有人在思否论坛上向我付费提问
当时觉得,这个人问的有问题吧。仔细一看,还是有点东西的
var http = require('http' );function (request, response) {for (var i = 1; i < 5900000000; i++) {'Hello' + num);
使用
nodemon启动服务,用
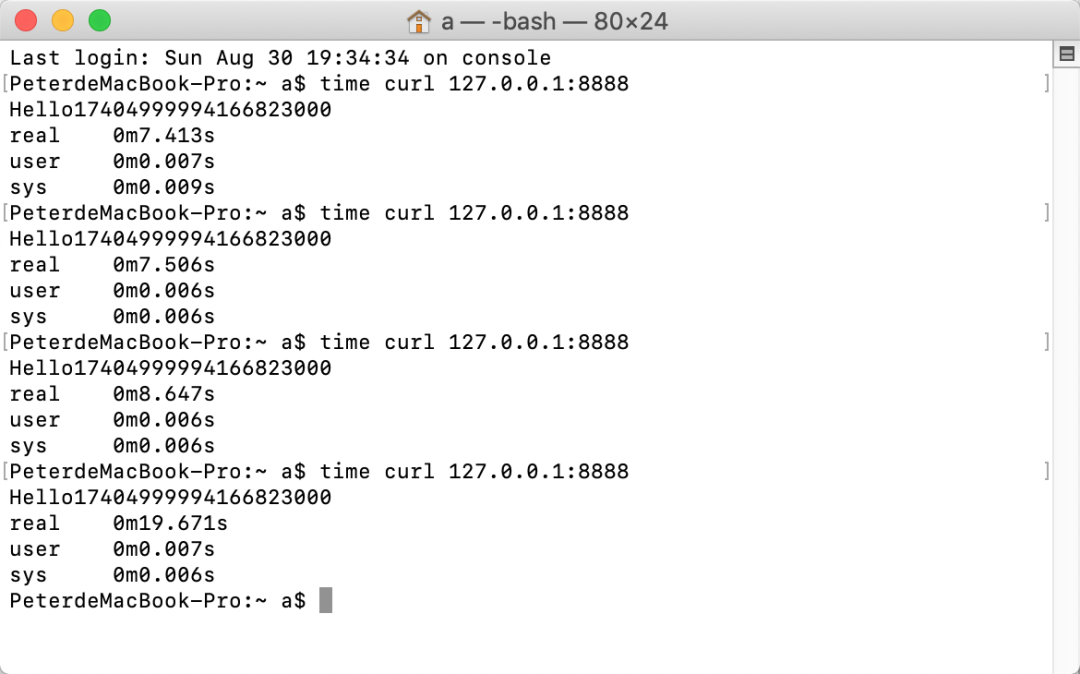
time curl调用这个接口
为什么这个耗时突然变高,由于我是调用的是本机服务,我看
CPU使用当时很高,差不多打到
100%了.但是我后面发现不是这个问题.
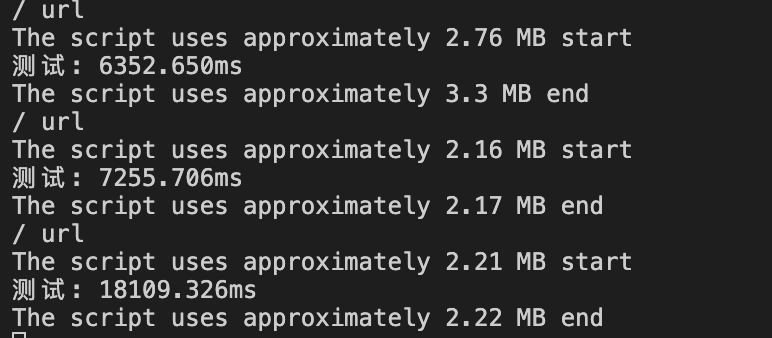
var http = require('http' );function (request, response) {'url' );let used = process.memoryUsage().heapUsed / 1024 / 1024;${Math.round(used * 100) / 100} MB`,'start' ,'测试' );let num = 0;for (let i = 1; i < 5900000000; i++) {'测试' );${Math.round(used * 100) / 100} MB`,'end' ,'Hello' + num);
测试结果:
跟字符串拼接有关,此刻关闭字符串拼接(此时为了快速测试,我把循环次数降到
5.9亿次)
var a = 'java' 'script' * 只连接100个以下的字符串建议用这种方法最方便
var arr = ['hello' ,'java' ,'script' ]"" )var a = 'java' ${a} script`
四、使用 JavaScript concat() 方法连接字符串
var a = 'java' 'script' function StringConnect function (str) {function return this.arr.join("" )"abc" )"def" )"g" )
我把字符串拼接换成了数组的
join方式(此时循环
5.9亿次)
var http = require('http' );function (request, response) {'url' );let used = process.memoryUsage().heapUsed / 1024 / 1024;${Math.round(used * 100) / 100} MB`,'start' ,'测试' );let num = 0;for (let i = 1; i < 590000000; i++) {'Hello' ];'测试' );${Math.round(used * 100) / 100} MB`,'end' ,'' ));
测试结果,发现接口调用的耗时稳定了(
注意此时是5.9亿次循环)
《javascript高级程序设计》中,有一段关于字符串特点的描述,原文大概如下:
ECMAScript中的字符串是不可变的,也就是说,字符串一旦创建,他们的值就不能改变。要改变某个变量的保存的的字符串,首先要销毁原来的字符串,然后再用另外一个包含新值的字符串填充该变量
用
+直接拼接字符串自然会对性能产生一些影响,因为字符串是不可变的,在操作的时候会产生临时字符串副本,
+操作符需要消耗时间,重新赋值分配内存需要消耗时间。
但是,我更换了代码后,发现,即使没有字符串拼接,也会耗时不稳定
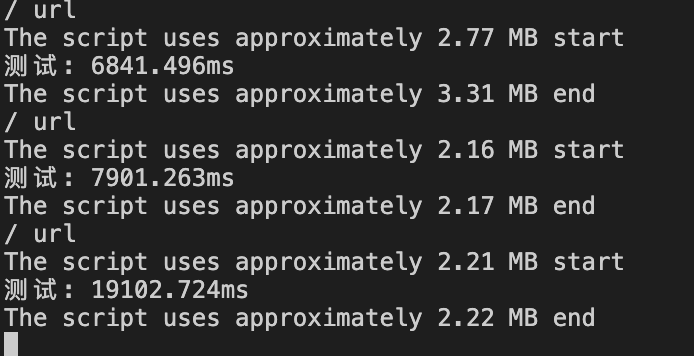
var http = require('http' );function (request, response) {'url' );let used = process.memoryUsage().heapUsed / 1024 / 1024;${Math.round(used * 100) / 100} MB`,'start' ,'测试' );let num = 0;for (let i = 1; i < 5900000000; i++) {'Hello' ];'测试' );${Math.round(used * 100) / 100} MB`,'end' ,'hello' );
测试结果:
现在我怀疑,不仅仅是字符串拼接的效率问题,更重要的是
for循环的耗时不一致
var http = require('http' );function (request, response) {'url' );let used = process.memoryUsage().heapUsed / 1024 / 1024;${Math.round(used * 100) / 100} MB`,'start' ,let num = 0;'测试' );for (let i = 1; i < 5900000000; i++) {'测试' );'Hello' ];${Math.round(used * 100) / 100} MB`,'end' ,'hello' );
测试运行结果:
for循环内部的
i++其实就是变量不断的重新赋值覆盖
经过我的测试发现,
40亿次跟
50亿次的区别,差距很大,
40亿次的for循环,都是稳定的,但是
50亿次就不稳定了.
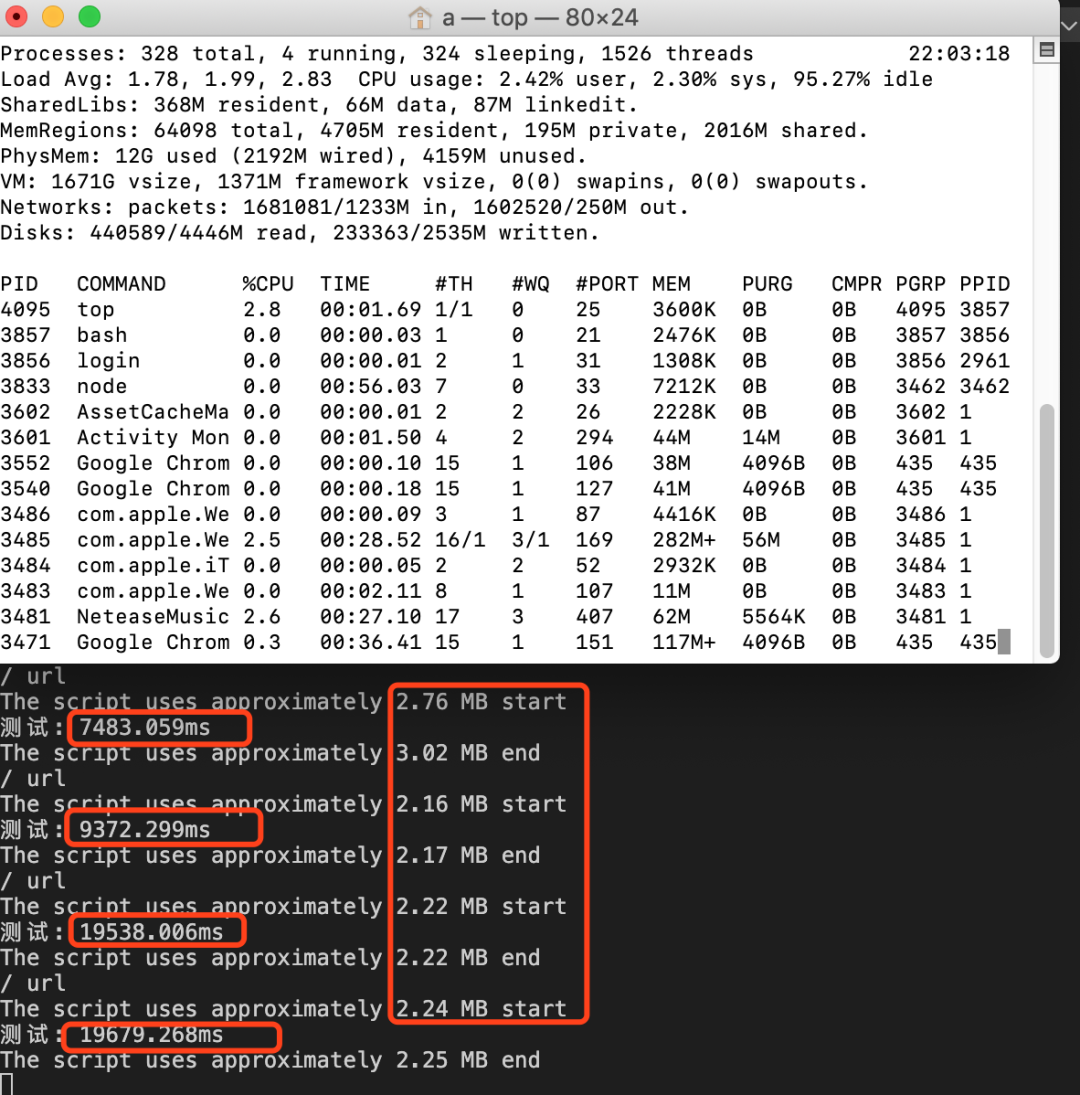
我们目前被阻塞的状态:
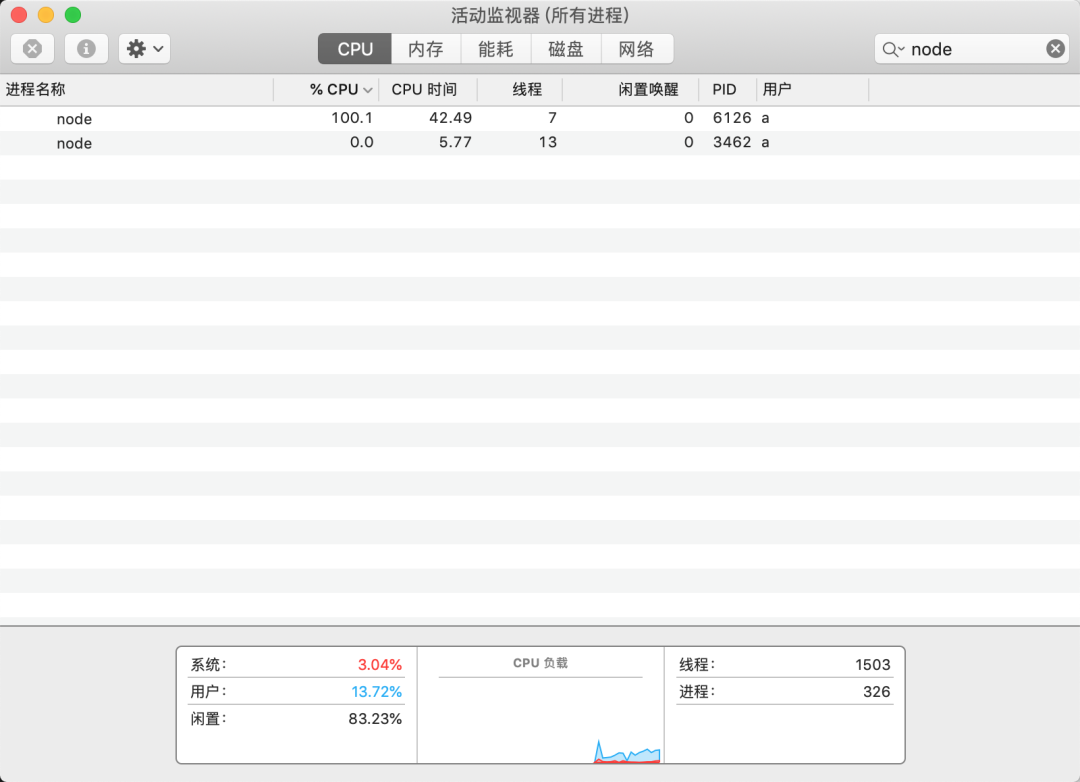
我电脑的CPU使用情况
遇到了
60亿次的循环,像有使用多进程异步计算的,但是本质上没有解决这部分循环代码的调用耗时。
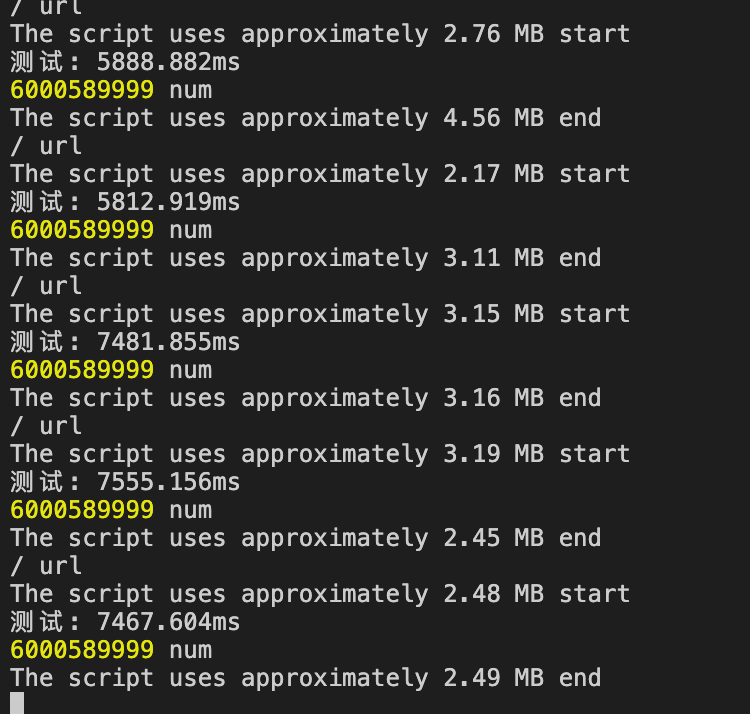
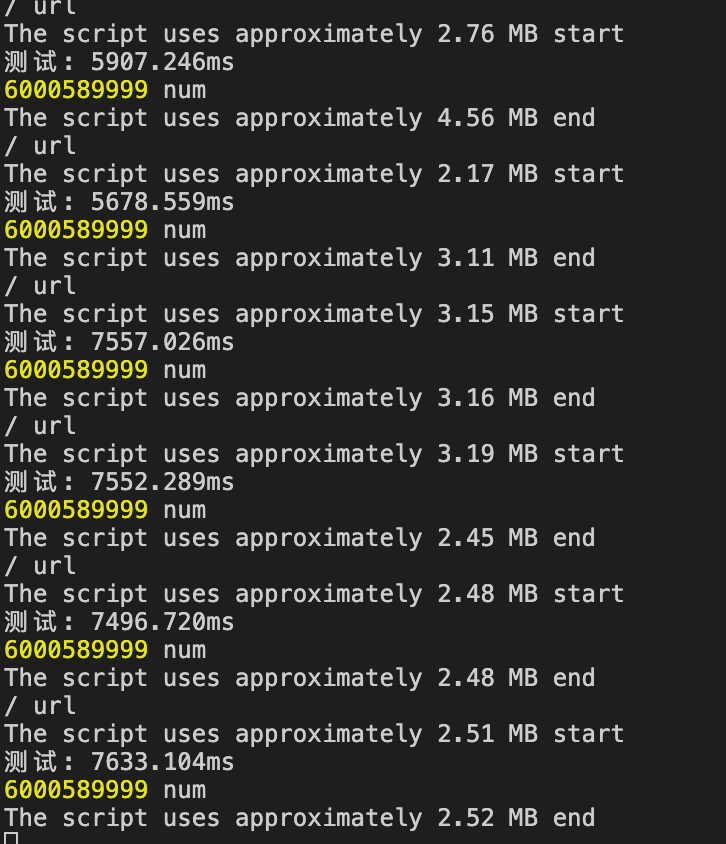
var http = require('http' );function (request, response) {'url' );let used = process.memoryUsage().heapUsed / 1024 / 1024;${Math.round(used * 100) / 100} MB`,'start' ,let num = 0;'测试' );for (let i = 1; i < 600000; i++) {for (let j = 0; j < 10000; j++) {'测试' );'Hello' ];'num' );${Math.round(used * 100) / 100} MB`,'end' ,'' ));
结果,耗时基本稳定,
60亿次循环总共:
var http = require('http' );function (request, response) {'url' );let used = process.memoryUsage().heapUsed / 1024 / 1024;${Math.round(used * 100) / 100} MB`,'start' ,let num = 0;'测试' );for (let i = 1; i < 600000; i++) {for (let j = 0; j < 10000; j++) {'测试' );'Hello' ];'num' );${Math.round(used * 100) / 100} MB`,'end' ,
测试结果稳定,符合预期:
对于单次循环超过一定阀值次数的,用拆解方式,
Node.js的运行耗时是稳定,但是如果是循环次数过多,那么就会出现刚才那种情况,阻塞严重,耗时不一样。
遍历60亿次,这个数字是有一些大了,如果是40亿次,是稳定的
这里应该还是跟
CPU有一些
关系,因为
top
查看一直是在
升高
此处虽然不是真正意义上的内存泄漏,但是我们如果在一个循环中不仅要不断更新
i的值到
60亿,还要不断更新
num的值
60亿,内存使用会不断上升,最终出现两份
60亿的数据,然后再回收。(
因为GC自动垃圾回收,一样会阻塞主线程,多次接口调用后,
CPU占用也会升高)
for (let i = 1; i < 60000; i++) {for (let j = 0; j < 100000; j++) {
❝
如果是异步的业务场景,也可以用多进程参与解决超大计算量问题,今天这里就不重复介绍了
❞
如果感觉写得不错,可以点个
在看/
赞,转发一下,让更多人看到
我是
Peter谭老师,欢迎你关注公众号:
前端巅峰,后台回复:
加群即可加入大前端交流群