简介
TCP是一种面向广域网的通信协议,目的是在跨越多个网络通信时,为两个通信端点之间提供一条具有下列特点的通信方式
(1)基于流的方式;
(2)面向连接;
(3)可靠通信方式;
(4)在网络状况不佳的时候尽量降低系统由于重传带来的带宽开销;
(5)通信连接维护是面向通信的两个端点的,而不考虑中间网段和节点。
为满足TCP协议的这些特点,TCP协议做了如下的规定
1. 数据分片:在发送端对用户数据进行分片,在接收端进行重组,由TCP确定分片的大小并控制分片和重组;
2. 到达确认:接收端接收到分片数据时,根据分片数据序号向发送端发送一个确认;
3. 超时重发:发送方在发送分片时启动超时定时器,如果在定时器超时之后没有收到相应的确认,重发分片;
4. 滑动窗口:TCP连接每一方的接收缓冲空间大小都固定,接收端只允许另一端发送接收端缓冲区所能接纳的数据,TCP在滑动窗口的基础上提供流量控制,防止较快主机致使较慢主机的缓冲区溢出;
5. 失序处理:作为IP数据报来传输的TCP分片到达时可能会失序,TCP将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层;
6. 重复处理:作为IP数据报来传输的TCP分片会发生重复,TCP的接收端必须丢弃重复的数据;
7. 数据校验:TCP将保持它首部和数据的检验和,这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到分片的检验和有差错,TCP将丢弃这个分片,并不确认收到此报文段导致对端超时并重发。
以上概念摘自百度百科
https://baike.baidu.com/item/TCP/33012?fr=aladdin
不是很熟悉的或者看到概念头疼的估计已经不想看下去了
所以,我来讲点实际的东西
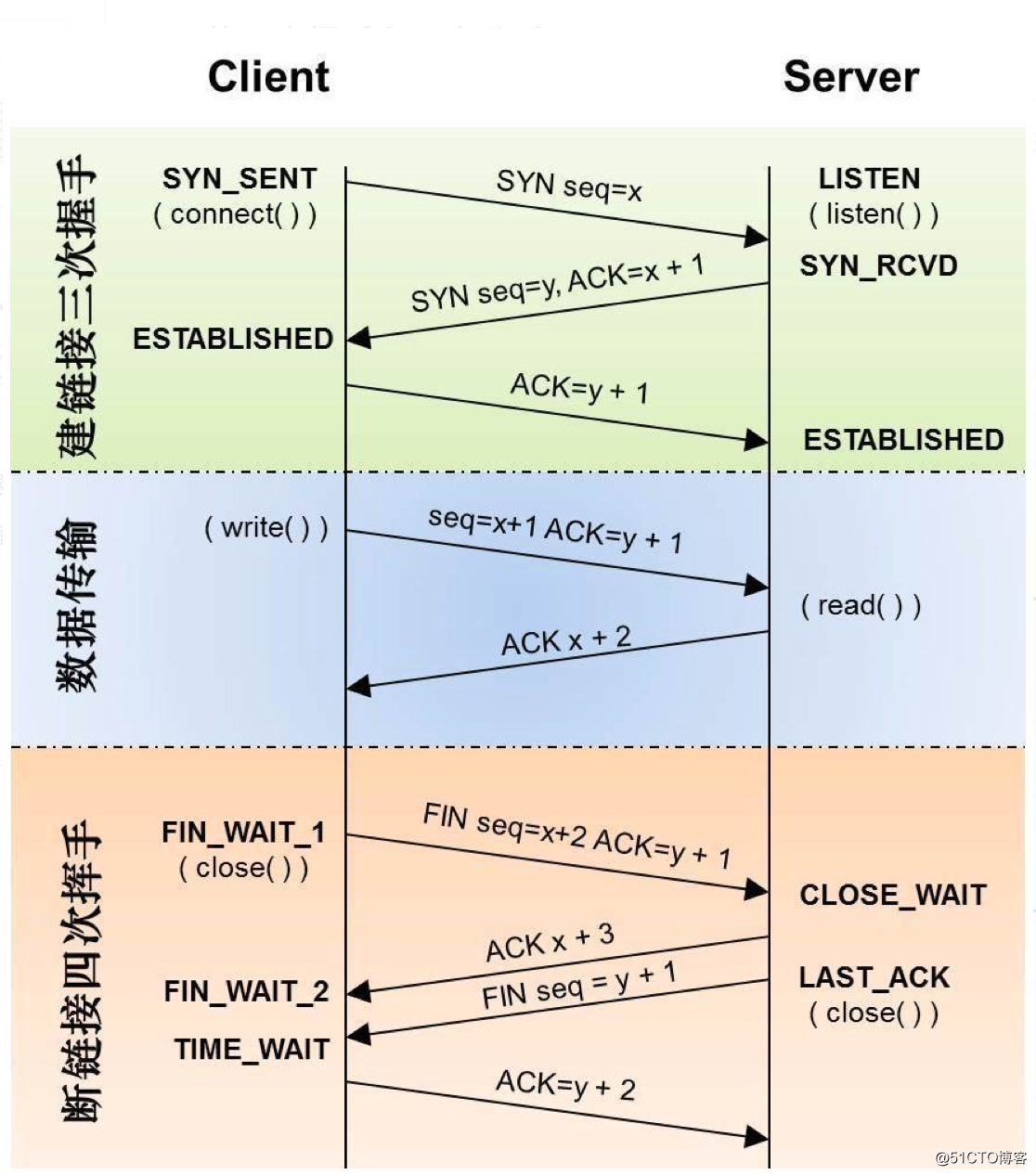
![Linux 下的 TCP参数优化(详解)]()
上图详细描述了TCP的三次握手和四次挥手
这图画的不错吧,,,所以不是我画的,下面的相关参数陈述和优化各位可以参照这个图,人家画的很不错我自己就不献丑了,,绝对不是懒得关系
下述是具体的TCP参数的优化方案
请根据实际情况进行优化!!!
#表示socket监听的backlog(当一个请求(request)尚未被处理或建立时,进入backlog)上限
#限制了接收新 TCP 连接侦听队列的大小。对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了。大多数环境这个值建议增加到 1024 或者更多。 服务进程会自己限制侦听队列的大小(例如 sendmail(8) 或者 Apache),常常在它们的配置文件中有设置队列大小的选项。大的侦听队列对防止拒绝服务 DoS ***也会有所帮助。
net.core.somaxconn = 262144
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
net.ipv4.tcp_tw_reuse = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
net.ipv4.tcp_tw_recycle = 0
#keepalive的保持时间
net.ipv4.tcp_keepalive_time = 900
#表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间(可改为30,一般来说FIN-WAIT-2的连接也极少)
net.ipv4.tcp_fin_timeout = 15
#用于向外连接的端口范围
net.ipv4.ip_local_port_range = 10000 65500
#预留端口避免占用,不同的端口可以逗号隔开
net.ipv4.ip_local_reserved_ports = 50010,10050,32275
#表示那些尚未收到客户端确认信息的连接(SYN消息)队列的长度,默认为1024,加大队列长度为819200,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_syn_backlog = 819200
#TIME_WAIT 状态数量
#表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印告警信息。默认为180000,更改为8192000.对于Apache,Nginx等服务器,上几行参数可以很好的减少TIME_WAIT套接字数量,但是对于Squid,效果不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死
net.ipv4.tcp_max_tw_buckets = 8192000
#该参数用于设定系统中最多允许存在多少tcp套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,没有与用户文件句柄关联的tcp套接字符将立即被复位,同时给出警告信息。这个限制只是为了防止简单的DoS工具。一般在系统内存比较充足的情况下,可以增大这个参数的赋值:
net.ipv4.tcp_max_orphans = 3276800
#CONNTRACK_MAX 允许的最大跟踪连接条目,是在内核内存中netfilter可以同时处理的“任务”(连接跟踪条目)
net.netfilter.nf_conntrack_max = 250000
#tcp_synack_retries 显示或设定 Linux 核心在回应 SYN 要求时会尝试多少次重新发送初始 SYN,ACK 封包后才决定放弃。这是所谓的三段交握 (threeway handshake) 的第二个步骤。即是说系统会尝试多少次去建立由远端启始的 TCP 连线。tcp_synack_retries 的值必须为正整数,并不能超过 255。因为每一次重新发送封包都会耗费约 30 至 40 秒去等待才决定尝试下一次重新发送或决定放弃。tcp_synack_retries 的缺省值为 5,即每一个连线要在约 180 秒 (3 分钟) 后才确定逾时.
net.ipv4.tcp_synack_retries = 2
#对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃。不应该大于255,默认值是5,对应于180秒左右时间。(对于大负载而物理通信良好的网络而言,这个值偏高,可修改为2.这个值仅仅是针对对外的连接,对进来的连接,是由tcp_retries1 决定的)
net.ipv4.tcp_syn_retries = 2
#四种TCP状态的超时时间
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 30
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 30
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 15
net.netfilter.nf_conntrack_tcp_timeout_established = 86400
#当探测没有确认时,重新发送探测的频度。缺省是75秒。
net.ipv4.tcp_keepalive_intvl = 15
#在认定连接失效之前,发送多少个TCP的keepalive探测包。缺省值是9。这个值乘以tcp_keepalive_intvl之后决定了,一个连接发送了keepalive之后可以有多少时间没有回应
net.ipv4.tcp_keepalive_probes = 5
#本端试图关闭TCP连接之前重试多少次。缺省值是7,相当于50秒~16分钟(取决于RTO)。如果你的机器是一个重载的WEB服务器,你应该考虑减低这个值,因为这样的套接字会消耗很多重要的资源。参见tcp_max_orphans.
net.ipv4.tcp_orphan_retries = 0
#支持更大的TCP窗口. 如果TCP窗口最大超过65535(64K), 必须设置该数值为1
net.ipv4.tcp_window_scaling = 1
#当 tcp 建立连接的 3 路握手完成后,将连接置入 ESTABLISHED 状态并交付给应用程序的 backlog 队列时,会检查 backlog 队列是否已满。若已满,通常行为是将连接还原至 SYN_ACK 状态,以造成 3 路握手最后的 ACK 包意外丢失假象 —— 这样在客户端等待超时后可重发 ACK —— 以再次尝试进入 ESTABLISHED 状态 —— 作为一种修复/重试机制。如果启用 tcp_abort_on_overflow 则在检查到 backlog 队列已满时,直接发 RST 包给客户端终止此连接 —— 此时客户端程序会收到 104 Connection reset by peer 错误。
net.ipv4.tcp_abort_on_overflow = 1
#管理TCP的选择性应答,允许接收端向发送端传递关于字节流中丢失的序列号,减少了
段丢失时需要重传的段数目,当段丢失频繁时,sack是很有益的。
net.ipv4.tcp_sack = 1
#关闭tcp的连接传输的慢启动,即先休止一段时间,再初始化拥塞窗口。
net.ipv4.tcp_slow_start_after_idle = 0
#每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
net.core.netdev_max_backlog = 300000
#内核分配给TCP连接的内存,单位是Page,1 Page = 4096 Bytes,可用命令查看:
#getconf PAGESIZE
#第一个数字表示,当 tcp 使用的 page 少于 1048576 时,kernel 不对其进行任何的干预
#第二个数字表示,当 tcp 使用了超过 1310720 的 pages 时,kernel 会进入 “memory pressure” 压力模式
#第三个数字表示,当 tcp 使用的 pages 超过 1572864 时(相当于1.6GB内存),就会报:Out of socket memory
net.ipv4.tcp_mem = 1048576 1310720 1572864
#为每个TCP连接分配的读、写缓冲区内存大小,单位是Byte
#第一个数字表示,为TCP连接分配的最小内存
#第二个数字表示,为TCP连接分配的缺省内存
#第三个数字表示,为TCP连接分配的最大内存
#一般按照缺省值分配,下面的例子就是读写均为8KB,共16KB
#1572864*16kb=25165824kb 相当于26G内存
net.ipv4.tcp_rmem = 4096 8192 16384
#默认的TCP数据接收窗口大小(字节)。
net.core.rmem_default = 1048576
#最大的TCP数据接收窗口(字节)。
net.core.rmem_max = 15728640
#为自动调优定义每个 socket 使用的内存。
#第一个值是为 socket 的发送缓冲区分配的最少字节数。
#第二个值是默认值(该值会覆盖 wmem_default),缓冲区在系统负载不重的情况下可以增长到这个值。
#第三个值是发送缓冲区空间的最大字节数(该值会覆盖 wmem_max)。
net.ipv4.tcp_wmem = 256000 768000 4194304
#各种类型的socket默认读写缓冲器大小
net.core.wmem_default = 1048576
#各种类型的socket默认读写缓冲器最大值
net.core.wmem_max = 5242880
#panic error中自动重启,等待timeout为20秒
kernel.panic = 20
#表示系统级别的能够打开的文件句柄的数量。是对整个系统的限制,并不是针对用户的。
fs.file-max = 6553560
上述很多参数值得修改,并非是绝对要这样,各位还是要根据实际需求进行参照
思量
那这些参数如何优化呢?我怎么知道如何修改比较合理呢
我的建议是,基础优化之后,进行监控,查看tcp的资源消耗和具体卡在哪里
下面是一些Linux系统下面TCP监控的大概获取方式,仅供参考
查看当前的连接数:
代码如下:
grep ip_conntrack /proc/slabinfo
ip_conntrack 38358 64324 304 13 1 : tunables 54 27 8 : slabdata 4948 4948 216
获取TCP各个握手挥手的实际当前数值
代码如下:
# netstat -an | awk '/^tcp/ {++state[$6]} END {for (key in state) print key,"\t",state[key]}'
TIME_WAIT 1832
CLOSE_WAIT 360
FIN_WAIT2 12
ESTABLISHED 3588
SYN_RECV 148
CLOSING 7
LAST_ACK 19
LISTEN 59
查出目前 ip_conntrack 的排名:
代码如下:
$ cat /proc/net/nf_conntrack | cut -d ' ' -f 10 | cut -d '=' -f 2 | sort | uniq -c | sort -nr | head -n 10
总结
还是最好根据实际情况进行参数调整,才最科学,不要盲目加大或者一刀切为上策