这次发布,主要是对性能进行第一轮测试,以验证从2升级到3后,性能没有显著下降。
- 修复MarkdownClasspathLoader 每次都从sql文件加载sql片段的bug,导致性能严重下降
- 修复ConfigJoinMapper映射一对多时候不识别大写列名的bug
性能测试主要测试了BeetlSQL,MyBatis(plus),JPA(Hibernate),JDBC和 Weed3, BeetlSQL和Weed3都是国产DAO工具
Benchmark Mode Cnt Score Error Units
JMHMain.beetlsqlComplexMapping thrpt 5 195.364 ± 77.645 ops/ms
JMHMain.beetlsqlExecuteJdbc thrpt 5 394.119 ± 194.906 ops/ms
JMHMain.beetlsqlExecuteTemplate thrpt 5 381.499 ± 26.086 ops/ms
JMHMain.beetlsqlFile thrpt 5 447.060 ± 11.511 ops/ms
JMHMain.beetlsqlInsert thrpt 5 251.468 ± 130.649 ops/ms
JMHMain.beetlsqlLambdaQuery thrpt 5 264.216 ± 15.167 ops/ms
JMHMain.beetlsqlOne2Many thrpt 5 109.499 ± 14.781 ops/ms
JMHMain.beetlsqlPageQuery thrpt 5 209.418 ± 10.847 ops/ms
JMHMain.beetlsqlSelectById thrpt 5 382.884 ± 22.160 ops/ms
JMHMain.jdbcExecuteJdbc thrpt 5 1096.030 ± 37.110 ops/ms
JMHMain.jdbcInsert thrpt 5 331.819 ± 228.323 ops/ms
JMHMain.jdbcSelectById thrpt 5 1069.215 ± 81.210 ops/ms
JMHMain.jpaExecuteJdbc thrpt 5 109.956 ± 13.743 ops/ms
JMHMain.jpaExecuteTemplate thrpt 5 134.473 ± 11.563 ops/ms
JMHMain.jpaInsert thrpt 5 81.052 ± 14.006 ops/ms
JMHMain.jpaOne2Many thrpt 5 101.677 ± 13.461 ops/ms
JMHMain.jpaPageQuery thrpt 5 119.050 ± 7.998 ops/ms
JMHMain.jpaSelectById thrpt 5 324.978 ± 14.455 ops/ms
JMHMain.mybatisComplexMapping thrpt 5 96.171 ± 13.213 ops/ms
JMHMain.mybatisExecuteTemplate thrpt 5 192.065 ± 17.957 ops/ms
JMHMain.mybatisFile thrpt 5 136.911 ± 12.952 ops/ms
JMHMain.mybatisInsert thrpt 5 142.749 ± 34.862 ops/ms
JMHMain.mybatisLambdaQuery thrpt 5 14.581 ± 1.696 ops/ms
JMHMain.mybatisPageQuery thrpt 5 62.365 ± 9.497 ops/ms
JMHMain.mybatisSelectById thrpt 5 194.090 ± 46.959 ops/ms
JMHMain.weedExecuteJdbc thrpt 5 454.037 ± 37.330 ops/ms
JMHMain.weedExecuteTemplate thrpt 5 253.859 ± 21.164 ops/ms
JMHMain.weedFile thrpt 5 534.792 ± 48.711 ops/ms
JMHMain.weedInsert thrpt 5 233.368 ± 141.993 ops/ms
JMHMain.weedLambdaQuery thrpt 5 454.978 ± 46.672 ops/ms
JMHMain.weedPageQuery thrpt 5 237.196 ± 33.993 ops/ms
JMHMain.weedSelectById thrpt 5 420.247 ± 28.087 ops/ms
从测试结果看,BeetlSQL性能非常好,至少是JPA和Mybatis的2倍以上,且满足所有的9种测试场景
maven
<dependency>
<groupId>com.ibeetl</groupId>
<artifactId>beetlsql-all</artifactId>
<version>3.0.0-M2</version>
</dependency>
BeetlSQL是一款数据库访问工具库,广泛应用到企业应用,互联网项目。相比于BeetlSQL2,新版支持更多基于JDBC的数据来源,包括支传统数据库,大数据NOSQL,以及大数据SQL查询引擎,在易用性何扩展性也做了大幅度修改。BeetlSQL3 能最大程度提高开发数据库访问的效率和增强相关代码维护性
例子1,内置方法,无需写SQL完成常用操作
UserEntity user = sqlManager.unique(UserEntity.class,1);
user.setName("ok123");
sqlManager.updateById(user);
UserEntity newUser = new UserEntity();
newUser.setName("newUser");
newUser.setDepartmentId(1);
sqlManager.insert(newUser);
输出日志友好,可反向定位到调用的代码
┏━━━━━ Debug [user.selectUserAndDepartment] ━━━
┣ SQL: select * from user where 1 = 1 and id=?
┣ 参数: [1]
┣ 位置: org.beetl.sql.test.QuickTest.main(QuickTest.java:47)
┣ 时间: 23ms
┣ 结果: [1]
┗━━━━━ Debug [user.selectUserAndDepartment] ━━━
例子2 使用SQL
String sql = "select * from user where id=?";
Integer id = 1;
SQLReady sqlReady = new SQLReady(sql,new Object[id]);
List<UserEntity> userEntities = sqlManager.execute(sqlReady,UserEntity.class);
//Map 也可以作为输入输出参数
List<Map> listMap = sqlManager.execute(sqlReady,Map.class);
例子3 使用模板SQL
String sql = "select * from user where department_id=#{id} and name=#{name}";
UserEntity paras = new UserEntity();
paras.setDepartmentId(1);
paras.setName("lijz");
List<UserEntity> list = sqlManager.execute(sql,UserEntity.class,paras);
String sql = "select * from user where id in ( #{join(ids)} )";
List list = Arrays.asList(1,2,3,4,5); Map paras = new HashMap();
paras.put("ids", list);
List<UserEntity> users = sqlManager.execute(sql, UserEntity.class, paras);
例子4 使用Query类
支持重构
LambdaQuery<UserEntity> query = sqlManager.lambdaQuery(UserEntity.class);
List<UserEntity> entities = query.andEq(UserEntity::getDepartmentId,1)
.andIsNotNull(UserEntity::getName).select();
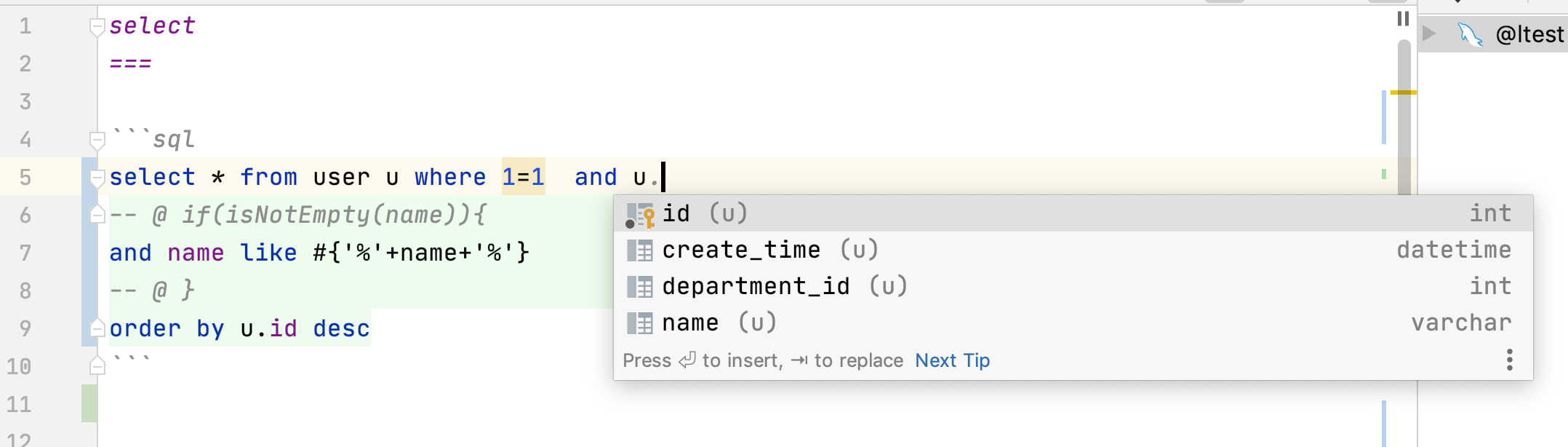
例子5 把数十行SQL放到sql文件里维护
//访问user.md#select
SqlId id = SqlId.of("user","select");
Map map = new HashMap();
map.put("name","n");
List<UserEntity> list = sqlManager.select(id,UserEntity.class,map);
![]()
例子6 复杂映射支持
支持像mybatis那样复杂的映射
@Data
@ResultProvider(AutoJsonMapper.class)
public static class MyUserView {
UserInfo user;
DepartmentEntity dept;
}
- 配置映射,比MyBatis更容易理解,报错信息更详细
{
"id": "id",
"name": "name",
"dept": {
"id": "dept_id",
"name": "dept_name"
},
"roles": {
"id": "r_id",
"name": "r_name"
}
}
例子7 最好使用mapper来作为数据库访问类
@SqlResource("user") /*sql文件在user.md里*/
public interface UserMapper extends BaseMapper<UserEntity> {
@Sql("select * from user where id = ?")
UserEntity queryUserById(Integer id);
@Sql("update user set name=? where id = ?")
@Update
int updateName(String name,Integer id);
@Template("select * from user where id = #{id}")
UserEntity getUserById(Integer id);
@SpringData/*Spring Data风格*/
List<UserEntity> queryByNameOrderById(String name);
/**
* 可以定义一个default接口
* @return
*/
default List<DepartmentEntity> findAllDepartment(){
Map paras = new HashMap();
paras.put("exlcudeId",1);
List<DepartmentEntity> list = getSQLManager().execute("select * from department where id != #{exlcudeId}",DepartmentEntity.class,paras);
return list;
}
/**
* 调用sql文件user.md#select,方法名即markdown片段名字
* @param name
* @return
*/
List<UserEntity> select(String name);
/**
* 翻页查询,调用user.md#pageQuery
* @param deptId
* @param pageRequest
* @return
*/
PageResult<UserEntity> pageQuery(Integer deptId, PageRequest pageRequest);
@SqlProvider(provider= S01MapperSelectSample.SelectUserProvider.class)
List<UserEntity> queryUserByCondition(String name);
@SqlTemplateProvider(provider= S01MapperSelectSample.SelectUs
List<UserEntity> queryUserByTemplateCondition(String name);
}
你看到的这些用在Mapper上注解都是可以自定义,自己扩展的
例子8 使用Fetch 注解
可以在查询后根据Fetch注解再次获取相关对象,实际上@FetchOne和 @FetchMany是自定义的,用户可自行扩展
@Data
@Table(name="user")
@Fetch
public static class UserData {
@Auto
private Integer id;
private String name;
private Integer departmentId;
@FetchOne("departmentId")
private DepartmentData dept;
}
/**
* 部门数据使用"b" sqlmanager
*/
@Data
@Table(name="department")
@Fetch
public static class DepartmentData {
@Auto
private Integer id;
private String name;
@FetchMany("departmentId")
private List<UserData> users;
}
例子9 不同数据库切换
可以自行扩展ConditionalSQLManager的decide方法,来决定使用哪个SQLManager
SQLManager a = SampleHelper.init();
SQLManager b = SampleHelper.init();
Map<String, SQLManager> map = new HashMap<>();
map.put("a", a);
map.put("b", b);
SQLManager sqlManager = new ConditionalSQLManager(a, map);
//不同对象,用不同sqlManager操作,存入不同的数据库
UserData user = new UserData();
user.setName("hello");
user.setDepartmentId(2);
sqlManager.insert(user);
DepartmentData dept = new DepartmentData();
dept.setName("dept");
sqlManager.insert(dept);
使用注解 @TargetSQLManager来决定使用哪个SQLManger
@Data
@Table(name = "department")
@TargetSQLManager("b")
public static class DepartmentData {
@Auto
private Integer id;
private String name;
}
例子10 如果想给每个sql语句增加一个sqlId标识
这样好处是方便数据库DBA与程序员沟通
public static class SqlIdAppendInterceptor implements Interceptor{
@Override
public void before(InterceptorContext ctx) {
ExecuteContext context = ctx.getExecuteContext();
String jdbcSql = context.sqlResult.jdbcSql;
String info = context.sqlId.toString();
//为发送到数据库的sql增加一个注释说明,方便数据库dba能与开发人员沟通
jdbcSql = "/*"+info+"*/\n"+jdbcSql;
context.sqlResult.jdbcSql = jdbcSql;
}
}
例子11 代码生成框架
可以使用内置的代码生成框架生成代码何文档,也可以自定义的,用户可自行扩展SourceBuilder类
List<SourceBuilder> sourceBuilder = new ArrayList<>();
SourceBuilder entityBuilder = new EntitySourceBuilder();
SourceBuilder mapperBuilder = new MapperSourceBuilder();
SourceBuilder mdBuilder = new MDSourceBuilder();
//数据库markdown文档
SourceBuilder docBuilder = new MDDocBuilder();
sourceBuilder.add(entityBuilder);
sourceBuilder.add(mapperBuilder);
sourceBuilder.add(mdBuilder);
sourceBuilder.add(docBuilder);
SourceConfig config = new SourceConfig(sqlManager,sourceBuilder);
//只输出到控制台
ConsoleOnlyProject project = new ConsoleOnlyProject();
String tableName = "USER";
config.gen(tableName,project);
例子13 定义一个Beetl函数
GroupTemplate groupTemplate = groupTemplate();
groupTemplate.registerFunction("nextDay",new NextDayFunction());
Map map = new HashMap();
map.put("date",new Date());
String sql = "select * from user where create_time is not null and create_time<#{nextDay(date)}";
List<UserEntity> count = sqlManager.execute(sql,UserEntity.class,map);
nextDay函数是一个Beetl函数,非常容易定义,非常容易在sql模板语句里使用
public static class NextDayFunction implements Function {
@Override
public Object call(Object[] paras, Context ctx) {
Date date = (Date) paras[0];
Calendar c = Calendar.getInstance();
c.setTime(date);
c.add(Calendar.DAY_OF_YEAR, 1); // 今天+1天
return c.getTime();
}
}
例子14 更多可扩展的例子
根据ID或者上下文自动分表,toTable是定义的一个Beetl函数,
static final String USER_TABLE="${toTable('user',id)}";
@Data
@Table(name = USER_TABLE)
public static class MyUser {
@AssignID
private Integer id;
private String name;
}
定义一个Jackson注解,@Builder是注解的注解,表示用Builder指示的类来解释执行,可以看到BeetlSQL的注解可扩展性就是来源于@Build注解
@Retention(RetentionPolicy.RUNTIME)
@Target(value = {ElementType.METHOD, ElementType.FIELD})
@Builder(JacksonConvert.class)
public @interface Jackson {
}
定义一个@Tenant 放在POJO上,BeetlSQL执行时候会给SQL添加额外参数,这里同样使用了@Build注解
/**
* 组合注解,给相关操作添加额外的租户信息,从而实现根据租户分表或者分库
*/
@Retention(RetentionPolicy.RUNTIM@
@Target(value = {ElementType.TYPE})
@Builder(TenantContext.class)
public @interface Tenant {
}
使用XML而不是JSON作为映射
@Retention(RetentionPolicy.RUNTIME)
@Target(value = {ElementType.TYPE})
@Builder(ProviderConfig.class)
public @interface XmlMapping {
String path() default "";
}
参考源码例子 PluginAnnotationSample了解如何定义自定的注解,实际上BeetlSQL有一半的注解都是通过核心注解扩展出来的
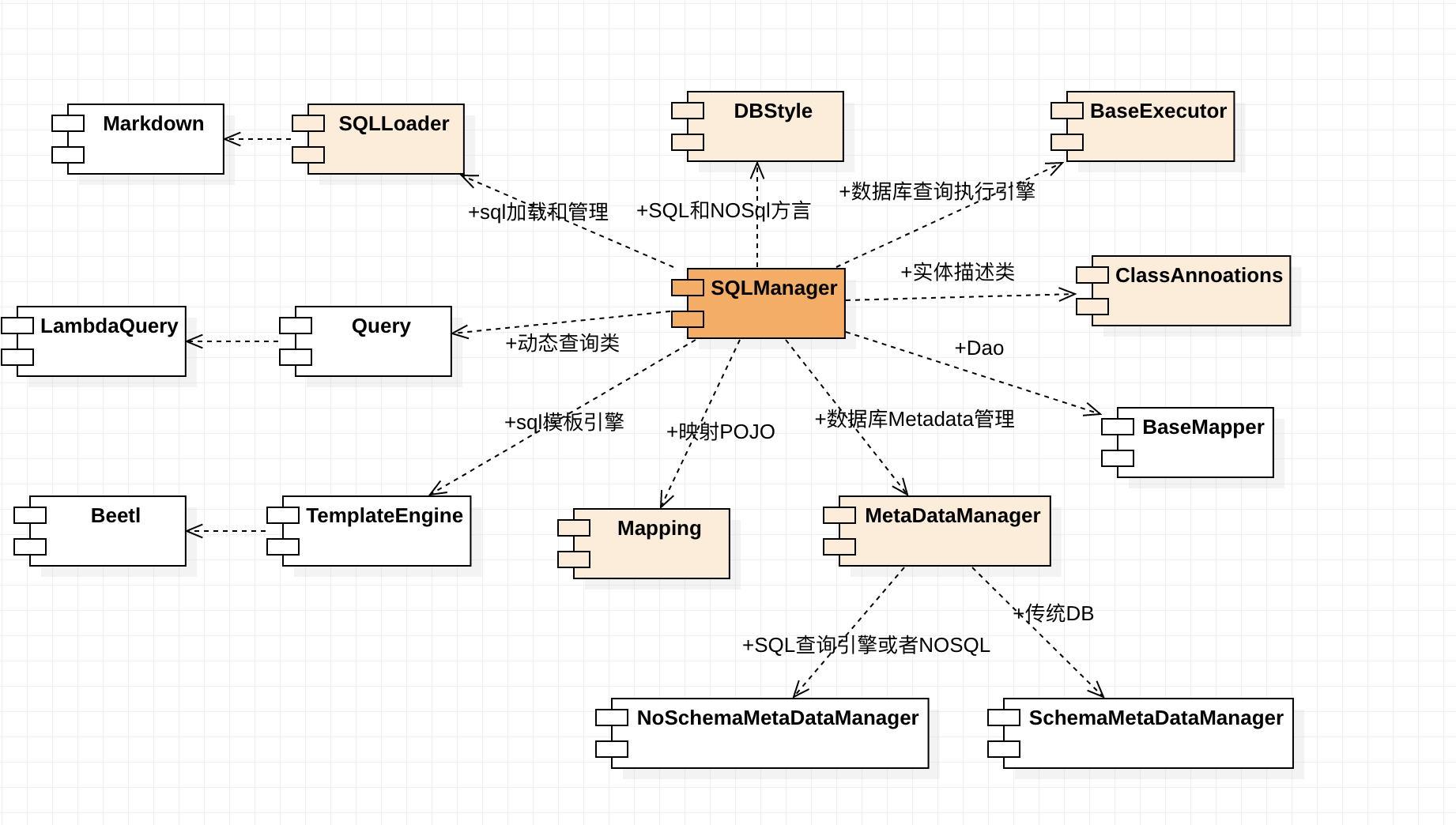
BeetlSQL的架构如下,欢迎参与到BeetlSQL3的生态开发 ![]()