解了,与之对应的内容包括,如下;
key.threadLocalHashCode & (len-1);,斐波那契散列,计算数组下标。
Entry,是一个弱引用对象的实现类, static class Entry extends WeakReference<ThreadLocal<?>>,所以在没有外部强引用下,会发生GC,删除key。
for循环判断元素是否存在,当前下标不存在元素时,直接设置元素 tab[i] = new Entry(key, value);。
如果元素存在,则会判断是否key值相等 if (k == key),相等则更新值。
如果不相等,就到了我们的 replaceStaleEntry,也就是上图说到的探测式清理过期元素。
「综上」 ,就是元素存放的全部过程,整体结构的设计方式非常赞👍,极大的利用了散列效果,也把弱引用使用的非常6!
只要使用到数组结构,就一定会有扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)在我们阅读设置元素时,有以上这么一块代码,判断是否扩容。
首先,进行 启发式清理*cleanSomeSlots*,把过期元素清理掉,看空间是否
之后,判断 sz >= threshold,其中 threshold = len * 2 / 3,也就是说数组中天填充的元素,大于 len * 2 / 3,就需要扩容了。
最后,就是我们要分析的重点, rehash();,扩容重新计算元素位置。
「探测式清理和校验」
private void rehash () // Use lower threshold for doubling to avoid hysteresis if (size >= threshold - threshold / 4 )private void expungeStaleEntries () int len = tab.length;for (int j = 0 ; j < len; j++) {if (e != null && e.get() == null )
这部分是主要是探测式清理过期元素,以及判断清理后是否满足扩容条件,size >= threshold * 3/4
满足后执行扩容操作,其实扩容完的核心操作就是重新计算哈希值,把元素填充到新的数组中。
「rehash() 扩容」
private void resize () int oldLen = oldTab.length;int newLen = oldLen * 2 ;new Entry[newLen];int count = 0 ;for (int j = 0 ; j < oldLen; ++j) {if (e != null ) {if (k == null ) {null ; // Help the GC else {int h = k.threadLocalHashCode & (newLen - 1 );while (newTab[h] != null )「以上」 ,代码就是扩容的整体操作,具体包括如下步骤;
首先把数组长度扩容到原来的2倍, oldLen * 2,实例化新数组。
遍历for,所有的旧数组中的元素,重新放到新数组中。
在放置数组的过程中,如果发生哈希碰撞,则链式法顺延。
同时这还有检测key值的操作 if (k == null),方便GC。
new ThreadLocal<>().get();
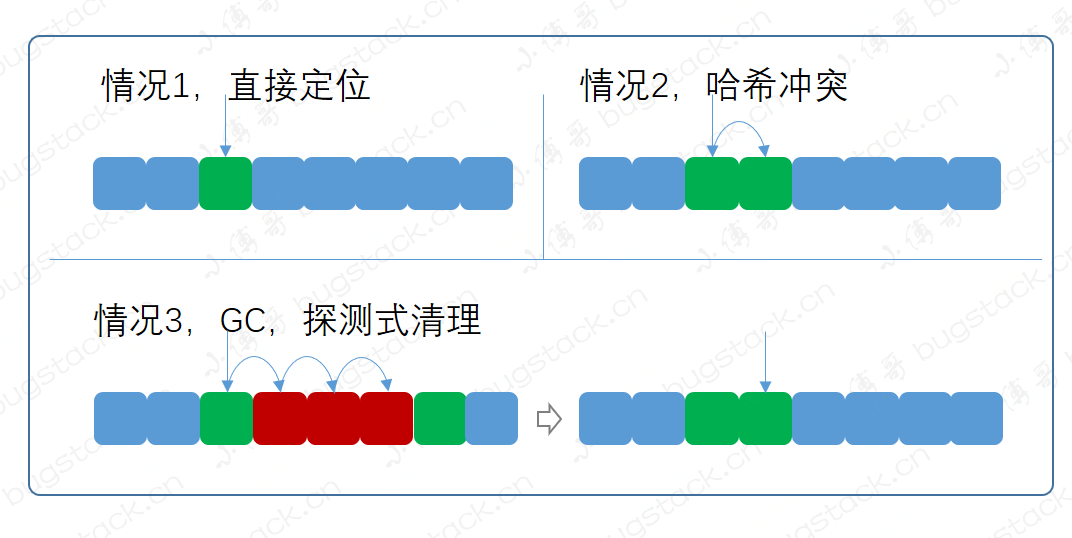
同样获取元素也就这么一句代码,如果没有分析源码之前,你能考虑到它在不同的数据结构下,获取元素时候都做了什么操作吗。我们先来看下图,分为如下种情况;
按照不同的数据元素存储情况,基本包括如下情况;
没有直接定位到了,key不同,拉链式寻找,遇到GC清理元素,需要探测式清理,再寻找元素。
private Entry getEntry (ThreadLocal<?> key) int i = key.threadLocalHashCode & (table.length - 1 );if (e != null && e.get() == key)return e;else return getEntryAfterMiss(key, i, e);private Entry getEntryAfterMiss (ThreadLocal<?> key, int i, Entry e) int len = tab.length;while (e != null ) {if (k == key)return e;if (k == null )else return null ;「好了」 ,这部分就是获取元素的源码部分,和我们图中列举的情况是一致的。expungeStaleEntry,是发现有 key == null 时,进行清理过期元素,并把后续位置的元素,前移。
探测式清理,是以当前遇到的 GC 元素开始,向后不断的清理。直到遇到 null 为止,才停止 rehash 计算Rehash until we encounter null。
「expungeStaleEntry」
private int expungeStaleEntry (int staleSlot) int len = tab.length;// expunge entry at staleSlot null ;null ;// Rehash until we encounter null int i;for (i = nextIndex(staleSlot, len);null ;if (k == null ) {null ;null ;else {int h = k.threadLocalHashCode & (len - 1 );if (h != i) {null ;// Unlike Knuth 6.4 Algorithm R, we must scan until // null because multiple entries could have been stale. while (tab[h] != null )return i;「以上」 ,探测式清理在获取元素中使用到;new ThreadLocal<>().get() -> map.getEntry(this) -> getEntryAfterMiss(key, i, e) -> expungeStaleEntry(i)
Heuristically scan some cells looking for stale entries.new element is added, oras a balance between noscanning (fast but retains garbage) and a number of scansO (n) time. 「启发式清理」 ,有这么一段注释,大概意思是;试探的扫描一些单元格,寻找过期元素,也就是被垃圾回收的元素。当添加新元素或删除另一个过时元素时,将调用此函数。它执行对数扫描次数,作为不扫描(快速但保留垃圾)和与元素数量成比例的扫描次数之间的平衡,这将找到所有垃圾,但会导致一些插入花费O(n)时间。
private boolean cleanSomeSlots (int i, int n) boolean removed = false ;int len = tab.length;do {if (e != null && e.get() == null ) {true ;while ( (n >>>= 1 ) != 0 );return removed;while 循环中不断的右移进行寻找需要被清理的过期元素,最终都会使用 expungeStaleEntry 进行处理,这里还包括元素的移位。
四、总结
写到这算是把 ThreadLocal 知识点的一角分析完了,在 ThreadLocal 的家族里还有 Netty 中用到的, FastThreadLocal。在全链路跨服务线程间获取调用链路,还有 TransmittableThreadLocal,另外还有 JDK 本身自带的一种线程传递解决方案 InheritableThreadLocal。但站在本文的基础上,了解了最基础的原理,在理解其他的拓展设计,就更容易接受了。
此外在我们文中分析时经常会看到探测式清理,其实这也是非常耗时。为此我们在使用 ThreadLocal 一定要记得 new ThreadLocal<>().remove(); 操作。避免弱引用发生GC后,导致内存泄漏的问题。
「最后」 ,你发现了吗!我们学习这样的底层原理性知识,都离不开数据结构和良好的设计方案,或者说是算法的身影。这些代码才是支撑整个系统良好运行的地基,如果我们可以把一些思路抽取到我们开发的核心业务流程中,也是可以大大提升性能的。
五、系列推荐