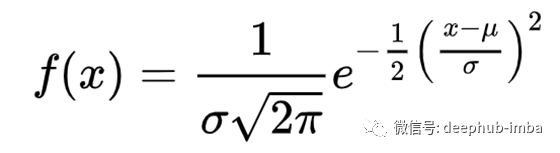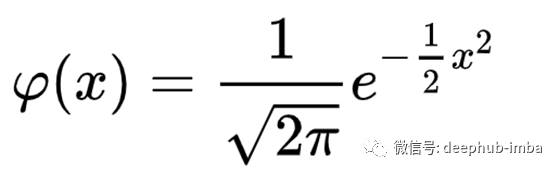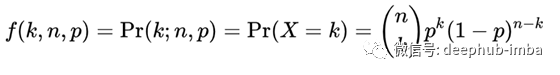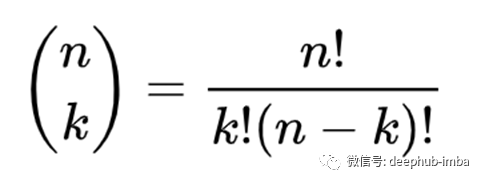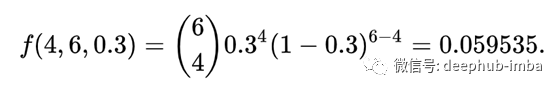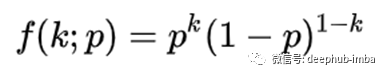![]()
随机变量在概率空间中遵循不同类型的分布,这决定了它们的特征并有助于预测。
本文内容列表:
引言
高斯/正态分布(Gaussian/Normal Distribution)
二项分布(Binomial Distribution)
伯努利分布(Bernoulli Distribution)
对数正态分布(Log Normal Distribution)
幂律分布(Power Law Distribution)
分布函数的使用
引言
每当我们遇到任何概率实验,我们谈论的是随机变量,它只不过是获取实验预期结果的变量。例如,当我们掷骰子时,我们期望从集合{1,2,3,4,5,6}中得到一个值。所以我们定义了一个随机变量X,它在每次掷骰时取这些值。
根据实验的不同,随机变量可以取离散值,也可以取连续值。骰子的例子是离散随机变量,因为它取一个离散值。但是假设我们讨论的是某个城镇的房价,那么相关的随机变量可以取连续的值(例如550000美元,1200523.54美元等等)。
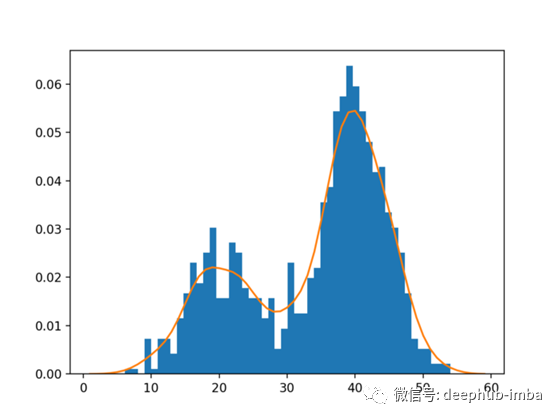
当我们将随机变量的期望值与实验中出现频率的关系图绘制出来时,我们得到了一个直方图形式的频率分布图。利用核密度估计对这些直方图进行平滑处理,得到了一条很好的曲线。这条曲线被称为“分布函数”。
![]()
橙色平滑曲线是概率分布曲线
高斯/正态分布
高斯/正态分布是一个连续的概率分布函数,随机变量在均值(μ)和方差(σ²)周围对称分布。
![]()
高斯分布函数
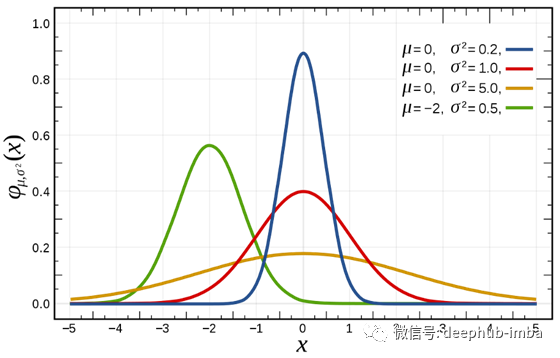
平均值(μ):决定峰值在X轴上的位置。而且,所有数据都对称地位于X=μ线的两侧。如图所示,蓝色、红色和黄色曲线分布在X=0的两侧,而绿色曲线的中心位于X=-2。所以通过观察这些曲线,我们可以很容易地说,蓝色,红色和黄色的平均值是0,而绿色的平均值是-2。
方差(σ²):决定曲线的宽度和高度。方差只不过是标准差的平方。请注意,图中给出了所有四条曲线的σ²值。现在不看数值,我们可以很直观地发现,黄色曲线的高度最低。
![]()
如果我们设置μ=0和σ=1,则称为标准正态分布或标准正态变量,一般表达式变为:
![]()
标准正态分布函数
现在我们可以思考,分母意味着什么?这是为了确保正态分布曲线下的面积总是等于1。
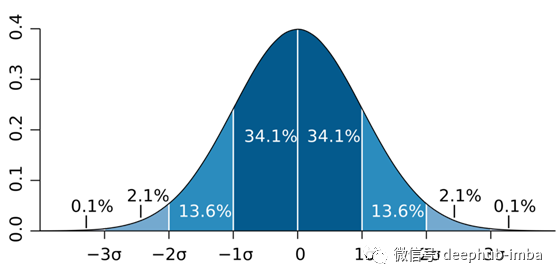
我们从正态分布中可以得到很多有用的数据分割信息。以下图为例:
![]()
正态分布的值分割图
如图所示,如果我们从平均值右移一个标准差,这个分布存储了总质量的34.1%;如果我们从平均值右移2个标准偏差,则为49.8%。因为这条曲线是对称的,所以两边都适用。
所以,现在我们知道了,如果任何数据服从正态分布,例如城镇人口的权重,我们可以很容易地估计出很多值,而不需要进行实际的广泛分析。这就是正态分布的力量。
二项分布(Binomial Distribution)
正如我们在名字里看到的,有一个“Bi”。这个‘Bi’代表一个实验的2个结果,要么是肯定的,要么是失败的,要么是1或者0等等。最简单的说,这个分布是多次重复实验的分布以及它们的概率,其中预期结果要么是“成功”要么是“失败”。
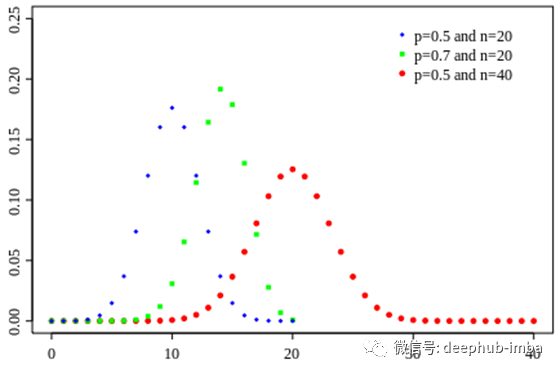
![]()
二项分布
从图像上可以看出,它是一个离散的概率分布函数。主要参数为n(试验次数)和p(成功概率)。
现在假设我们有一个事件成功的概率p,那么失败的概率是(1-p),假设你重复实验n次(试验次数=n)。那么在n个独立的伯努利试验中获得k个成功的概率是:
![]()
二项分布函数
其中k属于范围[0,n],并且:
![]()
现在我们思考一个简单的问题。假设印度和澳大利亚之间正在进行板球比赛。Rohit Sharma已经得到了151分,根据你的经验,你知道150分之后,Rohit有0.3分的概率达到6分。这是最后一节了,你父亲问你Rohit有多大的机会能打4个全垒打。那你怎么判断呢?
这是一个典型的二项试验的例子。所以,解决办法是:
![]()
注:大括号中的6和4是6C4,它是6个球中4个全垒打的可能组合。
伯努利分布
在二项分布中,我们有一个特殊的例子叫做伯努利分布,其中n=1,这意味着在这个二项实验中只进行了一次试验。当我们把n=1放入二项PMF(概率质量函数)中时,nCk等于1,函数变成:
![]()
伯努利分布PMF
式中,k={0,1}。
现在我们来看看印度队对澳大利亚队的比赛。假设当Rohit达到100分(a ton),那么印度获胜的几率是0.7。所以你可以简单地告诉你父亲印度有70%的机会赢了。
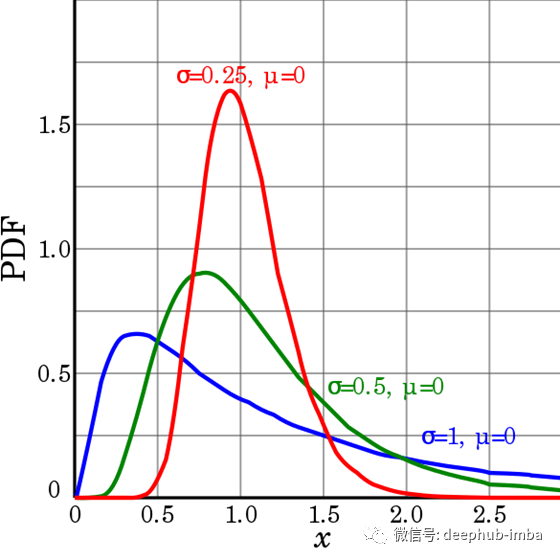
对数正态分布
我们已经了解了正态分布的性质,乍一看,许多人会说,对数正态曲线在某种程度上也让我们看到了正态分布是右偏态的。
![]()
假设有一个随机变量X服从对数正态分布,均值=μ,方差=σ²。X有总共n个可能值(x1,x2,x3…..xn)。现在取所有X值的自然对数,并创建一个新的随机变量Y=[Log(x1),Log(x2),Log(x3)…Log(xn)]。这个随机变量Y是正态分布的。
换句话说,如果存在正态分布Y,并且我们取它的指数函数X=exp(Y),那么X将遵循对数正态分布。
它还具有与高斯函数相同的参数:均值(μ)和方差(σ²)。
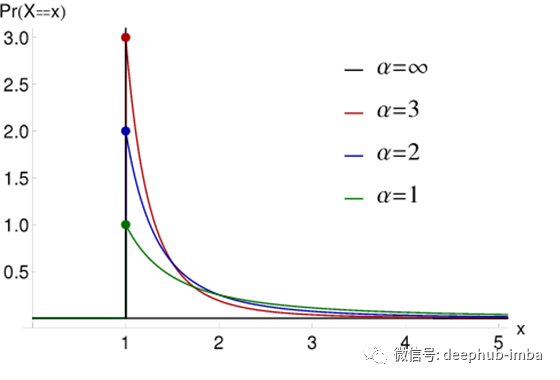
幂律/帕累托分布
幂律是两个量之间的关系,其中一个量的变化将成比例地改变另一个量。它遵循一个80-20法则:在前20%的值中,我们可以找到大约80%的质量密度。如图所示,稍暗的左侧部分为质量的80%,右侧亮黄色部分为20%。
![]()
当概率分布遵循幂律时,我们称之为帕累托分布。帕累托分布由两个参数控制:x_m和α。xμm可以看作是控制曲线尺度的均值,α可以看作是控制曲线形状的σ。(注:x_m不是平均值,α不是σ。)现在我们可以在图像中看到,所有四条曲线的峰值都位于x=1。所以,我们可以说对于图中的所有曲线,x_m=1。随着α的增加,峰值也会上升,在α趋于无穷大的极端情况下,曲线仅转变为一条垂直线。这叫做Diracδ函数。随着α的减小,曲线变得更加平缓。
![]()
帕累托分布PMF
分布函数的使用
如果我们知道一个特定的数据遵循一定的分布特征,那么我们可以采取部分样本,找到所涉及的参数,然后可以绘制出概率分布函数来解决许多问题。例如:在一个有10万人口的城镇,我们必须做身高分析,但我们不能对这么多人口进行调查。因此,我们选取一个随机样本,求出样本均值和样本标准差。现在假设一位医生或专家告诉我们身高服从正态分布。这样我们就可以轻松地回答许多问题了。
作者: Saurabh Raj
deephub翻译组:Oliver Lee
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!![]()