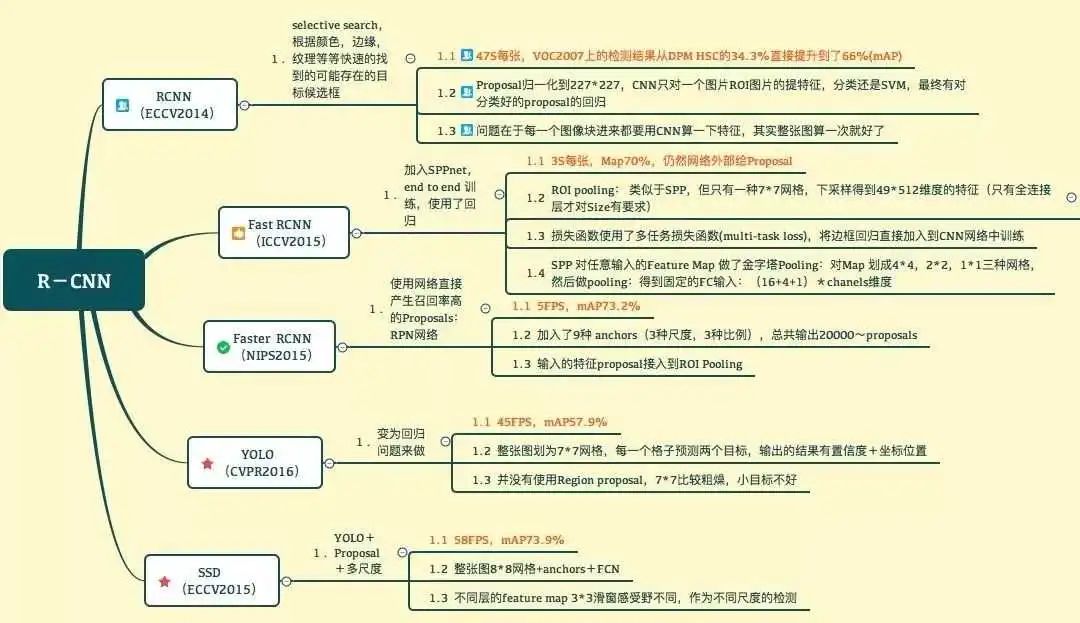
目录
0 概述
1 RCNN
1.1 候选区Region Proposal
1.2 特征提取
1.3 SVM分类
1.4 线性回归
2 SPP Net
3 Fast RCNN
4 Faster RCNN
5 总结
0 概述 本文主要讲一下深度网络时代,目标检测系列的RCNN这个分支,这个分支就是常说的two-step,候选框 + 深度学习分类 的模式:RCNN->SPP->Fast RCNN->Faster RCNN
另外一个分支是yolo v1-v4,这个分支是one-step的端到端的方式。不过这里主要是介绍RCNN那个体系的。
把下图中的yolo忽略,剩下的四个就是RCNN体系的一个非常好的总结。
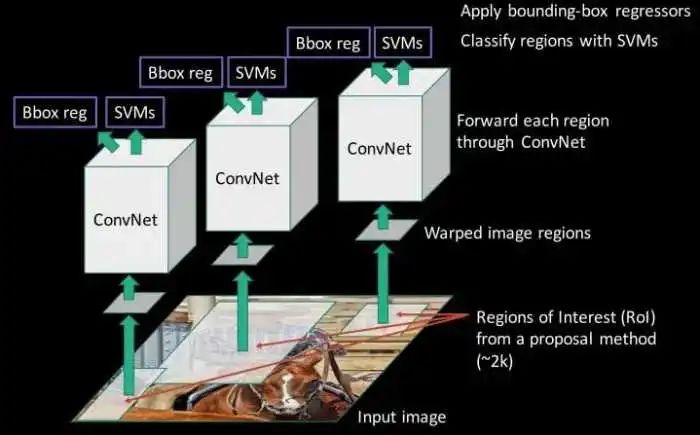
1 RCNN RCNN既然是two-step,那么就从这里切入理解:
第二步,判断每个候选区的类别 2.1 用CNN提取特征 2.2 用SVM分类 2.3 用线性回归矫正候选框的位置
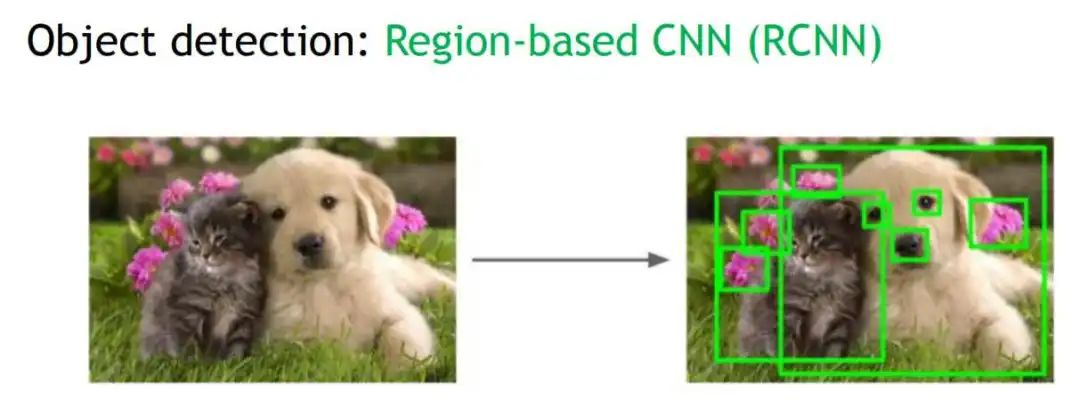
1.1 候选区Region Proposal 一个图片中有多个待检测的目标,我们怎么找到这个目标的位置呢?Region Proposal就是给出目标可能在的候选框中。如下图,Region Proposal给出了大大小小的可能候选框:
怎么给出可能的候选框呢?比较笼统的说法是:利用图像中的纹理、边缘、颜色等信息,先产生较小的相同纹理、相同颜色的候选框,然后小的候选框慢慢合并成大的纹理相似的候选框。
【selective search 选择性搜索】 这个选择性搜索 就是给出候选框的算法的名字。用Selective Search方法可以对一张图片生成大约1000~3000个候选框,具体的算法逻辑如下:
查看现有小区域,合并可能性最高的两个区域,重复直到整张图像合并成一个区域位置;;
输出所有曾经存在过的区域,也就是从小合并到大的所有出现过的大大小小的候选框,即所谓候选区域。
【合并遵守的原则】
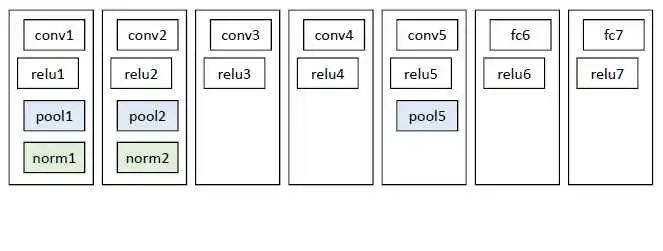
1.2 特征提取 之前选出来的大大小小的候选框,其实就是大大小小的图片。这里把图片都缩放成统一的227*227的大小 ,然后把统一大小的图片输入到CNN中,进行特征提取。这里的特征网络是一个比较简单的网络(当年resnet啊googlenet啊都没提出来,BN层也没提出来,所以结构如下)
从上图中的pool5之后的输出的特征图取出来,所以SVM的输入特征。 (这里需要提到的是,pool5在某些博客中被说成了第五个池化层,感觉不是很恰当,应该是第三个池化层,只是接在了第5个卷积层后面。)
1.3 SVM分类 众所周知,SVM只能分类二分类任务(这个不清楚的给我回去看之前的SVM推导去)。
想要SVM处理多分类任务,那么就有多种集成方式。我记得上课老师说的有两种(我只记得两种了):
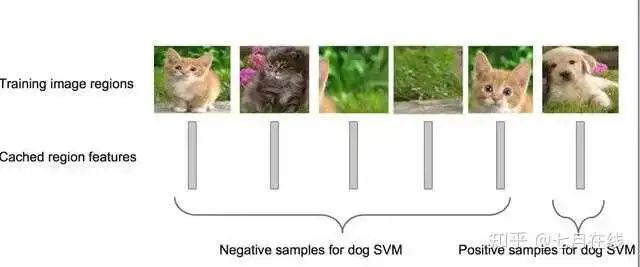
one vs one:就是假设5个类别,那么两两类别之间训练一个SVM,总共训练10个SVM,然后把一个图片放入这个10个SVN,然后对于结果进行投票;
one vs all:这个5分类任务,就训练5个SVM,然后每个SVM训练的正负样本就是:是这个类别的和不是这个类别的。淦!语言说的不清楚。
举个例子:a,b,c三个类别。one vs one就是:a|b,a|c,b|c。one vs all就是a|bc,b|ac,c|ab。(值得注意的是,在目标检测中,会多一个类别,叫做背景 )
回到RCNN,这里的SVM用的就是one vs all的方式。 下图可以比较好的理解什么是one vs all:
1.4 线性回归 现在我们知道一个候选框的类别了(通过SVM),但是我们经过一开始的拉伸,虽然让所有图片都变成了227的大小,但是也会造成图像的扭曲。如下图:
所以这时候,训练一个线性回归模型,来做一个边框回归,精细的调整候选框(x,y,w,h)四个参数。这里每一个类别就会训练一个线性回归模型 ,根据SVM的结果,选择相应类别的线性回归模型进行候选框的矫正。
整个RCNN的过程可以用下面这张图来概括一下:
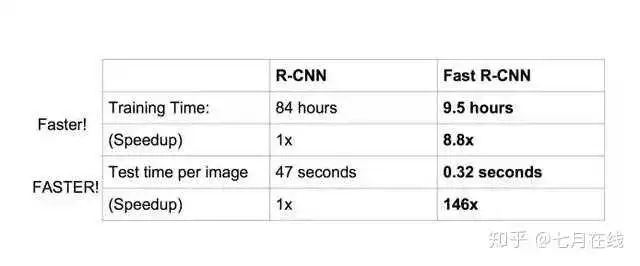
整体四个步骤,精度达到了当时水平的巅峰,但是每一张图片都会有2000左右的候选框,再加上SVM和线性回归的推理,一张图片的推理时间需要47s。慢的雅痞。之后的三个模型,都是不断改进了RCNN的各种问题,做出了各种杰出的提升。
2 SPP Net
SPP:Spatial Pyramid Pooling空间金字塔池化
SPP-Net是出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》。
众所周知,CNN一般都含有卷积部分和全连接部分,其中,卷积层不需要固定尺寸的图像,而全连接层是需要固定大小的输入(SVM的输入也是需要固定大小的输入)。
所以当全连接层面对带下不同的输入数据的时候,就需要对数据做拉伸warp或者剪裁crop,就像是RCNN中把候选框拉伸到227尺寸大小。
【crop与warp】
两者的效果看下面的图就懂了吧。
现在的问题是,warp还是crop都会让图像变形、物体不全,这样势必会对识别的精确度产生影响。
【如何避免使用warp和crop】 SPP net使用了SPP空间金字塔池化层,来实现了这个功能。先看和RCNN的模型结构对比:
RCNN中先通过warp讲大小不同的候选框变成227统一大小输入到conv layers;SPP中直接对大小不同的候选框做conv layers,所以我们得到了大小不同的特征图。然后将大小不同的特征图输入到SPP空间金字塔池化层中,输出变成大小相同的特征图
【SPP层如何实现尺寸输入不同输出相同的呢?】 ROI pooling是空间金字塔池化层的更底层的结构。准确的说,是ROI池化层实现的输入尺寸不同,输出相同的功能。 。
ROI Pooling=Region of Interest Pooling感兴趣区域池化层
ROI池化层一般跟在卷积层后面,此时网络的输入可以是任意尺度的,ROI pooling的filter会根据输入调整大小。一个简单的例子,10*10的特征图输入到ROI pooling,我们设置要一个5*5的输出,所以ROI pooling的filter大小自动计算出是2*2的。假如输入时20*20的特征图,计算出来的filter就是4*4大小的,输出结果还是5*5。
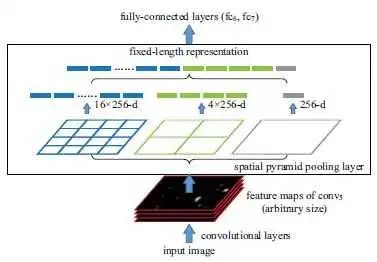
而SPP之所以称之为金字塔(希望各位了解图像金字塔的概念,不了解也没事哈),是因为它用了好几个ROI pooling,每一个ROI输出的特征图大小不同,有1*1的、2*2的、4*4的,然后把不同尺寸的特征图的特征拉平,变成21个特征变量,就可以输入到FC层或者SVM了。
下图正式重现了上面我说的情况,三个不同的ROI总共产生了21个特征进行分类。(其中的256是通道数,严格来说是21*256个特征进行分类)
【SPPnet比RCNN好在哪里?】
通过使用SPP结构(ROI池化层),避免了warp和crop的使用,避免了图像失真;
RCNN的处理顺序是:先把候选框的图扣出来,再放到卷积层进行训练得到特征图;SPPNet是先把原图通过卷积层得到特征图,然后把候选框的大小映射到特征图上再抠出来。哪个速度快不用我多说了吧。
就好比,我通知个消息,我一个一个好友的转发,与我把好友拉到一个群里,我在群里发一样 (这是个不太恰当的例子可能)。总之,这样RCNN需要卷积2000个候选框,而SPPNet只需要卷积一次,速度提升了100倍。
(最后需要提的一点是,我并不清楚SPPNet最后的分类是用FC层还是依然使用RCNN的SVM分类,不知道SPPNet是否使用了线性回归的方法做边框回归。因为我只是把SPPNet看成提出了ROI pooling的一个方法,是RCNN进化史中的一个插曲。不过在意的朋友可以自行查找,然后方便的话告诉我哈哈哈,我懒得搞了。到这里已经码字3小时了)
3 Fast RCNN SPP Net真是个好方法,R-CNN的进阶版Fast R-CNN就是在R-CNN的基础上采纳了SPP Net方法,对R-CNN作了改进,使得性能进一步提高。
【R-CNN vs Fast R-CNN】
依旧使用selective search的方法来选取候选框bounding box。
**不再使用SVM+线性回归的方法,而是全部通过神经网络来实现分类和边框回归的任务。**Fast-RCNN很重要的一个贡献是成功的让人们看到了Region Proposal + CNN这一框架的可行性,不再使用Region Proposal + CNN + SVM + LR的框架了。
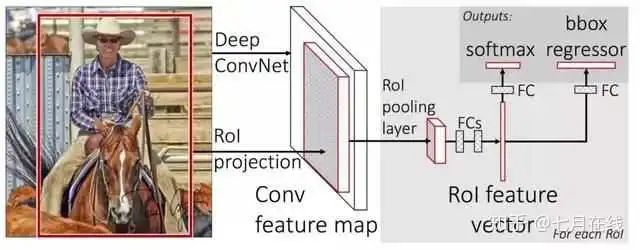
现在梳理一些Fast RCNN推理的流程。
现在有一个原图,先通过selective search得到候选框;
将原图放到CNN中进行特征处理,得到特征图,然后将候选框映射到特征图上,得到大小不同的特征图的候选框。
把特征图候选框放到ROI pooling层中(只有一个,不是SPP的3个ROI结构了),输出7*7的特征图,这时候有512个通道,所以在ROI输出之后,把7*7*512个特征放到FC层中。
FC层后接入了两个不同的FC层(分支结构),分别输出两个不同的结果。第一个结果加上softmax变成候选框的类别概率,第二个结果就是候选框的4个参数的边框回归的值。
整个流程可以看下面的图:
现在,目标检测一张图片,只需要0.32秒钟,之前的RCNN可是47秒。
【Fast RCNN的贡献】 再说一下Fast RCNN的改进,其实主要改进都是SPP Net的,用了ROI和先卷积再扣除候选框的方法(SPPNet的两个优点都用了),此外,还是用FC层直接代替了SVM和LR,这个Fast RCNN的最大贡献。
4 Faster RCNN 之前Fast RCNN最消耗时间的地方,在于使用selective search来找候选框
为了更快,使用神经网络来代替selective search,所以现在,Faster RCNN整体就是一个神经网络来搞,一个端对端的模型。(输入图片,输出候选框,一个模型完成所有任务所以是端对端)。
【区域候选网络RPN】 Faster RCNN最大的贡献在一引入了Region Proposal Network(RPN)网络来代替selective search。
RPN网络直接放在最后一个卷积层的后面,通过一个滑动窗口,在feature map上滑动。每一个滑动窗口会给出一个置信度,置信度低的可以理解为这个窗口是没有目标的,置信度高的再考虑不同类别的概率。
【Archor box先验框】 这里还会有一个archor box的概念,因为滑动窗口一般是正方形的,但是实际的目标检测可能是长方形。也许比较近似正方形的长方形可以通过边框回归矫正,但是其他的长方形物体就非常难办了。这里事先设置了几种不同形状大小的候选框,除了正方形之外,还有长方形,小正方形等,这样虽然成倍的增加了计算量,但是可以提高准确度。而且这样增加候选框的计算量消耗依然是小于selective search的。
下图来理解之前讲解的概念:
总的来说,RPN做的事情是:• 在feature map上滑动窗口 • 建一个神经网络用于物体分类+框位置的回归 • 滑动窗口的位置提供了物体的大体位置信息 • 框的回归提供了框更精确的位置
整个网络有四个损失函数:
Fast RCNN的边框回归损失函数
然后看看速度
5 总结 这里有个图来总结:
R-CNN(Selective Search + CNN + SVM)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)






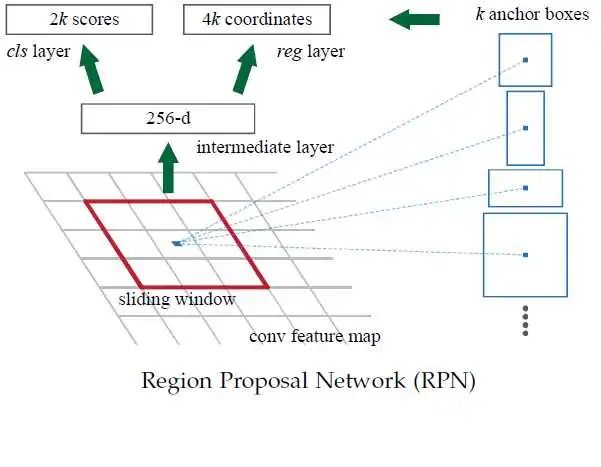 图中有四种不同的archor box,意味着滑动到某一个位置的时候,以那个点为中心,产生四个不同大小的候选框,然后预测得到 是否是目标物体二分类结果 和 边框回归四分类结果。下图会清晰的理解这个过程:
图中有四种不同的archor box,意味着滑动到某一个位置的时候,以那个点为中心,产生四个不同大小的候选框,然后预测得到 是否是目标物体二分类结果 和 边框回归四分类结果。下图会清晰的理解这个过程: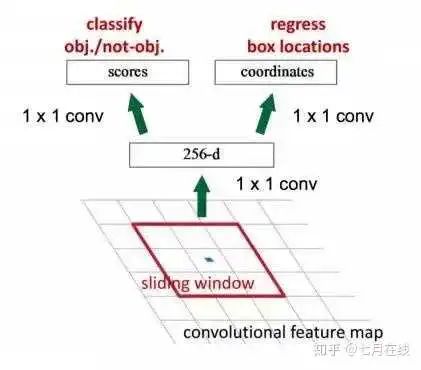
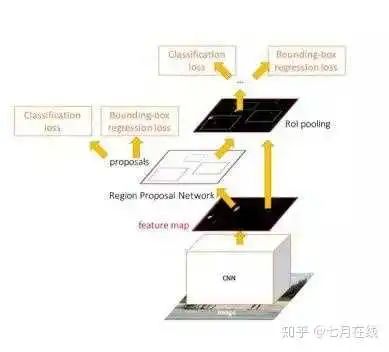
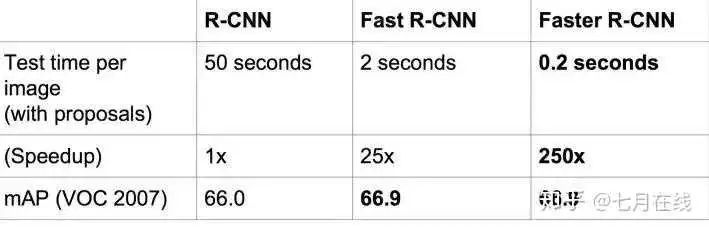 比Fast RCNN更快了。Faster R-CNN的主要贡献就是设计了提取候选区域的网络RPN,代替了费时的选择性搜索Selective Search,使得检测速度大幅提高。
比Fast RCNN更快了。Faster R-CNN的主要贡献就是设计了提取候选区域的网络RPN,代替了费时的选择性搜索Selective Search,使得检测速度大幅提高。



