![file]()
前言
本篇文章收录于专辑:http://dwz.win/HjK
你好,我是彤哥,一个每天爬二十六层楼还不忘读源码的硬核男人。
大家都知道,数据结构与算法解决的主要问题就是“快”和“省”的问题,即如何让代码运行得更快, 如何让代码更节省存储空间。
所以,“快”和“省”是衡量一个算法非常重要的两项指标,也就是我们经常听到的时间复杂度和空间复杂度分析。
那么,为什么需要复杂度分析呢?复杂度分析的方法论是什么呢?
这就是我们本节要解决的问题。
好了,进入今天的学习吧。
为什么需要复杂度分析?
首先,我们来思考一个问题:对于两个算法,我们如何评判谁运行得更快,谁运行时更节省内存?
你可能会说,这还不简单,把这两个算法运行一遍,统计下运行时间和占用内存不就可以了吗?
没错,这确实是一种不错的方法,而且它还有个非常形象的名字:事后统计法。
但是,这种统计方法具有非常明显的问题:
-
不同的输入对结果影响很大
对于一些输入,可能算法A执行得更快;对于另外一些输入,可能算法B执行得更快。比如,我们后面要学习的排序算法,输入的有序性对于不同的排序算法的影响是完全不同的。
-
不同的机器对结果影响很大
对于同样的输入,可能在一台机器上算法A更快,而在另外一台机器上算法B更快。比如,算法A可以利用多核而算法B不能,那么CPU的核数对这两个算法的影响将截然不同。
-
数据规模对结果影响很大
当数据规模小时,可能算法A更快,而数据规模变大时,可能算法B更快。比如,我们后面要学习的排序算法,当数据规模比较小时,插入排序反而比归并排序更快。
所以,我们需要一种可以不用实际运行算法,就可以估计算法执行效率的方法。
这也就是我们所说的复杂度分析。
那么,怎么进行复杂度分析呢?有没有什么方法论呢?
还真有,这个方法论叫作渐近分析法。
什么是渐近分析法?
渐近分析法,是指将算法执行的效率与输入的规模进行挂钩,随着输入规模的增大,算法执行所需要的时间(或空间)将呈现一种什么样的趋势,这种趋势就叫作渐近,而这种方法就叫作渐近分析法。
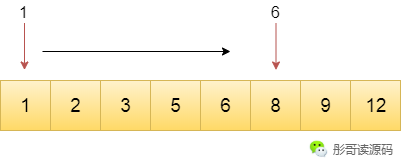
概念可能比较拗口,我举个简单的例子,对于给定的一个有序数组,我要查找其中某个值所在的位置,比如,查找8这个元素,有哪些方法呢?
![file]()
简单暴力点的方法,从头遍历,查找到该元素即返回。
![file]()
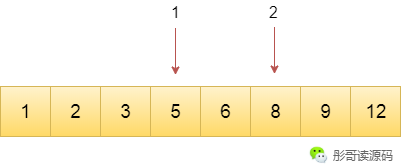
更友好一点的方法,采用二分法,每次定位到数据的中间位置,看其值与目标值的大小,判断是在左边还是右边继续以二分的方式查找。
![file]()
上面我们举的例子的输入规模是8个元素的有序数组,目标值为8,使用第二种方法明显比第一种方法要快很多。
但是,如果查找的目标是1呢?
对于第一种方法,查找一次足矣。
对于第二种方法,需要查找3次。
此时,第二种方法又次于第一种方法了。
所以,比较两个算法的执行效率,不能只考虑到个别元素,而应该顾及到所有元素的感受。
我们以数学的方法来统计两种方法的平均执行效率,假设输入规模扩展到n。
对于第一种方法,1号元素查找一次,2号元素查找两次,3号元素查找三次……,而查找每个元素的概率都是1/n。
所以,它的执行效率为:1x1/n + 2x1/n + 3x1/n + ... nx1/n = nx(n+1)/2/n = (n+1)/2。
对于第二种方法,中间的元素有一个,查找一次,次中间的元素有两个,查找两次,次次中间的元素有四个,查找三次...,每次查找的规模都缩小一半,而查找每个元素的概率都是1/n。
所以,它的执行效率为:1x1x1/n + 2x2x1/n + 4x3x1/n + ... + 2^(log2(n)-2) x (log2(n)-1) x 1/n+ 2^(log2(n)-1) x log2(n) x 1/n = ?
我了个去,这个结果等于多少?
是时候展现真正的实力了:
![file]()
你可能要骂娘了,对于我一个小学毕业的,难道我没办法学习数据结构与算法了?
No,No,No,肯定不能这么玩,那么,应该怎么玩呢?我们下一节接着讲。
后记
本节,我们从算法执行效率方面阐述了为什么需要复杂度分析,并介绍了复杂度分析的方法,即渐近分析法,如果严格地遵循渐近分析法,需要大量的数学知识,这无疑增加了我们分析算法的难度,那么,有没有什么更省心地计算复杂度的方法呢?
关注公众号“彤哥读源码”,解锁更多源码、基础、架构知识!