重定向是计算机技术中非常底层的概念和操作。它指的是将程序中涉及到的变量名与变量在计算机内存中的位置关联起来。当在代码中执行类似x=1;的语句时,编译器需要通过重定向信息找到变量x对应的内存位置,然后将数值1写入该内存,因此重定向既跟程序的加载链接有关,又与编译原理有关,因此对计算机体系结构不了解,或只关注上层应用开发,对底层技术理解不多的同学对它进行掌握就会有些困难。
为了准确将变量对应到具体的内存位置,就必须要有相关信息来描述变量名与内存之间的关系,这些信息就叫重定向记录(relocation records),程序中描述的“变量”不仅仅指int,float类型的数据变量,还会涉及到函数的入口地址,而函数或者变量的入口地址常常在链接或动态装载时才会确定。例如下面代码:
void _start() {
foo()
}
如果boo实现放在一个obj1.c文件,函数foo实现放在boj2.c文件,那么编译后_start函数对应的二进制指令存储在obj1.o中,foo对应的二进制指令存储在obj2.o中,于是整个程序要顺利执行,就必须将obj1.o和obj2.o整合在一起,负责整合工作的就是连接器,它位于Linux系统的目录/bin/ld中。问题是如何将他们整合在一起,在执行boo函数时,内部调用foo函数时,IP寄存器能准确的指向foo函数第一条指令所在位置呢,这就需要编译器在编译代码时所生成的重定向数据结构,内容如下:
typedef struct {
ELF64_Addr r_offset;
Uint64_t r_info;
} Elf64_Rel;
typedef struct {
ELF64_Addr r_offset;
Uint64_t r_info;
int64_t r_addend;
} Elf64_Rela;
r_offset指向.o文件中需要指定其在内存中位置的偏移,例如obj1.o中,foo()这条语句编译成汇编指令后是e8 0 0 0 0,e8对应指令call, 那么“0 0 0 0”字节的在obj1.o内的位置就是r_offset,而”0 0 0 0“其实应该是函数foo第一条指令所在地址。
如果elf文件对应32位系统,那么重定向就使用第一个结构,如果对应64位系统就对应第二个结构。为了更好的理解结构中各个字段的意义,我们看一个具体例子,创建一个obj1.c文件,包含如下代码:
_start() {
foo()
}
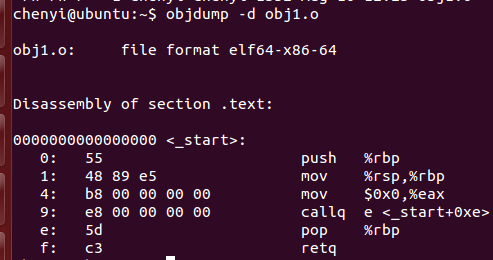
然后使用gcc -c obj1.c进行编译就会得到obj1.o文件,接着使用objdump -d obj1.o就可以看到如下内容:
![]()
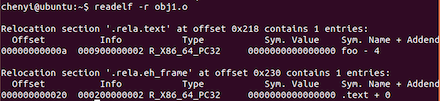
由于我们现在大多使用64位系统,因此我们着重理解第二个结构,从上图看到”0 0 0 0”这四个字节对于的偏移是0a,因为0x9对应指令e8占据了一个字节,所以r_offset的值就是0a,r_addend对应要修改的数据长度,因为”0 0 0 0”对应4个字节,因此r_addend对应的值就是4,我们可以使用命令readelf -r obj1.o 来查看结构体的内容:
![]()
可以看到第一条信息对应的就是结构体Elf64_Rela各个字段的内容。其中R_X86_64_PC32对应重定向的类型,不同类型决定了如何重新修改”0 0 0 0“这4个字节的内容,我们先将foo函数实现在ob2.c中,将其编译成obj2.o,然后链接ob1.o,obj2.o,最后再分析字节”0 0 0 0“是如何被修改的,obj2.c内容如下:
int foo() {
return 1;
}
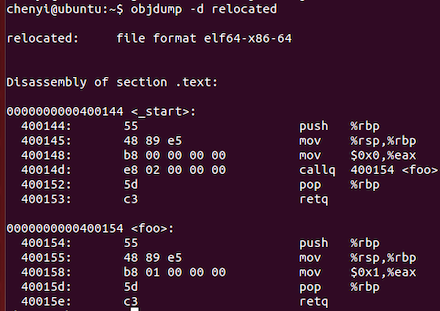
使用命令gcc -c boj2.c编译后得到obj2.o,然后使用命令gcc -nostdlib objj1.o obj2.o -o relocated 将两个.o文件链接成relocated文件,然后使用命令objdump -d relocated查看链接后的内容:
![]()
从上面可以看到原来e8后面的”0 0 0 0”改成了“02 00 00 00”,注意到第一个字节是低位字节,因此“02 00 00 00 “其实就是2,如果从”02 00 00 00“往后经过2个字节,对应语句5d, c3后进入地址400154,这恰好就是函数foo第一条指令所在地址,也就是”02 00 00 00”其实是foo函数入口地址相对于call这条指令之后的偏移。
”02 00 00 00“是怎么计算的呢。它首先用foo的起始地址也就是400154减去call指令经过一字节后的地址,也就是40014d+1=40014e,然后再减去addend对应数值,其实就是要修改的数据长度,根据前面使用readelf -r obj1.o指令显示的内容,这个值就是4,于是链接后”00 00 00 00”被修改的值就是0x400154-0x40015e-4=2,也就是”02 00 00 00”。于是链接后地址的修改算法为,被调用函数的地址-call指令所在地址-表示地址的字节长度。
这种地址修改其实给黑客劫持进程提供了入口,这种黑客技术也叫重定向代码注入。原本计划将该技术用代码实现后再将文章发布,但在实现过程中发现技术难度较大,有不少问题消耗一周多的时间依然没有解决,再加上最近其他工作的压力使得我腾不出手来,因此先将这部分理论发布出来,后续在代码实现完成后再针对该技术的具体实现原理进行进一步解析。