这是why的第 63 篇原创文章
荒腔走板 大家好,我是 why,欢迎来到我连续周更优质原创文章的第 63 篇。 老规矩,先荒腔走板聊聊其他的。
上面这张图片是我前几天整理相册的时候看到的。拍摄于 2016 年 8 月 20日,北京。
那个时候我刚刚去北京没多久,住在公司的提供的宿舍里面。宿舍位于北京二环内的一个叫做东廊下的胡同里。
位置极佳,条件极差。
我刚刚进入宿舍的时候,房间里面只有一张大床、一个矮矮的电视柜、一个不能摇头的风扇。我的房间也没有空调,到处都是灰蒙蒙的,用卫生间都是去楼下的公共卫生间。
有一次北京下暴雨,我才发现窗户那边有一个缺口,雨下的太大,可以顺着那个缺口流下来,把我的鞋都打湿了。
宿舍里面没有冰箱,所以节假日我在宿舍只煮面条或者用电饭煲做干饭,然后就着各种酱吃。记得有一次周五领导请我们吃饭,最后菜点多了,有几个羊蹄动都没动,领导就叫我打包带回家。我带回去,挂在墙上挂钩,准备第二天中午吃。第二天一闻,坏了,也就没有吃。
宿舍里面也没有洗衣机,所以我在超市买了一个巨大的盆子,每周末的时候我会拿出一个下午的时间,边看电视,边手搓衣服,四季如此。
刚刚去北京的前一年,过的真的还是很艰难的。但是宿舍的好处是离公司近,所以我基本上也不怎么在宿舍呆着,工作日在公司学习到很晚,周末也去公司学习。
艰苦的环境更能激发人的斗志。
但是我还是简单的装饰了一下简陋的出租屋,买了贴画和绿植,因为我坚信房子是租来的,但是生活是自己的。
而且每周洗完衣服后我会用洗衣服的水再拖一下地。我的房间很小,摆上一张 1.5 米的大床之后基本上就没有什么空间了,所以我用不上拖把,一张帕子就够了。
我可以蹲在地上,把房间里面的每一块地砖的边边角角都仔仔细细的擦拭一遍,然后跳到床上去,静静的坐着,开始放空自己。
当时并没觉得有什么困难,但是和现在的生活再对比一下,真的是天壤之别。现在回想起,才真真正正的觉得:我曾经也在北京用力的生活过,离开的时候回忆满满,风华正茂。
就像我之前写过的:北漂就像在黑屋子里洗衣服,你不知道洗干净了没有,只能一遍又一遍地去洗。等到离开北京的那一刻,灯光亮了,你发现,如果你认真洗过了,那件衣服光亮如新。让你以后每次穿这件衣服都会想起那段岁月。
所以你呢,有没有在用力的生活?
好了,说回文章。
大佬指点,纠正错误
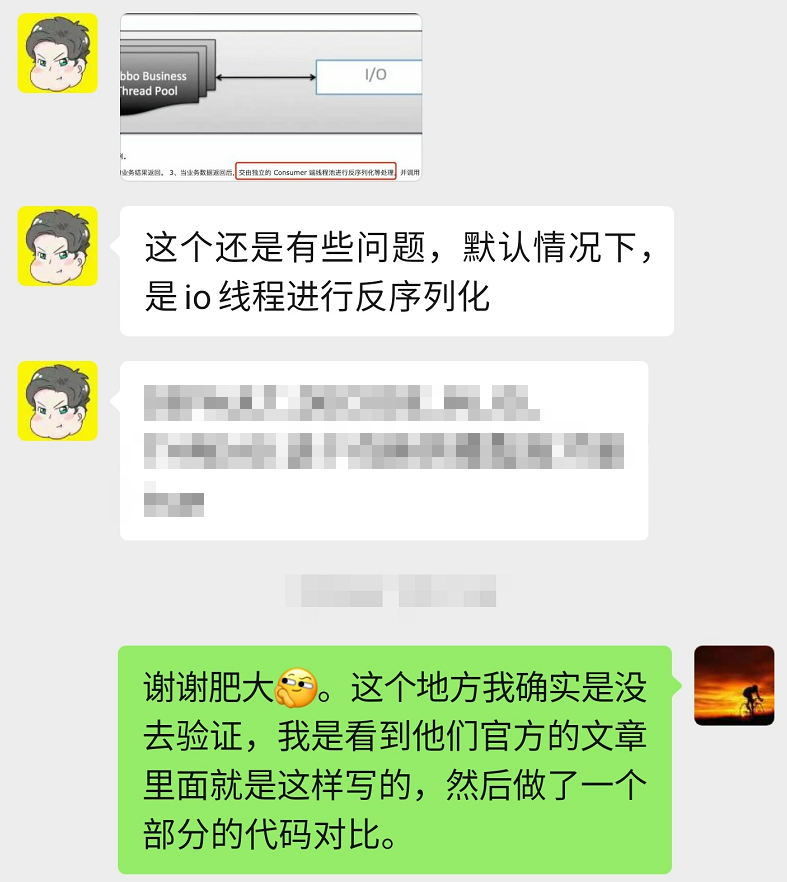
是的,这个大佬就是公众号【肥朝】的号主。
文章是这篇文章《Dubbo 2.7.5在线程模型上的优化》 。
错误具体是指下面红框框起来的这句话的描述:
而这段话,我是引用的官方内容。而现在这部分内容已经一字不差的加入到官网中了:
http://dubbo.apache.org/zh-cn/docs/user/demos/consumer-threadpool.html
经过验证后发现确实官网上的描述是有问题的。
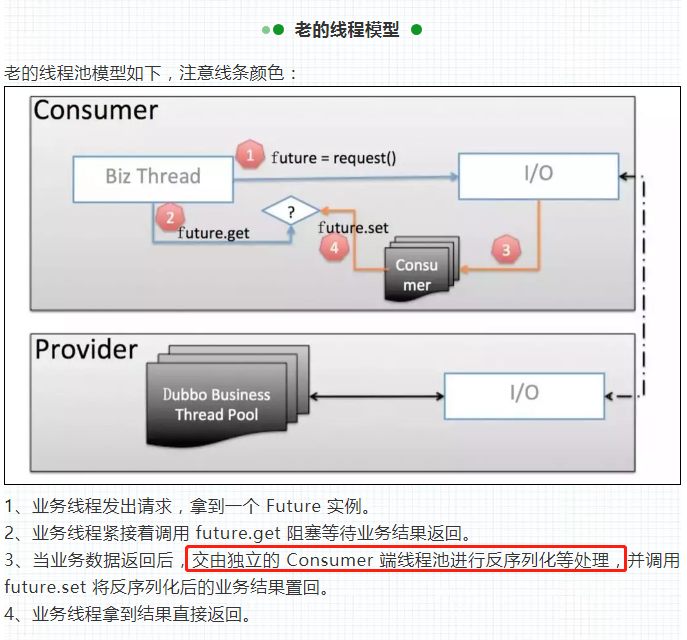
先说结论:2.7.5 版本之前,业务数据返回后,默认在 IO 线程里面进行反序列化的操作。而2.7.5 版本之后,默认是延迟到客户端线程池里面进行反序列化的操作。
所以,对于官网中,上面红框框起来这个地方的描述“交由独立的 Consumer 端线程池进行反序列化处理”是有问题 。
正 确的说法应该是: 在老的(2.7.5 版本之前)线程池模型中,当业务数据返回后,默认在 IO 线程上进行反序列化操作,如果配置了 decode.in.io 参数为 false(默认为 true),则延迟到独立的客户端线程池进行反序列化操作。
所以本文就主要分享两个问题:
以 Dubbo 2.7.5 版本(
因为线程池模型就是在这个版本变更的 )为分界线,对比不同版本之间,业务数据返回后,反序列化的操作到底是在独立的 Consumer 端线程池里面进行的还是在 IO 线程里面进行的?
需要说明的是由于本文需要做不同版本之间的对比,所以会涉及到两个 Dubbo 版本,分别是 2.7.4.1 和 2.7.5 。写的时候我都会标注清楚,大家看的时候和自己动手的时候需要注意一下。
另外再提前说明一下,文章有点长:如果你自己看 Dubbo 源码,可以先看整体,忽略细节。把整体摸个遍了之后,再去扣细节,精进源码。 本文就属于扣细节,看的似懂非懂没关系,先一键三连,然后收藏起来,你自己学的时候总是会学到这个地方来的,而且本文也不是一个非常难得技术点。
如果你没有学到,只能说明你潜入的深度还是差了一点,也许你差一点就走到这个地方了,然后你想:算了吧,差不多得了。
但是你要知道, 越往下, 越难懂。而越难懂的,越值钱。
你想想,正在抗住流量的东西,是你写的那几行代码吗?不是的,是你系统里面用到的 Nginx、MQ、Redis、Dubbo、SpringCloud 等等这些中间件。而这些中间件里面,抗住流量的,除了它们的集群功能、容 错功能、 限流熔断、调用链路的优化等待这些手段之外,还有底层的网络、IO、内存、数据结构、调度算法等待这些东西。
这是值钱的。
可惜这些值钱的,不好讲清楚,要说清楚就是长篇大论。所以我常常说的劝退长文都是说说而已的,你这么爱学习,我怎么会劝退你呢,鼓励你都来不及呢,你说是吧?
再说了,我写的长文,也并没有涉及到这么底层的东西。只是我没有想过敷衍这事,我想把它做好了,尽量把它写清楚了,中间再夹杂着几句“骚 话 ”,所以写着写着就长了。
总之,你要坚信三点:
一:我没有看懂,一定是因为这个博主写的太烂。
二:我没有看懂 ,理论上大多数人也应该看不懂。
三:我没有看懂 ,那我自己研究一下得让自己懂。
程序员就应该这样,明明天天写着这么 普通的 crud,但是聊起技术来却是那么的迷之自信。
Dubbo协议的设计与解析 为什么要先聊一下 Dubbo 的协议呢?
因为反序列化的时候涉及到一些响应头(head)和响应体(body)解析的相关内容,是需要先进行一下铺垫的。
首先去官网上撸个图片过来:
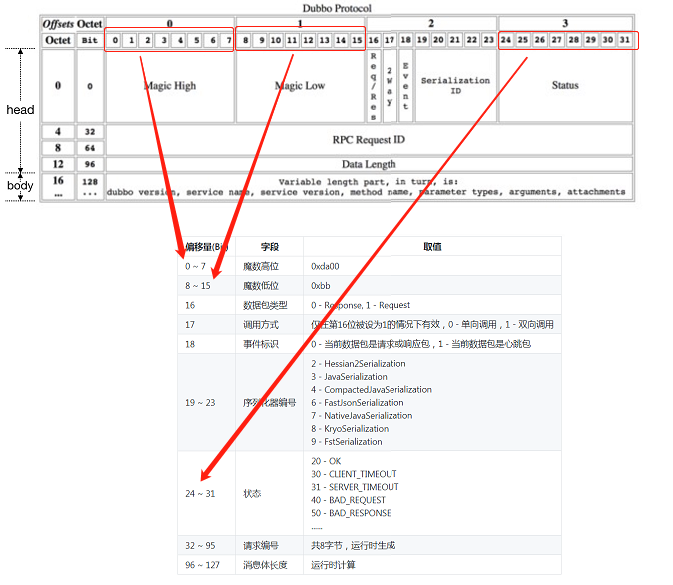
可以看到 Dubbo 数据包分为消息头(head)和消息体(body)。
消息头用于存储一些元信息,包括:魔数、数据包类型、调用方式、事件标识、序列化器编号、状态、请求编号、消息体长度。
消息体中用于存储具体的调用消息,包含七部分内容:
客服端发起请求的时候严格按照上面的顺序写入消息,服务端按照同样的顺序读取消息,这样就能解析出消息体里面的内容。
对于协议字段的解析,官网上也是有详细说明的。撸过来:
再具体的解释一下,首先这图得和协议图一起看,我怕你不会,再给你搞一张示意图:
上面的截图只是演示了三个对应关系,但是这两张图就是这样看的。
我主要再解释一下里面的某些字段。
第一个:魔数
作为 Java 开发者,提到魔数,你第一个想到了什么?
0xCAFEBABY,对吧。
每个 class 文件的头 4 个字节就是魔数,它的唯一作用就是确定这个文件是否为一个能被 JVM 接受的 class 文件。
在 Dubbo 中这个魔数是用来干什么的呢?
也许你不太清楚,但是我希望我一说你就能恍然大悟。因为你不悟,也不是本文要讲的东西,我也不好给你解释清楚。
它是用来解决网络粘包/解包问题的。恍然大悟有没有?
没有?
对不起,本文不扩展相关内容。大学上《计算机网络》课程的时候逃课处对象去了吧?
在 Dubbo 协议中,它的魔数:0xdabb。你可以简单的把它理解为一个分隔符,用来解决粘包问题的。
第二个再说说:调用方式
首先这个字段仅在第 16 位设置为 1 的情况下有效。
从表里面我们可以知道,第 16 位为 1 就是指:request 请求。
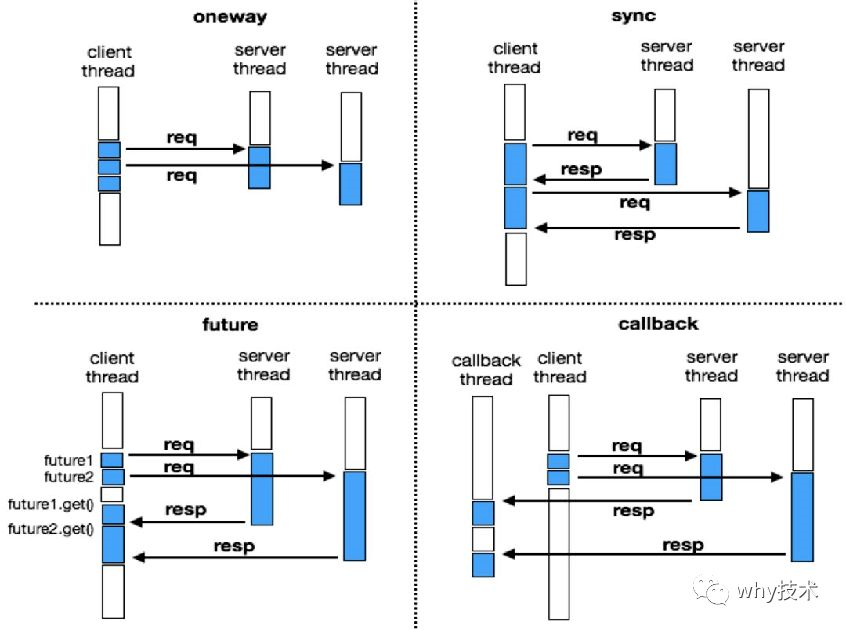
在 rpc 中既然是 request ,那么就分为两种调用方式:有去无回(单向)、有来有回(双向)。
熟悉吗?
不熟悉?呸,你个假粉丝,这张图在我的文章中至少出现过两次:
oneway 就是单向,其他的调用类型都是有返回的。
所以调用分为两种类型,因此需要一个 bit 来存放调用方式。
第三个说说事件标识字段 :
事件标识没啥说的,取值里面的描述也说的很清楚了。只是说明一下其中的 1 (心跳包),不在本次文章的分享范围内。
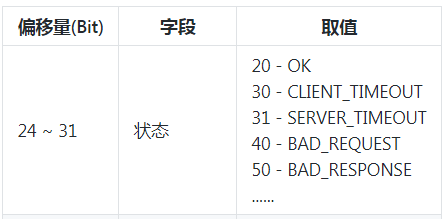
第四个说说状态字段 :
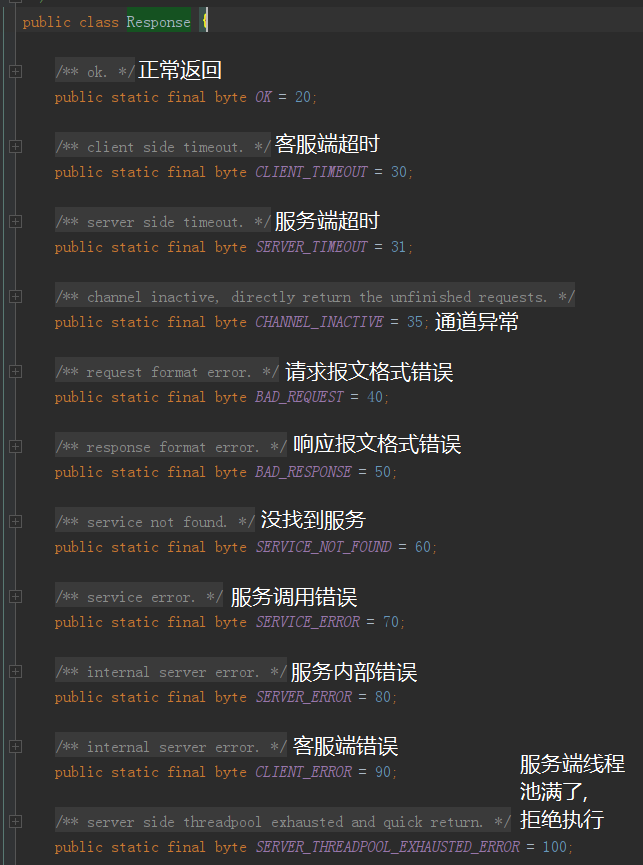
状态里面有个省略号,说明没有枚举完。但是代码里面肯定是齐的,这些状态对应的代码在这个类里面,一共 11 个,给大家补充完整:org.apache.dubbo.remoting.exchange.Response
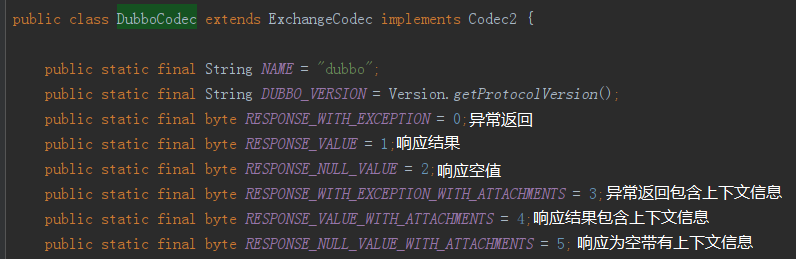
另外,再说一下返回的类型,讲到后面的时候需要知道这个点。主要依据这个类里面定义的字段:org.apache.dubbo.rpc.protocol.dubbo.DubboCodec
对应的代码逻辑如下:org.apache.dubbo.rpc.protocol.dubbo.DubboCodec#encodeResponseData(org.apache.dubbo.remoting.Channel, org.apache.dubbo.common.serialize.ObjectOutput, java.lang.Object, java.lang.String)
这个方法从名称也知道,是对响应数据做解码操作的。
标号为①的地方是判断当前版本是否支持上下文信息传递。
标号为②的地方是判断是否是异常返回。
标号为③的地方表明不是异常返回,则判断返回值是否为 null。
标号为④的地方表明是正常返回,根据是否支持上下文信息传递,从而判断是只返回响应结果的还是既有响应结果,也有上下文信息的返回类型。
标号为⑤的地方表明是异常返回,根据是否支持上下文信息传递,从而判断是只返回异常结果的还是既有异常结果,也有上下文信息的返回类型。
好了,写到这里,协议就差不多说完了。其实不难发现这个协议就是一个偏理论的东西,这就是一个大家的约定。
所以我记起之前在一个分享大会上,一位嘉宾说的:
跨语言特性实际是RPC层的支持,本质是协议层面的支持。
我现在对这句话的理解更加深刻了。
跨语言,也就是服务异构的一种。
为什么我用 Java 发送 http 请求的时候可以不用关心对方使用的是什么开发语言?
因为大家都遵守了 http 协议,协议是可以跨语言的。
Dubbo 这种 rpc 调用的框架也一样。我发起远程调用之后,只要你能按照我们约定好的协议进行报文的解析,那你就能正常的处理我发过来的请求,我不管你的开发语言是什么。
反序列化操作到底在哪进行? 业务数据返回后,反序列化的操作到底是在哪个线程里面进行的?
是在 IO 线程里面直接解析,还是被派发到客户端线程池里面进行解析?
这个问题我们先试着在官网的线程模型介绍中去寻找答案。http://dubbo.apache.org/zh-cn/docs/user/demos/thread-model.html
在线程模型的描述里面,是这样写的:
如果事件处理的逻辑能迅速完成,并且不会发起新的 IO 请求,比如只是在内存中记个标识,则直接在 IO 线程上处理更快,因为减少了线程池调度 。
但如果事件处理逻辑较慢,或者需要发起新的 IO 请求,比如需要查询数据库,则必须派发到线程池,否则IO 线程阻塞,将导致不能接收其它请求 。
如果用 IO 线程处理事件,又在事件处理过程中发起新的 IO 请求,比如在连接事件中发起登录请求,会报“可能引发死锁”异常,但不会真死锁。
因此,需要通过不同的派发策略和不同的线程池配置的组合来应对不同的场景。
本文不关心线程池配置,我们只看派发策略:
默认的派发策略是 all。
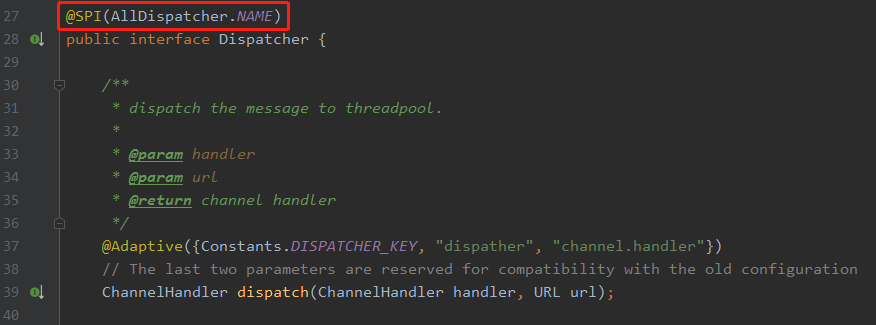
一看到这几个策略,熟悉 Dubbo 的朋友肯定就知道了,按照 Dubbo 的尿性,这必须得是一个 SPI 接口啊。
果不其然,源码里面就是这样的,你说巧不巧:
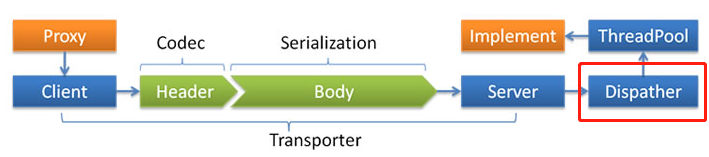
然后官方还给出了一张描述不太清晰的图片:
图片中的 Dispatch 就是派发策略发挥作用的地方。
所以我们能从这部分得出一个结论:在默认的情况下,客户端接收到响应后,由于 Dubbo 使用 all 的派发策略,会把响应请求派发到客户端线程池中去。
那我们可以推导出: 响应的解析一定是在客户端线程池里面进行的吗?
不可以,推不出来的。
只能说响应会进入客户端线程池中去,但是这个响应可能是一个经过解析后的响应,也可能是一个没有经过解析的响应。
所以,这个响应有可能在进入线程池之前就被解析过了。被谁解析?
IO 线程。
如果 IO 线程没有解析,那就在客户端线程里面去解析。
根据上面这段话。我们能提炼出一个关键语句,或者说是需求:我们现在要实现响应报文可以在不同的地方进行解析的功能,请问你怎么做?
你用脚指头想也知道了。肯定是有一个 if 判断的,判断到底在哪(IO线程/客户端线程池)进行响应解析。而这个 if 判断的判断条件,按照 Dubbo 的尿性,肯定是可以配置的。
所以我们找到这个地方,问题就了然于心了。
我们去哪里找答案呢?
这个类里面,这个类是一个请求/响应解码的非常核心的类:org.apache.dubbo.rpc.protocol.dubbo.DubboCodec
这个类的主要干了两件事,一个是对响应报文进行解码,一个是对请求报文进行解码。
接下来我们怎么搞?强撸源码吗?不可能的。直接撸肯定费劲。
还是要搞个 Demo 跑起来,然后 Debug。
我这里的 Demo 非常简单,服务端接口实现类如下:
消费者在测试类中进行消费:
然后 Debug 起来,注意,下面演示的代码没有特别说明的地方,都是 2.7.5 版本。
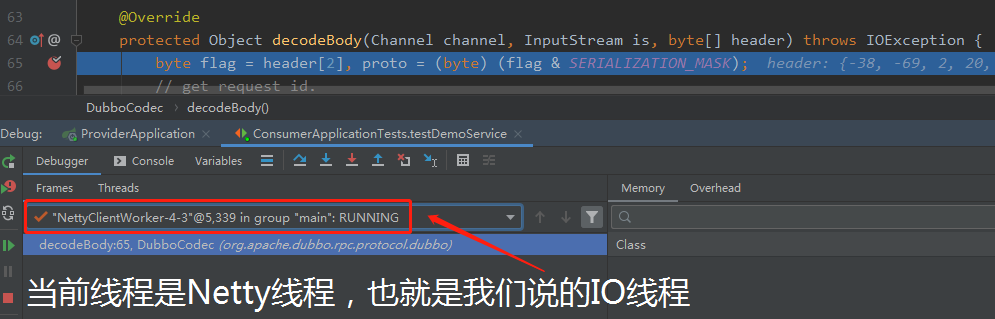
运行起来后先不看别的,看看当前卡在这个地方,被 Debug 的线程是什么线程:
到这里你先冷静一下,你想一下这个问题:
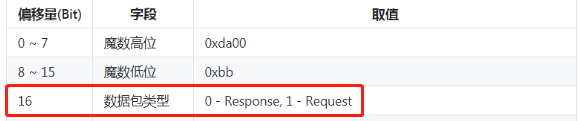
在这个方法里面可以对响应和请求进行解析。那它怎么知道当前到底是响应还是请求报文呢?
答案就在前面说的 Dubbo 协议里面:
呼应上了没有?header 里面第 16 bit 如果是 0 代表响应,如果是 1 代表请求。
你说巧不巧,上面这个方法的入参里面就有一个 header 数组。
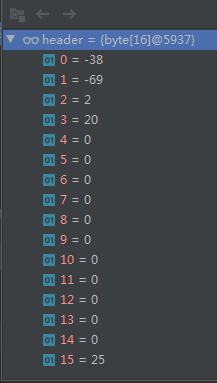
让我们看看他里面装的是什么东西:
长度是 16,和 header 的长度吻合,但是里面装的玩意还是没看出来。
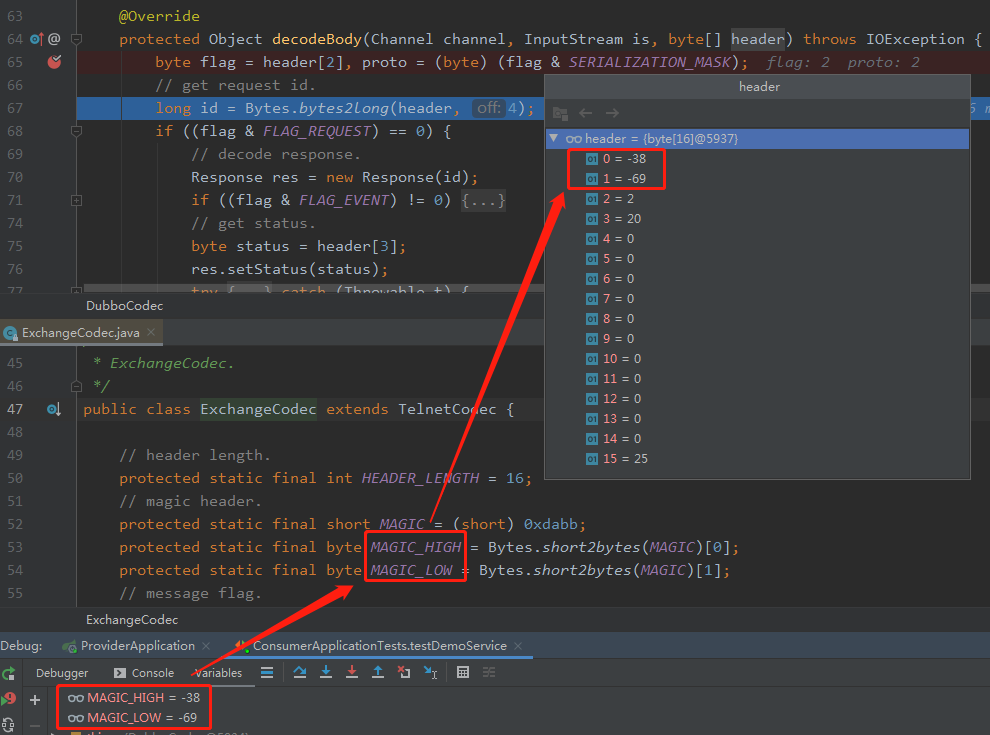
但是这样一看,看前两个字节,你就明白了:
嘿,你说巧了吗,这不是巧了吗,这不是。
魔数也对上了。说明这是一个 Dubbo 的 header。
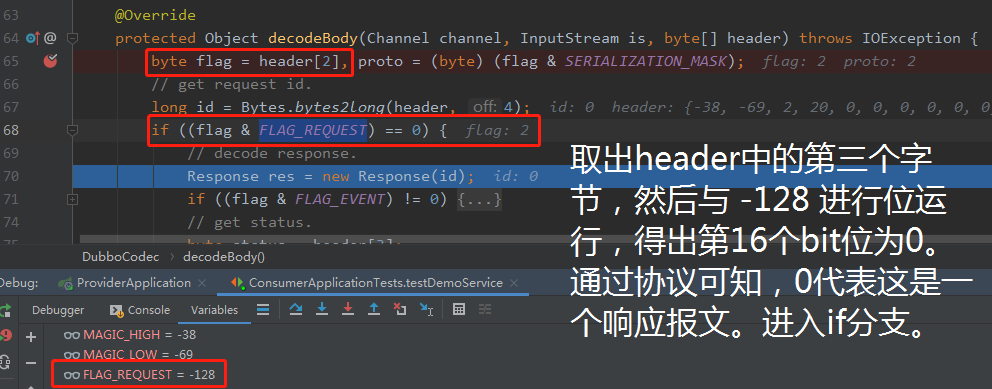
然后取出第 3 字节,进行位运算,判断这是什么报文:
前面,我们解决了怎么知道当前到底是响应还是请求报文这个问题。
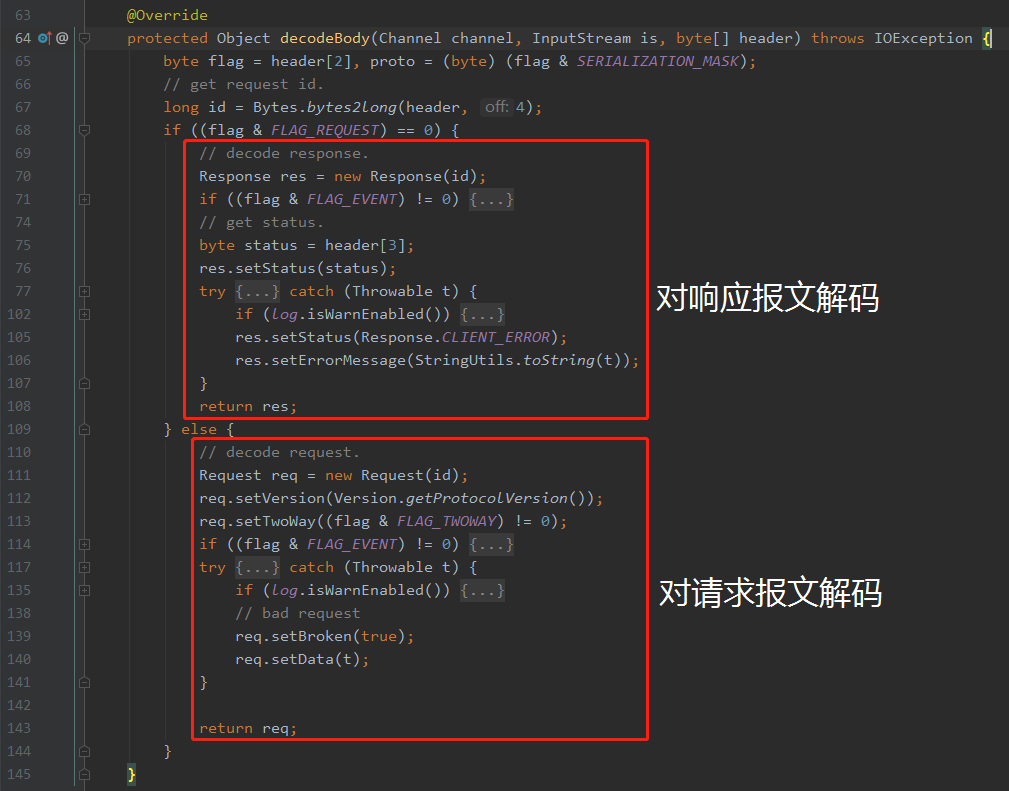
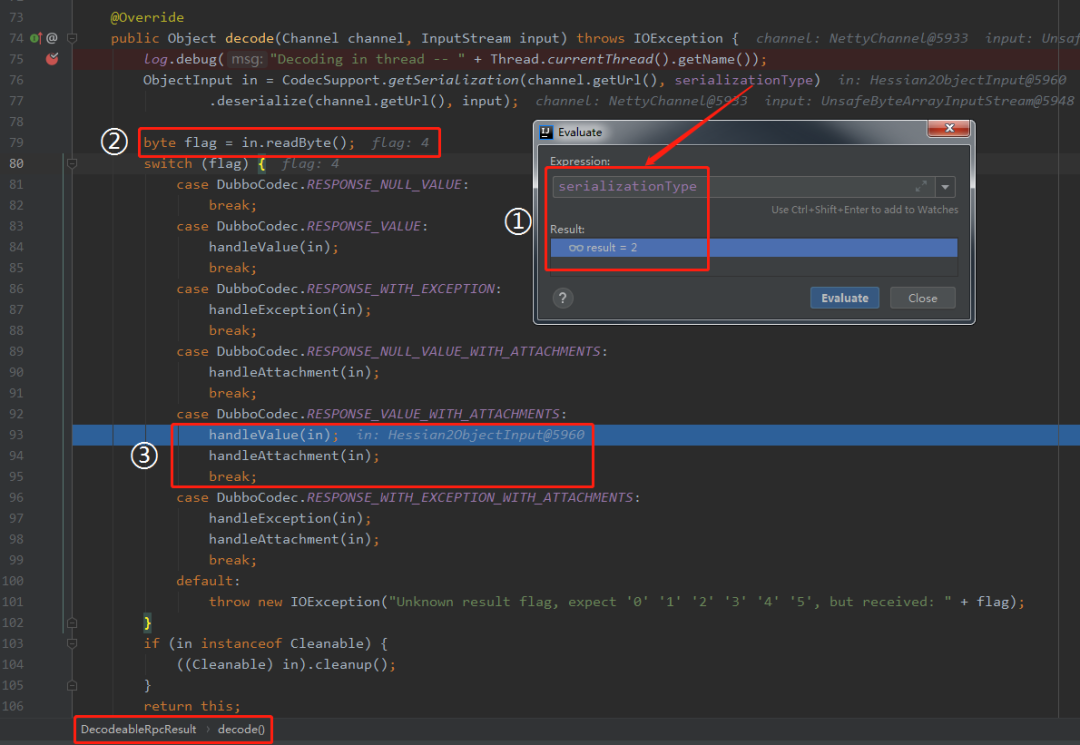
接下来,进入分支里面就重点关注对响应报文的解析了:
首先,上面标记为①的地方是判断当前数据包是不是一个心跳包,经过 Debug 我们可以知道这不是一个心跳包:
然后标记为②的地方获取 header 中的第 4 个字节,第 4 个字节代表的是状态位:
从 Debug 的截图里面我们可以看出,当前的状态为 20,表示正常返回。
标记为③的地方,是对心跳包的解析,我们这里不关心。
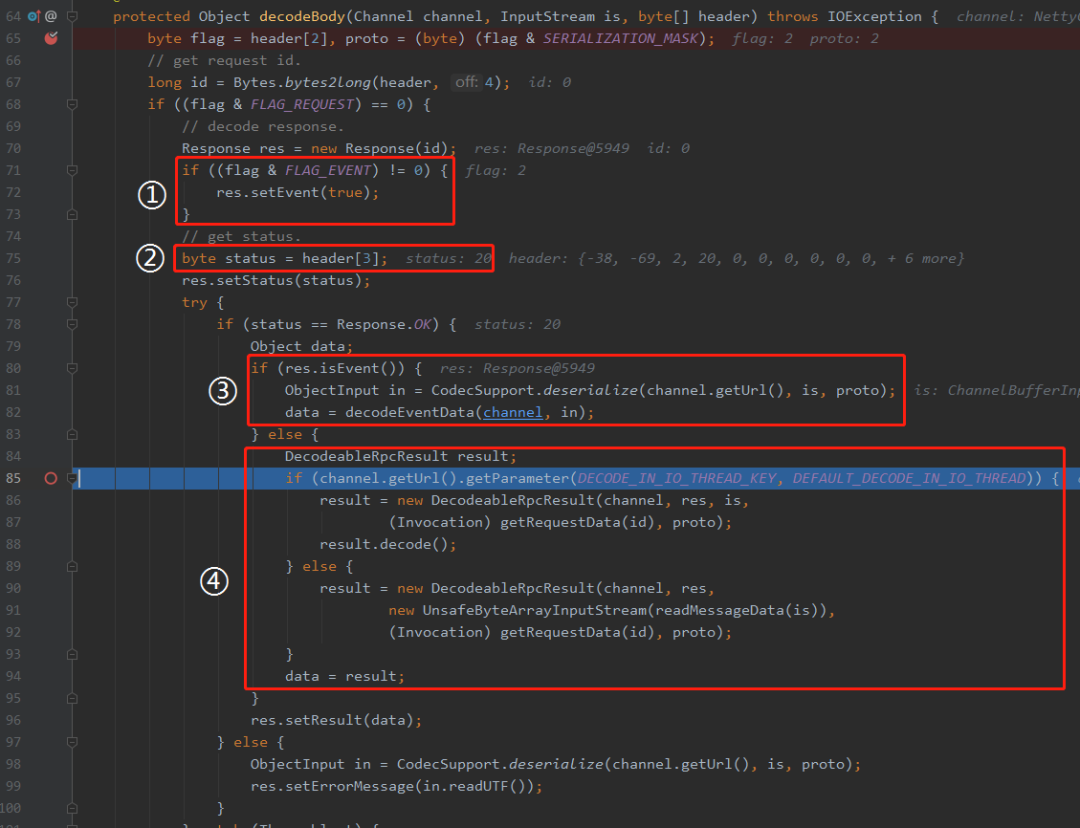
标记为④的地方,是我们需要重点关注的地方,也是我们一直在寻找的代码。
这个地方就很关键了,大家集中注意力了。
首先,下面代码的截图是 2.7.5 版本的:
这里的 if 分支和分支里面的判断条件,就是我们前面说的:
你用脚指头想也知道了。肯定是有一个 if 判断的,判断到底在哪(IO线程/客户端线程池)进行响应解析。而这个分支判断的判断条件,按照 Dubbo 的尿性,肯定是可以配置的。
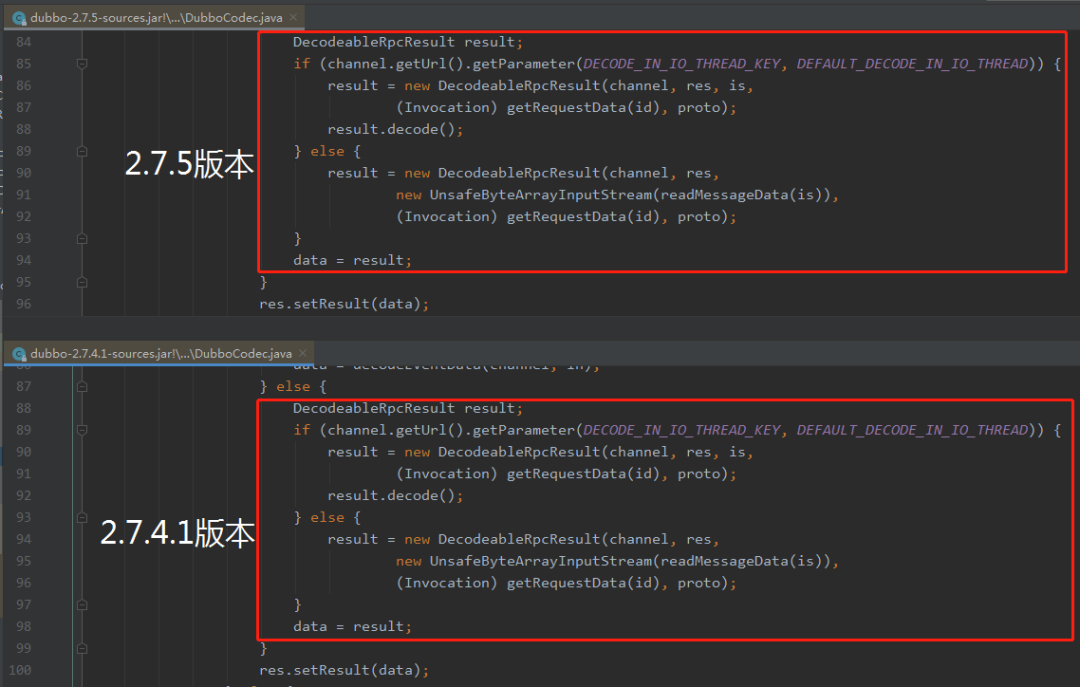
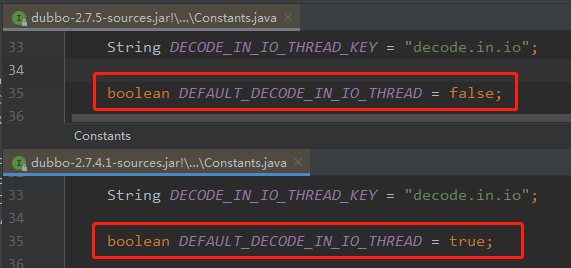
下面这张图片对 2.7.4.1 和 2.7.5 版本这个地方的代码进行一个对比:
你仔细看着两个版本之间的代码,发现一模一样,也没有差异啊。
这就把我干懵逼了:咋回事?说好的差异呢?
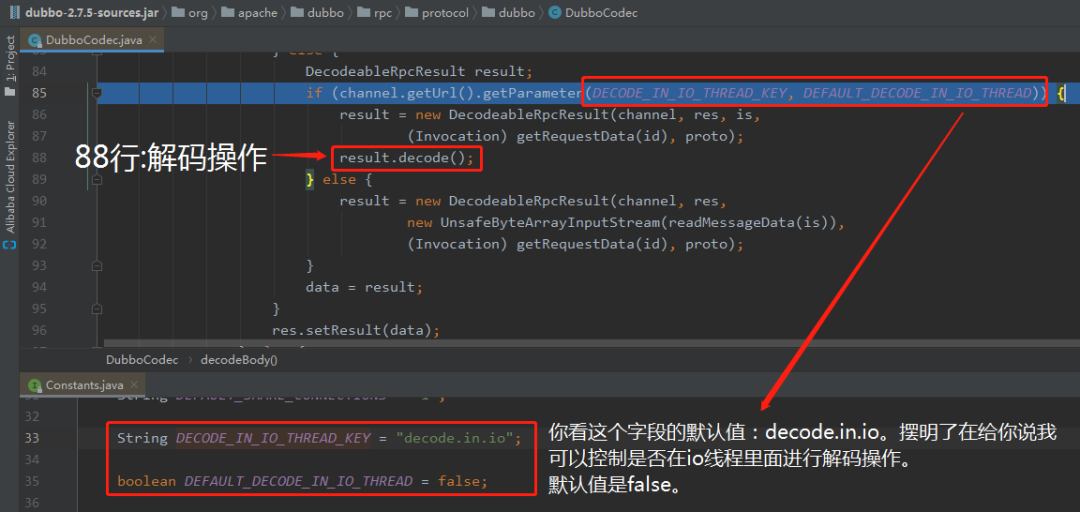
别忘了,上面的代码里面是有一个变量的:
差异就差异在这个地方。
2.7.5 版本之后,这个参数的默认值从 true 变为了 false。
换句话说就是:2.7.5 版本之前,业务数据返回后,默认在 IO 线程里面进行反序列化的操作。而2.7.5 版本之后,默认是延迟到客户端线程池里面进行反序列化的操作。
同时这个参数,不管在哪个版本里面,都是可以配置。 虽然基本上也没有人更改过这个配置,配置方法如下:
朋友们,到这里还跟的上不?跟不上你就再捋捋?别硬看,伤身体。
解码操作源码解析 接下来我们再看看解码操作的代码到底是怎么样的。
首先解码操作,解的什么码?
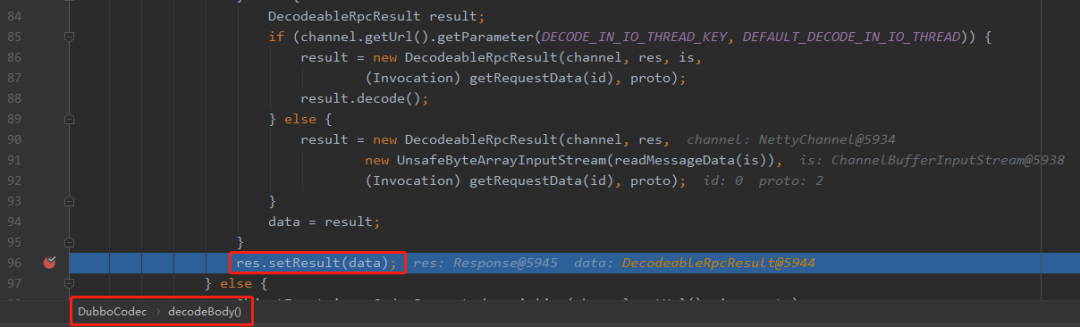
解的是响应报文的响应体,也就是我们的返回内容:org.apache.dubbo.rpc.protocol.dubbo.DecodeableRpcResult#decode(org.apache.dubbo.remoting.Channel, java.io.InputStream)
标号为①的地方代表序列化类型是 2 。
2 是什么?看表:
Hessian2Serialization,就是 Dubbo 默认的序列化器。
标号为②的地方代表本次响应类型为 4。
4 是什么?前面说了,看截图:
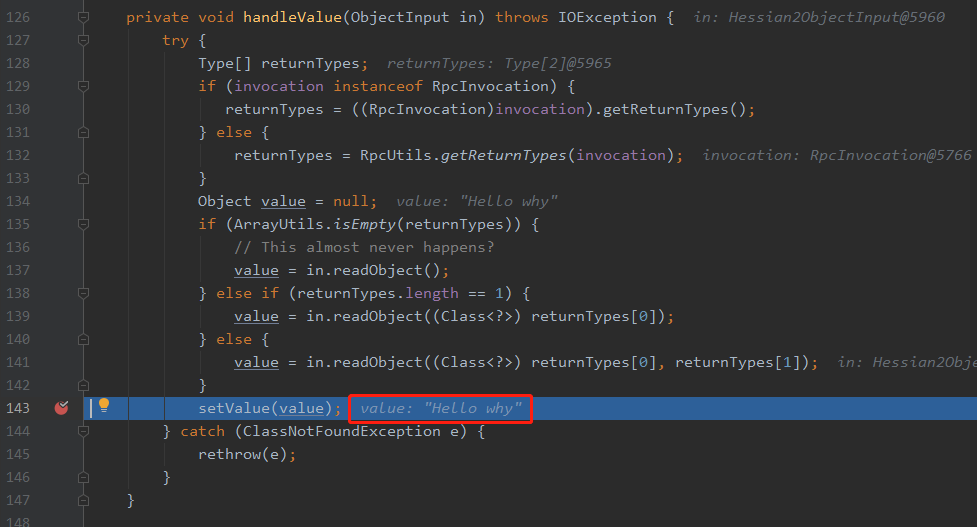
所以,在标号为③的地方即处理了返回值(handleValue)也处理了上下文信息(handleAttachment)。
handleValue 就不细看了,你就关注这个地方解析出来的就是我们的响应内容:
响应内容的解码就是上面说的逻辑。
不管是在 IO 线程里面解码还是在客户端线程池里面解码,都要调用这个方法。只不过是谁先谁后的问题。
那么问题又来了,需求又发生变化了。
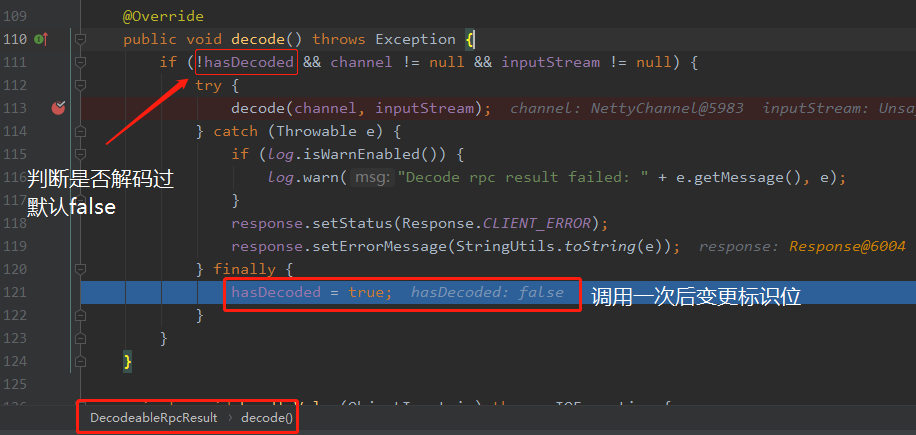
因为 IO 线程和客户端线程池都要调用这个方法进行解码,我们总不能解码两次吧,那怎么保证只解码一次呢?
答案就是设置标识位。
因为我们知道如果是在 IO 线程里面解码,那么该操作调用解码方法后,肯定是先于客户端线程池调用的。
有先后顺序就好办了。我们就可以设置标识位:
当在 IO 线程解析后,会把标识位设置为 true。然后客户端线程池再走到这个逻辑的时候,发现标识位是 true 了,不进行再次操作,问题就这样被解决了。
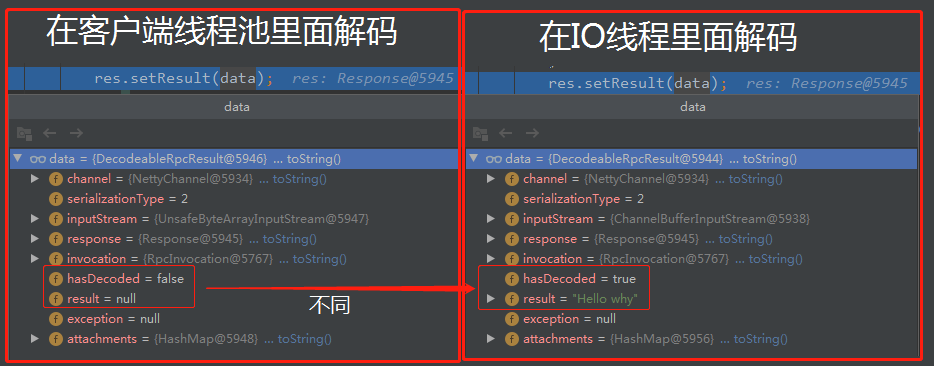
接下来,我给大家对比一下 decodeBody 方法在 IO 线程里面解码和在客户端线程池里面解码时分别返回什么。也就是这行代码返回的时候:
这样一对比就很清晰了:
这样也解释了,为什么说是“延迟”到客户端线程池里面解码。
好了,到这里你有没有发现一个问题。前面解析的这么多源码,然后咔一下,直接我们就看到了最终返回的“Hello why”了。
这个是响应消息体,是 body。
头呢?header 呢?
别急,这不是马上就给你讲一下嘛。
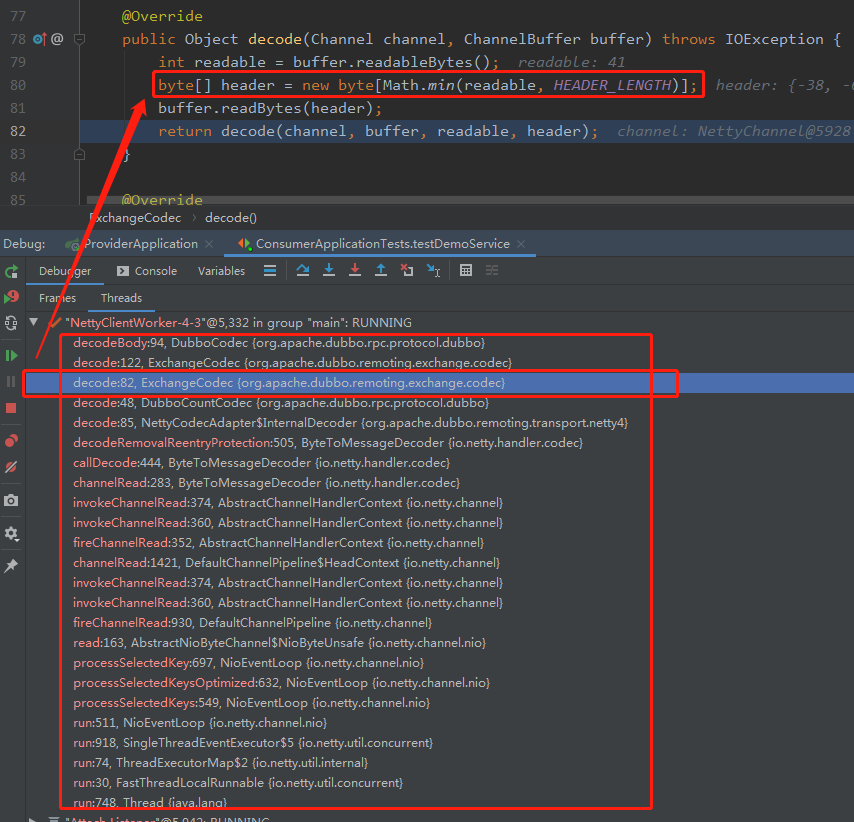
前面讲这个方法的时候说了:header 是作为参数传进来的嘛,那我们还可以去找一下 header 到底是怎么传进来的:
怎么看呢?
顺着调用链往回找就行,一个调试小技巧,送给大家,不客气:
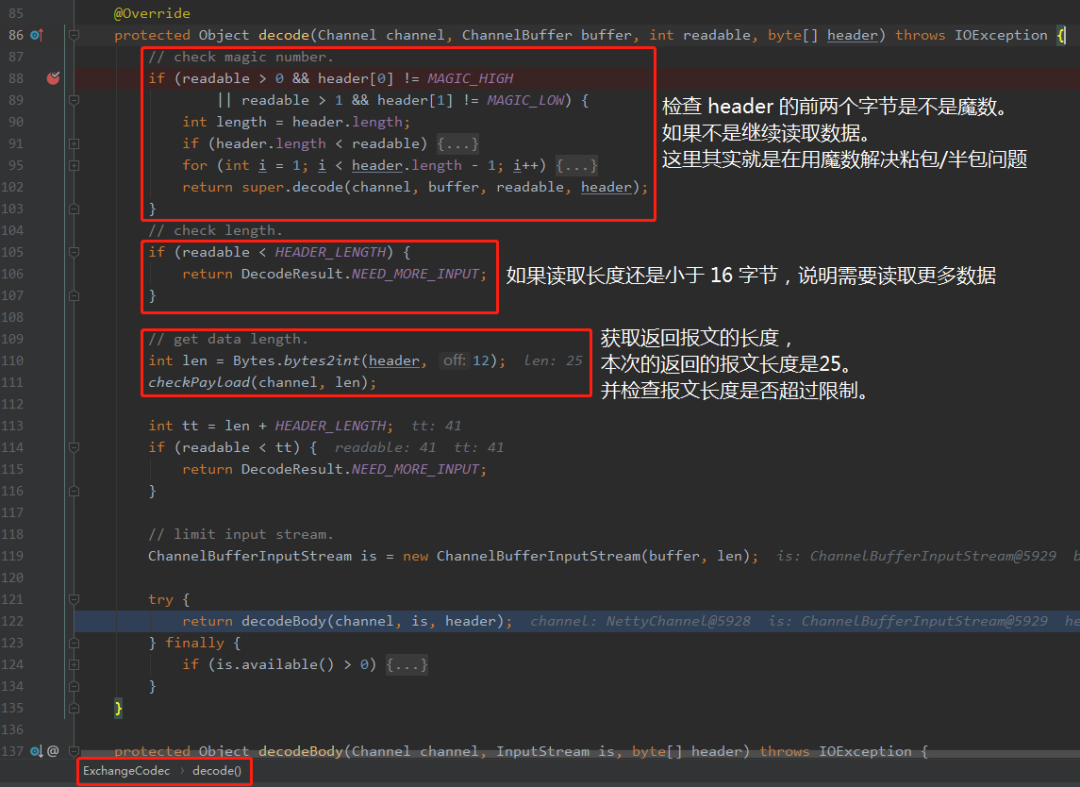
可以看到 header 是从 buffer 里面取出来的,最多读取 HEADER_LENGTH (16) 个字节。
什么?你还问我为什么最多读 16 个字节?
我怀疑前面讲协议的时候你就在走神。别问,问就是协议规定。大家遵守就好了。
再跟着调用链往前一步,你会发现这里主要是在做解码响应头的部分:
上面这个方法里面就是在搞 header 的事情。
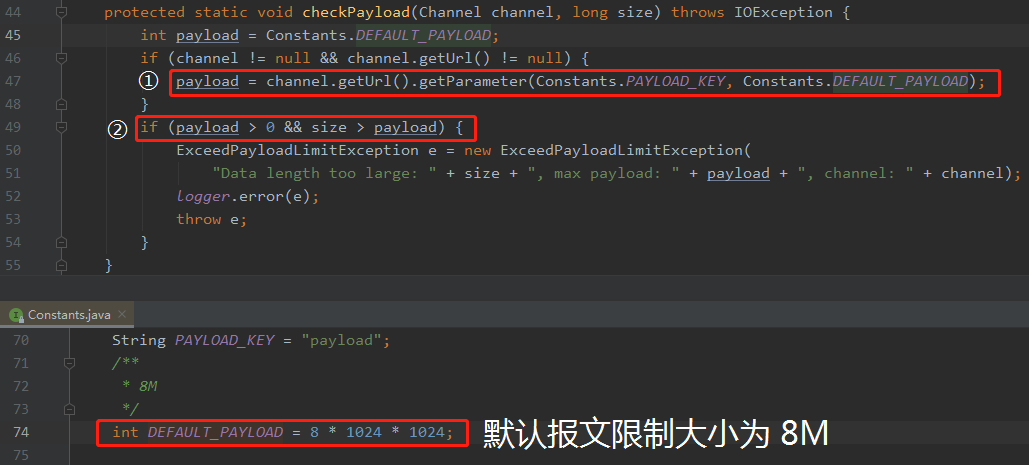
其中有一个检查报文长度的方法:checkPayLoad。
那么问题又来了:请问 Dubbo 默认的报文长度限制是多少呢?
带大家去源码里面找答案:
答案是 8M。
另外,既然是有默认值,那必须是可以配置的。所以上图标号为①的地方是从配置中获取,获取不到,就返回默认值。
稍微有点意思的是标号为②的地方,我第一次看的时候愣是看了一分钟没反应过来。主要是前面的这个 payload > 0,我想着这不是废话嘛,长度不都是大于 0 的。兴奋的我以为发现了一个无用代码呢。
后来才理解到,如果当 payload 设置为负数的时候,就代表不限制报文长度。
可以进行如下配置:
一个基本上用不到的 Dubbo 小知识点,免费赠送给大家。
好了,header 和 body 都齐活了。
到这里,再总结一下:2.7.5 版本之前,业务数据返回后,默认在 IO 线程里面进行反序列化的操作。而2.7.5 版本之后,默认是延迟到客户端线程池里面进行反序列化的操作。
所以,对于官网中,红框框起来这个地方的描述是有问题的:http://dubbo.apache.org/zh-cn/docs/user/demos/consumer-threadpool.html
正确的说法应该是:在老的(2.7.5 版本之前)线程池模型中,当业务数据返回后,默认在 IO 线程上进行反序列化操作,如果配置了 decode.in.io 参数为 false,则延迟到独立的客户端线程池进行反序列化操作。