![]()
之前写过一些关于 Raft 原理的文章。
图解分布式一致性算法
Raft协议详解
相比 Paxos, Raft 一直以来就是以易于理解著称。今天我们以一年 Raft 使用者的角度,来看一下,别人根据 Raft 论文实现了之后,我们一般要怎么样使用。
俗话说,要想知道梨子的味道,就要亲口尝一尝,没吃过猪肉,也要见一见猪跑。否则别人再怎么样形容,你可能还以为是像猫狗一类毛茸茸。
在 Raft 官网里长长的列表就能发现,实现 Raft 的框架目前不少。Java 里我大概看了蚂蚁的 SOFARaft 和 Apache 的 Ratis。这次我们以 Ratis 为例,揭开面纱,来看看到底要怎样使用。
当然,下面具体提到的例子,也是这些组件中自带的 example。
一、编译
github下载 Ratis 直接 mvn clean package 即可,如果编译过程中出错,可以先clean install ratis-proto
二、示例
Ratis 自带的示例有三个:
arithmetic
counter
filestore
在 ratis-examples 模块中,对于 arithmetic 和 filestore比较方便,可以通过main/bin目录下的 shell 脚本快速启动 Server 和 Client 来进行测试。
对于Raft,咱们都知道是需要多实例组成集群才能测试,你启动一个实例没啥用,连选主都成问题。Bin 目录下的 start-all 支持 example 的名称以及对应的命令。比如 filestore server 代表是启动 filestore 这个应用的server。对应的命令参数会在相应example里的 cli 中解析。同时会一次性启动三个server,组成一个集群并在周期内完成选举。
而对于 counter 这个示例,并没有相应的脚本来快速启动三个server,这个我们可以通过命令行或者在IDE里以参数的形式启动。
三、分析
下面我们来示例里看下 Raft Server 是怎样工作的。
对于 counter 示例来说,我们启动的时候,需要传入一个参数,代表当前的server是第几个,目的在于,要从 peers 列表中得知该用哪个IP + 端口去启动它。这里我们能发现,这个 peers 列表,是在代码内提前设置好的。当然你说动态配置啥的,也没啥问题,另外两个示例是通过shell 脚本里common 中的配置传入的。
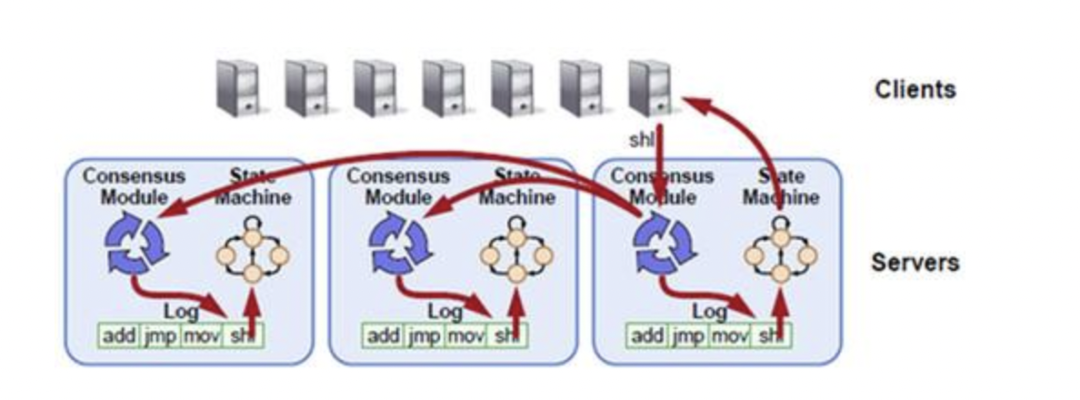
所以,第一步我们看到, Raft Server 在启动的时候,会通过「配置」的形式,来知道 peer 之间的存在,这样才能彼此通信,让别人给自己投票或者给别人投票,完成 Term 内的选举。另外,才能接收到 Leader 传过来的 Log ,并且应用到本地。
第二步,我们来看下 Client 和 集群之间是如何通信的。整个 Raft 集群可能有多个实例,我们知道必须通过 Leader 来完成写操作。那怎样知道谁是Leader?有什么办法?
一般常见的思路有:
当然方式二这样试下去效率不太高。所以会在这个随机试一次之后,集群会将当前的 Leader 信息返回给 Client,然后 Client 直接通过这个建立连接进行通信即可。
在 Ratis 里, Client 调用非 Leader 节点会收到 Server 抛出的一个异常,异常中会包含一个称为 suggestLeader 的信息,表示当前正确的 Leader,按这个连上去就行。当然,如果如果在此过程中发生的 Leader 的变更,那就会有一个新的suggestLeader 返回来,再次重试。
我们来看 Counter 这个示例中的实现。
Server 和 Client 的共用的Common 代码中,包含 peers 的声明
public final class CounterCommon { public static final List<RaftPeer> PEERS = new ArrayList<>(3);
static { PEERS.add(new RaftPeer(RaftPeerId.getRaftPeerId("n1"), "127.0.0.1:6000")); PEERS.add(new RaftPeer(RaftPeerId.getRaftPeerId("n2"), "127.0.0.1:6001")); PEERS.add(new RaftPeer(RaftPeerId.getRaftPeerId("n3"), "127.0.0.1:6002")); }
这里声明了三个节点。
通过命令行启动时,会直接把index 传进来, index 取值1-3。
java -cp *.jar org.apache.ratis.examples.counter.server.CounterServer {serverIndex}
然后在Server 启动的时候,拿到对应的配置信息。
//find current peer object based on application parameter RaftPeer currentPeer = CounterCommon.PEERS.get(Integer.parseInt(args[0]) - 1);
再设置存储目录
//set the storage directory (different for each peer) in RaftProperty object File raftStorageDir = new File("./" + currentPeer.getId().toString()); RaftServerConfigKeys.setStorageDir(properties, Collections.singletonList(raftStorageDir))
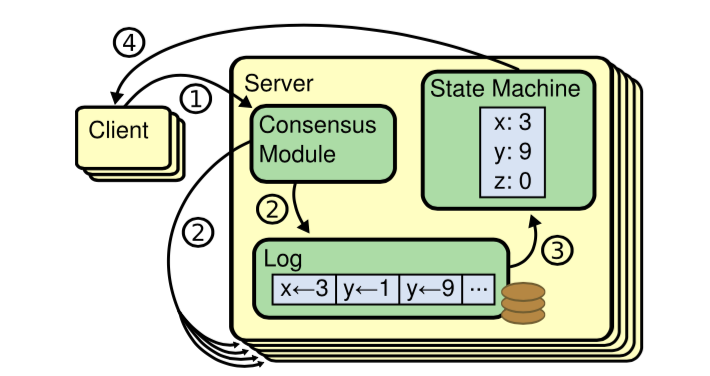
重点看这里,每个 Server 都会有一个状态机「CounterStateMachine」,平时我们的「业务逻辑」都放到这里
//create the counter state machine which hold the counter value CounterStateMachine counterStateMachine = new CounterStateMachine();
客户端发送的命令,会在这个状态机中被执行,同时这些命令又以Log 的形式复制给其它节点,各个节点的Log 又会在它自己的状态机里执行,从而保证各个节点状态的一致。
![]()
![]()
最后根据这些配置,生成 Raft Server 实例并启动。
//create and start the Raft server RaftServer server = RaftServer.newBuilder() .setGroup(CounterCommon.RAFT_GROUP) .setProperties(properties) .setServerId(currentPeer.getId()) .setStateMachine(counterStateMachine) .build(); server.start();
CounterStateMachine 里,应用计数的这一小段代码,我们看先检查了命令是否合法,然后执行命令
//check if the command is valid String logData = entry.getStateMachineLogEntry().getLogData() .toString(Charset.defaultCharset()); if (!logData.equals("INCREMENT")) { return CompletableFuture.completedFuture( Message.valueOf("Invalid Command")); } //update the last applied term and index final long index = entry.getIndex(); updateLastAppliedTermIndex(entry.getTerm(), index);
//actual execution of the command: increment the counter counter.incrementAndGet();
//return the new value of the counter to the client final CompletableFuture<Message> f = CompletableFuture.completedFuture(Message.valueOf(counter.toString()));
//if leader, log the incremented value and it's log index if (trx.getServerRole() == RaftProtos.RaftPeerRole.LEADER) { LOG.info("{}: Increment to {}", index, counter.toString()); }
我们再来看 Client 的实现。
和 Server 类似,通过配置属性,创建一个实例
private static RaftClient buildClient() { RaftProperties raftProperties = new RaftProperties(); RaftClient.Builder builder = RaftClient.newBuilder() .setProperties(raftProperties) .setRaftGroup(CounterCommon.RAFT_GROUP) .setClientRpc( new GrpcFactory(new Parameters()) .newRaftClientRpc(ClientId.randomId(), raftProperties)); return builder.build(); }
然后就可以向Server发送命令开工了。
raftClient.send(Message.valueOf("INCREMENT"));
Counter 的状态机支持INCREMENT 和 GET 两个命令。所以example 最后执行了一个 GET 的命令来获取最终的计数结果
RaftClientReply count = raftClient.sendReadOnly(Message.valueOf("GET"));
四、内部部分实现
RaftClientImpl 里,初期会从peers列表中选一个,当成leader 去请求。
RaftClientImpl(ClientId clientId, RaftGroup group, RaftPeerId leaderId, RaftClientRpc clientRpc, RaftProperties properties, RetryPolicy retryPolicy) { this.clientId = clientId; this.clientRpc = clientRpc; this.peers = new ConcurrentLinkedQueue<>(group.getPeers()); this.groupId = group.getGroupId(); this.leaderId = leaderId != null? leaderId : !peers.isEmpty()? peers.iterator().next().getId(): null; ... }
之后,会根据server 返回的不同异常分别处理。
private RaftClientReply sendRequest(RaftClientRequest request) throws IOException { RaftClientReply reply; try { reply = clientRpc.sendRequest(request); } catch (GroupMismatchException gme) { throw gme; } catch (IOException ioe) { handleIOException(request, ioe); } reply = handleLeaderException(request, reply, null); reply = handleRaftException(reply, Function.identity()); return reply; }
比如在 handleLeaderException 中,又分几种情况,因为通过Client 来和 Server 进行通讯的时候,会随机从peers里选择一个,做为leader去请求,如果 Server 返回异常,说它不是leader,就用下面的代码,随机从另外的peer里选择一个再去请求。
final RaftPeerId oldLeader = request.getServerId(); final RaftPeerId curLeader = leaderId; final boolean stillLeader = oldLeader.equals(curLeader); if (newLeader == null && stillLeader) { newLeader = CollectionUtils.random(oldLeader, CollectionUtils.as(peers, RaftPeer::getId)); }
static <T> T random(final T given, Iterable<T> iteration) { Objects.requireNonNull(given, "given == null"); Objects.requireNonNull(iteration, "iteration == null");
final List<T> list = StreamSupport.stream(iteration.spliterator(), false) .filter(e -> !given.equals(e)) .collect(Collectors.toList()); final int size = list.size(); return size == 0? null: list.get(ThreadLocalRandom.current().nextInt(size)); }
是不是感觉很低效。如果这个时候,server 返回的信息里,告诉client 谁是 leader,那client 直接连上去就可以了是吧。
/** * @return null if the reply is null or it has * {@link NotLeaderException} or {@link LeaderNotReadyException} * otherwise return the same reply. */ RaftClientReply handleLeaderException(RaftClientRequest request, RaftClientReply reply, Consumer<RaftClientRequest> handler) { if (reply == null || reply.getException() instanceof LeaderNotReadyException) { return null; } final NotLeaderException nle = reply.getNotLeaderException(); if (nle == null) { return reply; } return handleNotLeaderException(request, nle, handler); }
RaftClientReply handleNotLeaderException(RaftClientRequest request, NotLeaderException nle, Consumer<RaftClientRequest> handler) { refreshPeers(nle.getPeers()); final RaftPeerId newLeader = nle.getSuggestedLeader() == null ? null : nle.getSuggestedLeader().getId(); handleIOException(request, nle, newLeader, handler); return null; }
我们会看到,在异常的信息中,如果能够提取出一个 suggestedLeader,这时候就会做为新的leaderId来使用,下次直接连接了。
相关阅读
MySQL: 喂,别走,听我解释一下好吗?
Java七武器系列长生剑 -- Java虚拟机的显微镜 Serviceability Agent
Java七武器系列霸王枪 -- 线程状态分析 jstack
Java七武器系列孔雀翎-- 问题诊断神器BTrace
嵌套事务、挂起事务,Spring 是怎样给事务又实现传播特性的?
怎样阅读源代码?
这里是「Tomcat那些事儿」
请留下你的足迹
我们一起「终身成长」