使用方法 SharedPreferences // 1:获得SharedPreferences,这是直接包含在Context中的方式,直接调用即可 // 四种写入模式:MODE_PRIVATE、MODE_APPEND、MODE_WORLD_READABLE、MODE_WORLD_WRITEABLE val sp = baseContext.getSharedPreferences("clericyi" , Context.MODE_PRIVATE)// 2:获取笔,因为第一步获得到相当于一张白纸,需要对应的笔才能对其操作 val editor = sp.edit()// 3:数据操作,不过我们当前操作的数据只是一个副本 // putString()、putInt()。。。还有很多方法 "is_wirte" , true )// 4:两种提交方式,将副本内的数据正式写入实体文件中 // 同步写入 // 异步写入 MMKV 第一步:开源库导入
implementation 'com.tencent:mmkv-static:1.1.2'第二步:使用
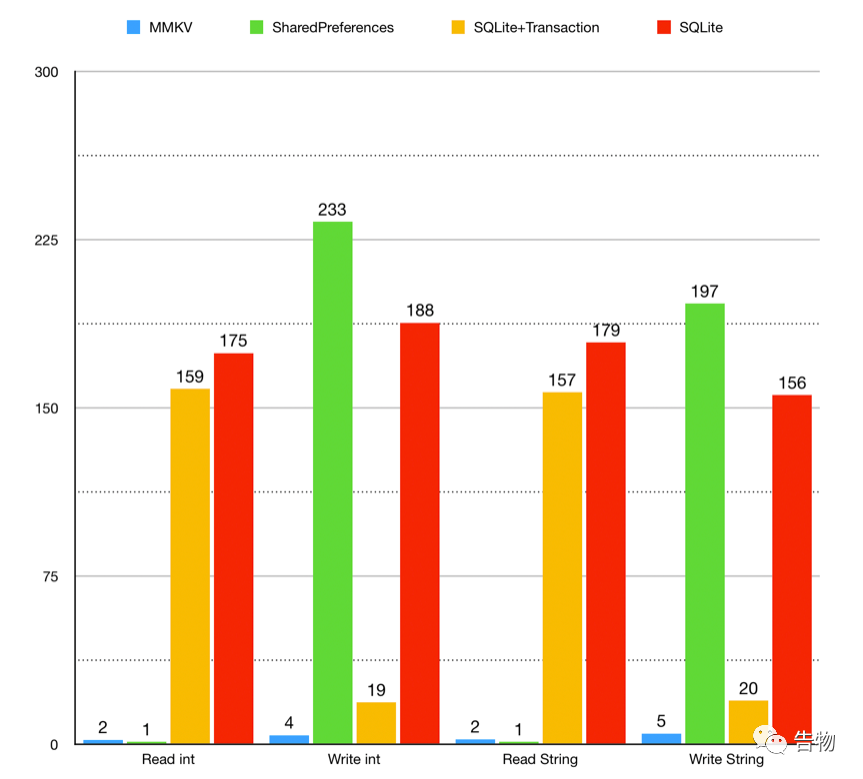
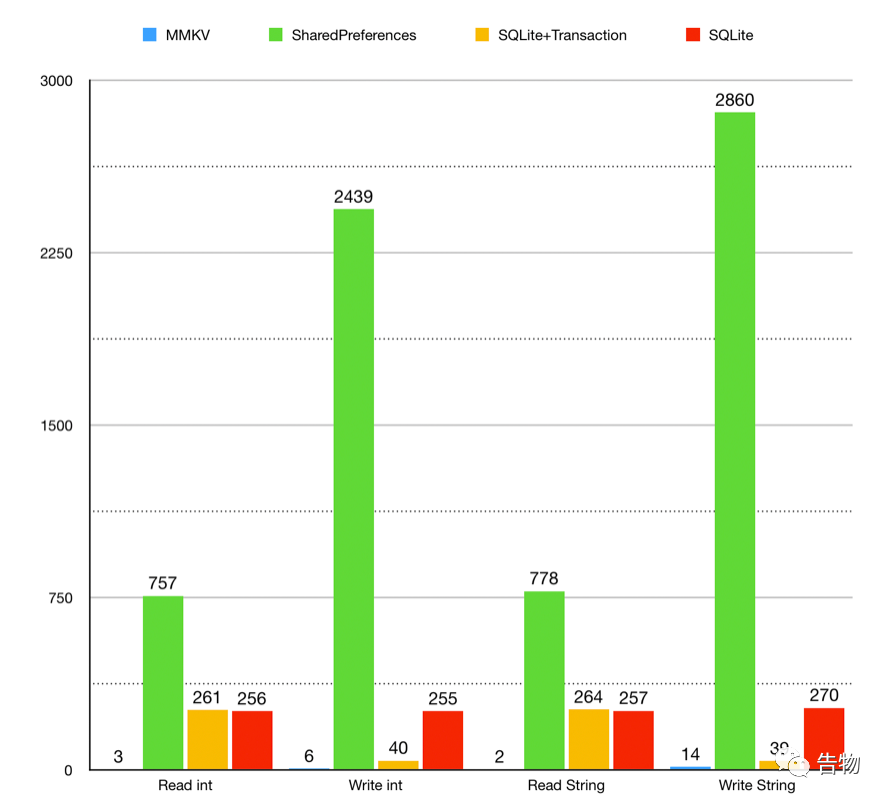
// 1. 自定义Aapplication public void onCreate () super .onCreate();this );// 2. 调度使用 // 和SharedPreferenced一样,支持的数据类型直接往里面塞即可 // 不一样的地方,MMKV不需要自己去做一些apply()或者是commit()的操作,更加方便 "bool" , true );boolean bValue = kv.decodeBool("bool" );为什么这篇文章要拿两个框架讲? 单进程性能
多进程性能
不论是单线程还是多线程,MMKV的读写能力都远远的甩开了SharedPreferences&SQLite&SQLite+Transacion,但是MMKV到底是如何做到如此快的进行读写操作的?这就是下面会通过源码分析完成的事情了。
另外接下来的一句话仅代表了我的个人意见,也是为什么我只写SharedPreferences和MMKV两者比较的原因,因为我个人认为SQLite和他们不太属于同一类产品,所以比较的意义上来说就趋于普通。
SharedPreferences源码分析 根据上述中所提及过的使用代码,能够比较清楚的知道第一步的分析对象就是getSharedPreferences()的获取操作了,但是如果你直接点进去搜这个方法,是不是会出现这样的结果呢?
public abstract SharedPreferences getSharedPreferences (String name, @PreferencesMode int mode) 没错了,只是一个抽象方法,那显然现在最重要的事情就是找到他的具体实现类是什么了,当然你可以直接查阅资料获取,最后的正确答案就是ContextImpl,不知道你有没有找对呢?
public SharedPreferences getSharedPreferences (File file, int mode) synchronized (ContextImpl.class ) {final ArrayMap<File, SharedPreferencesImpl> cache = getSharedPreferencesCacheLocked();if (sp == null ) {// ..... // 通过具体实现类,对SharedPreferences进行创建 new SharedPreferencesImpl(file, mode);// 通过一个cache来防止同一个文件的SharedPreferences的重复创建 return sp;if ((mode & Context.MODE_MULTI_PROCESS) != 0 ||// 如果开启了多进程模式,一旦数据发生更新,那么其他进程的数据会通过重载的方式更新 // 这里是否存在疑问,为什么网上会说这个方法是一个进程不安全的方案呢? return sp;在上面的使用过程中提到了,其他他是一个副本的概念,这个从何说起呢?显然这就要看一下SharedPreferences的实现类具体是如何进行操作的了,从他的构造函数看起,慢慢进入深度调用。
SharedPreferencesImpl(File file, int mode) {false ;null ;null ;// 开始从磁盘中调数据 // 1 --> // 1 --> private void startLoadFromDisk () // 开启一条新的线程来加载数据 new Thread("SharedPreferencesImpl-load" ) {public void run () // 2--> // 2 --> private void loadFromDisk () null ;null ;null ;// 从XML中把数据读出来,并把数据转化成Map类型 // 这是一个非常消耗时间的操作 if (mFile.canRead()) {null ;new BufferedInputStream(new FileInputStream(mFile), 16 * 1024 );synchronized (mLock) {true ;if (thrown == null ) {// 文件里拿到的数据为空就重建,存在就赋值 if (map != null ) {// 将数据存储放置到具体类的一个全局变量中 // 稍微记一下这个关键点 else {new HashMap<>();到此为止就基本完成了SharedPreferences的构建流程,而为了能够对数据进行操作,那就需要去获取一只笔,来进行操作,同样的这段代码最后会在SharedPreferencesImpl中进行具体实现。
public Editor edit () synchronized (mLock) {// 很简单的一个操作,就是创建了一支笔 // 这里是一个很重要的点,因为每次都是新创建一支笔,所以要做到数据更换的操作要一次性完成。 return new EditorImpl();因为后面的操作都是与这只笔相关,而且具体操作上重复度比较高,所以只选取一个putString()来进行分析。
public final class EditorImpl implements Editor private final Map<String, Object> mModified = new HashMap<>();public Editor putString (String key, @Nullable String value) synchronized (mEditorLock) {return this ;很简单的解决思路,就是新创建一个了HashMap里面全部保存的都是一些我们已经做过修改的数据,之后的更新是需要用到这些数据的。
相较于之前的那些源码,这里的就显得非常轻松了,结合上述的源码分析,可以假设SharedPreferences氛围三个要点。
apply()/commit(): 猜测最后就是上述两者数据的合并,再进行数据提交。
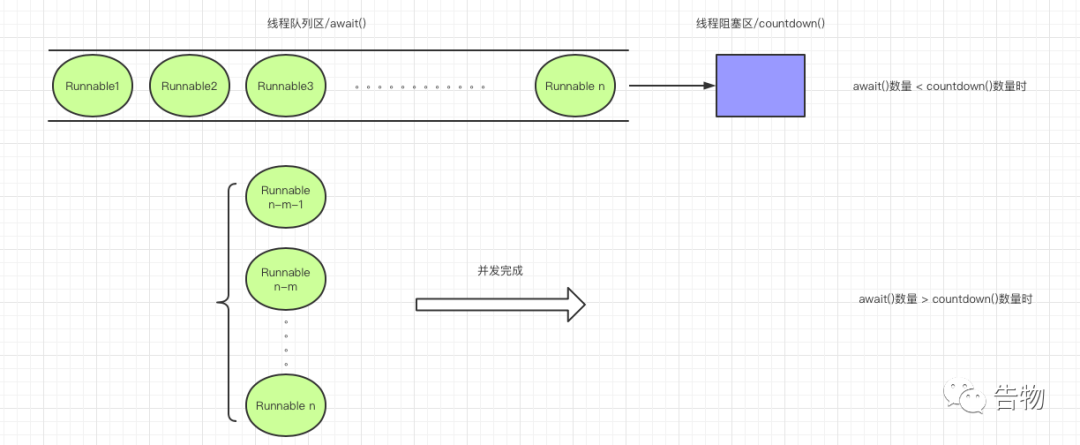
数据提交 异步提交 / apply() public void apply () // ..... // 这一步其实就是我们所猜测的第三步中的数据合并 // 做一个简单的介绍,数据的替换一共分为三步: // 1. 将数据存储到mapToWriteToDisk中 // 2. 与mModified中数据进行比较,不存在或者不一致就替换 // 3. 将更新后得数据返回 final MemoryCommitResult mcr = commitToMemory();// 通过CountDownLatch来完成数据的同步更新 final Runnable awaitCommit = new Runnable() {@Override public void run () // 1--> // 对事件完成的监听 new Runnable() {@Override public void run () // 通过线程进行异步处理 // 如果任务完成,就从队列中清除 this .enqueueDiskWrite(mcr, postWriteRunnable); // 2 --> // 通知观察者数据更新 从上述的代码中可以了解到apply()的通过创建一个线程来进行处理,之后会讲到commit()和他的处理方式不同的地方。现在具体的目光还是要聚焦在如何完成数据到磁盘的提交的,也就是注释1 处的具体实现到底是如何?这就是对这个类的一个理解问题了。其实他有点类似于程序计数器,在阻塞数量大于线程数时,会阻塞运行,而超出数量就会出现并发状况。
第二个地方就是注释2 ,他线程做了一个入队列的操作。
private void enqueueDiskWrite (final MemoryCommitResult mcr,final Runnable postWriteRunnable) final boolean isFromSyncCommit = (postWriteRunnable == null );final Runnable writeToDiskRunnable = new Runnable() {@Override public void run () synchronized (mWritingToDiskLock) {// commit()同样会进入到这个大方法中 // commit()方法执行到这里运行完就结束,干的事情就是将数据写入文件 if (isFromSyncCommit) {return ;// apply()多做了层如队列的操作,意图在于异步进行 // 3--> // 3 --> // 因为最后使用的都是其实都是MSG_RUN的参数,所以直接调用查看即可 public static void queue (Runnable work, boolean shouldDelay) synchronized (sLock) {if (shouldDelay && sCanDelay) {// 4--> else {// 4--> // 4 --> public void handleMessage (Message msg) if (msg.what == MSG_RUN) {// 5 --> // 5 --> // 就是最后将一个个任务进行完成运行 private static void processPendingWork () synchronized (sProcessingWork) {// 。。。。。 if (work.size() > 0 ) {for (Runnable w : work) {// 最后将数据一个个进行运行完成操作 同步提交 / commit() public boolean commit () // 不需要使用线程来进行异步处理,所以第二参数为空 this .enqueueDiskWrite(null /* sync write on this thread okay */ );return mcr.writeToDiskResult;所以说基本逻辑上其实还是和apply()方法是一致的,只是去除了异步处理的步骤,所以就是常说的同步处理方式。
总结
是什么限制了SharedPreferences的处理速度?
这个问题在上面的源码分析中其实已经有所提及了,那就是文件读写,所以如何加快文件的读写速度是一个至关重要的突破点。当然向速度妥协的一个方案,想来你也已经看到了,那就是异步提交,通过子线程的在用户无感知的情况下把数据写到文件中。
多线程安全安全想来是一个非常容易解释的事情了,干一个很简单的事情就是synchronized的加锁操作,对数据的操作进行加锁那势必拿到的最后数据就会是一个安全的数据了。
但是对于多进程呢? 你可能会说在sp.startReloadIfChangedUnexpectedly();这段代码出现的难道不是已经涉及了多进程的安全操作吗?yep!! 如果你想到了这点,说明你有好好看了下代码,但是没有看他的实现,如果你去看他的实现方案,就会发现MODE_MULTI_PROCESS和所可以使用的操作的运算结果均为0,所以在现在的Android版本中这是一个被抛弃的方案。当然这是其一,自然还有另外一个判断就是关于版本方面,如果小于HONEYCOMB同样可以进入这个方案,但是需要注意getSharedPreferences()是只有获取时才会出现的,而SharedPreferences是对于单进程而言的单独实例,数据的备份全部在单个进程完成,所以在进行多进程读写时,发生错误是大概率的。
MMKV源码分析 初始化 / MMKV.initialize(this); 在MMKV的整套流程中,MMKV的初始化起着承上启下的作用。
public static String initialize (Context context) // 获取根路径 "/mmkv" ;return initialize(root, (MMKV.LibLoader)null , logLevel); // 进行加载 1 --> // 1 --> public static String initialize (String rootDir, MMKV.LibLoader loader, MMKVLogLevel logLevel) // 加载必要的so文件 // 。。。。。 // 通过JNI来对底层c的实现进行初始化调度 return rootDir;因为到这里的话直接通过三方库的导入已经不能满足查看了,所以直接去下载MMKV的开源库源码查看比较合适。
如果你并不太熟悉JNI的方法调度,也没关系,我会慢慢的通过方式来教你入门。
你能够发现是爆红的JNI方法,那如何定位呢? 摁两下Shift的全局搜索,然后直接输入initializeMMKV,就会得到搜索结果了。
能够发现这里存在两个方法,进去看看就知道像C写的,那目标群体就已经被你锁定了。
void MMKV::initializeMMKV (const MMKVPath_t &rootDir, MMKVLogLevel logLevel) // ThreadOnce说明初始化过程只会进行一次 // 对目标路径进行设置,层级递推如果不存在就创建。 对象实例获取 / MMKV.defaultMMKV() public static MMKV defaultMMKV () // 可以设置为多进程模式 // 重点所在 long handle = getDefaultMMKV(SINGLE_PROCESS_MODE, null ); // *** --> return new MMKV(handle); // 1 --> // 1 --> // 就是一个为long类型的handle变量设置 private MMKV (long handle) 你能看到***注释位置是代码中一个迷惑性行为,通过数据类型定义能够知道最后得到的数据是一个数据类型为long的数据,我们可以猜测这个数据的用处对应着最后能够用于寻找到对应的MMKV,通过深层次调用后可以发现他调用了一个mmkvWithID()的方法,其中DEFAULT_MMAP_ID为mmkv.default。
MMKV *MMKV::mmkvWithID (const string &mmapID, int size, MMKVMode mode, string *cryptKey, string *relativePath) {// 。。。。。。 auto mmapKey = mmapedKVKey(mmapID, relativePath); // 1 --> auto itr = g_instanceDic->find(mmapKey);if (itr != g_instanceDic->end()) {// 2 --> return kv;if (relativePath) {if (!isFileExist(*relativePath)) {if (!mkPath(*relativePath)) {return nullptr ;auto kv = new MMKV(mmapID, size, mode, cryptKey, relativePath); // 3 --> return kv;在这个代码中总共有两个核心部分:
mmapKey的值的计算: 通过
mmapID和
relativePath两个值进行一定的运算操作,具体关系就是
mmapID和
relativePath的重合关系,具体还是要见于代码实现。
MMKV的生成: 这里的解释对应
注释2和
注释3,就是通过一个
Map的形式来对数据进行存储,如果在
g_instanceDic这个变量中进行数据查询。
MMKV的内部结构 MMKV::MMKV(const string &mmapID, int size, MMKVMode mode, string *cryptKey, string *relativePath)// historically Android mistakenly use mmapKey as mmapID // 1 --> nullptr )nullptr )new MemoryFile(m_path, size, (mode & MMKV_ASHMEM) ? MMFILE_TYPE_ASHMEM : MMFILE_TYPE_FILE))new MemoryFile(m_crcPath, DEFAULT_MMAP_SIZE, m_file->m_fileType))new MMKVMetaInfo())nullptr )new ThreadLock())new FileLock(m_metaFile->getFd(), (mode & MMKV_ASHMEM)))new InterProcessLock(m_fileLock, SharedLockType))new InterProcessLock(m_fileLock, ExclusiveLockType))0 || (mode & CONTEXT_MODE_MULTI_PROCESS) != 0 ) {0 ;nullptr ;if (cryptKey && cryptKey->length() > 0 ) {new MMKVMapCrypt();new AESCrypt(cryptKey->data(), cryptKey->length());else {new MMKVMap();// 。。。。。。一些赋值操作 // sensitive zone 和SharedPreferences相同最后还是需要经历一场和文件读写的殊死搏斗,那问题就来了,同样是文件读写,为什么MMKV能够以百倍的速度碾压各类已成熟的产品呢?从我的思路出发可以分为这样的几种情况:
不够健壮的错误数据处理。 这如果你做一个简易版的
FastJson就能够发现,数据的处理速度基本上能够有非常高的提升。但是这对于相对成熟的产品而言一般不会有这种方案。
底层进行数据处理。 这个方案的推行在一定程度上也是对应现在的两者对比有一定的道理,因为能够发现
MMKV的实现方案基本都是依靠
JNI来调度完成,而
C的处理速度和
Java相比想来我们也是有目共睹的。
更优化的文件读取方案。 这就是对当前方案的分析了,因为还没有看到后面的代码,所以这里是一种方案的猜测。因为
SharedPreferences和
MMKV两者都是我们有目共睹需要对数据进行读写操作的,而数据的最后来源就是本地的文件,一个更易于读写的文件方案势必是一个最关键的突破点。
回归正题:loadFromFile();
在刚刚的猜想中,我提及了关于文件读写的问题,因为对MMKV而言,文件读写这一关肯定是躲不过去的,但是如何更高效就是我们应该去思考的点了。
void MMKV::loadFromFile() {// 文件不合法就重新加载 if (!m_file->isFileValid()) {// 文件依旧不合法就报错 if (!m_file->isFileValid()) {"file [%s] not valid" , m_path.c_str());else {// 进入这一步至少说明文件是合法的,但是需要进行数据的校验 // error checking false , needFullWriteback = false ;// loading if (loadFromFile && m_actualSize > 0 ) {MMBuffer inputBuffer (ptr + Fixed32Size, m_actualSize, MMBufferNoCopy) ;if (m_crypter) {else {// 1 --> if (needFullWriteback) {if (m_crypter) {// 2 --> else {// 2 --> else {// 1 --> if (m_crypter) {// 2 --> else {// 2 --> new CodedOutputData(ptr + Fixed32Size, m_file->getFileSize() - Fixed32Size);// 计算出数据量的实际大小 if (needFullWriteback) {else {// 如果数据是不合法或者空的就直接丢弃。 // 。。。。。。 false ;在代码段中我标注出了注释1和注释2,也是我认为至关重要的代码了,分别做了两大操作:
数据的写回方案制作: 这是要一个非常有特色的地方,为什么这么说呢?其实你能够从一个判断的变量名能够看出会对数据的写回方式有一个选择,也就是部分写回和全部写回的策略之选,那这就是第一个原因为什么
MMKV的综合性能能够强过
SharedPreferences。
文件格式的选择: 其实这是解析时候的事情了,这一段的论证来源于
MMKV 原理
[1] ,
protobuf作为
MMKV最后的选择方案在性能和空间占用上都有不错的表现。
数据更新 / kv.encodeXXX("string", XXX); 这里的代码分析只拿一个作为样例即可
MMKV_JNI jboolean encodeBool (JNIEnv *env, jobject, jlong handle, jstring oKey, jboolean value) {// 1--> if (kv && oKey) {// 将key再进行特殊的加工处理 return (jboolean) kv->set((bool) value, key); // 2 --> return (jboolean) false ;关注几个注释点:
注释1: 这就是之前在上面的时候已经提到过的在
Java这一层中进行的操作只是一个数据类型为
long的
handle变量进行赋值操作,而这个
handle中在后期可以被解析转化为已经初始化完成的
MMKV对象。
注释2: 完成相对应的数据放置操作,那这里就要观察代码的深层调度是一个怎么样的过程了。
bool MMKV::set(bool value, MMKVKey_t key) {// 1. 进行数据的测量,并创建相同大小的区间 MMBuffer data (size) ;// 2. 转化为CodedOutputData对象用于写入 CodedOutputData output (data.getPtr() , size) ;// 3 --> // 从名字就能知道这其实是一个正式的数据替换操作 // 追溯后可以发现会出现一个文件的写入。 return setDataForKey(move(data), key); // 3--> void CodedOutputData::writeBool(bool value) {// 用0和1来表示最后的数值 this ->writeRawByte(static_cast<uint8_t>(value ? 1 : 0 ));但是通过官方的文档中能够知道,关于这个文件格式下的数据是存在问题的,那就是他并不支持增量更新 ,这也就意味着复杂的操作会更加多了,那腾讯的解决方案是什么呢?
标准 protobuf 不提供增量更新的能力,每次写入都必须全量写入。考虑到主要使用场景是频繁地进行写入更新,我们需要有增量更新的能力:将增量 kv 对象序列化后,直接 append 到内存末尾;这样同一个 key 会有新旧若干份数据,最新的数据在最后;那么只需在程序启动第一次打开 mmkv 时,不断用后读入的 value 替换之前的值,就可以保证数据是最新有效的。
一句话讲来就是,新的或更改过的就最后新增后面插入。
而新旧数据累加势必会造成文件的庞大,那这方面MMKV给出的解决方案又是怎么样的呢?
以内存 pagesize 为单位申请空间,在空间用尽之前都是 append 模式;当 append 到文件末尾时,进行文件重整、key 排重,尝试序列化保存排重结果;排重后空间还是不够用的话,将文件扩大一倍,直到空间足够。
同样的换成一句话来进行描述,有上限目标的文件重写。
这一段的代码实现就不贴出了,具体位置就在MMKV_IO中的ensureMemorySize()方法,通过已存在数据大小的总量来进行整理,因为很多时候数据量很大是因为大容量的数据的重复添加造成的。
数据获取 / kv.decodeXXX("string"); MMKV_JNI jboolean decodeBool (JNIEnv *env, jobject, jlong handle, jstring oKey, jboolean defaultValue) {if (kv && oKey) {return (jboolean) kv->getBool(key, defaultValue);return defaultValue;其实基本逻辑和写文件的差不多了,这个时候还是首先要获取一个对应的MMKV对象,然后完成数据的获取。
bool MMKV::getBool(MMKVKey_t key, bool defaultValue) {if (data.length() > 0 ) {CodedInputData input (data.getPtr() , data.length () ) ;return input.readBool();return defaultValue;转化为CodedInputData的对象来完成数据的读取,如果数据不存在,那就直接默认值返回。
删除对应的数据 / kv.removeValueForKey("string") 在看代码之前做一个思考,在已知的数据基础上,换成你会怎么做这样的操作呢?
我们要关注的点有以下几个:
protobuf是一个不支持增量更新的文件格式,相对应
MMKV给出的解决方案就是通过尾部增加,出现新旧数据叠加
从
问题1的引申,新旧数据叠加的一个查询和删除问题,因为新旧数据,那么做查询的时候势必要多次的查,如果每次的数据都有
1G,那你的查询每次都要叠加到
1G的程度,而不是查到即可开始删除。
对于以上问题思考清楚了的话,我们就可以给出MMKV的解决方案了。
auto itr = m_dic->find(key);if (itr != m_dic->end()) {false ;static MMBuffer nan; // ****** auto ret = appendDataWithKey(nan, itr->second); // ****** if (ret.first) {#ifdef MMKV_APPLE #endif return ret.first;将关注点全部放置于注释带*的代码段上,一个没有赋值的MMBuffer说明数据为空,然后直接调用appendDataWithKey()文件写入的方案,说明最后出现在protobuf的数据样式会是这样的。
message empty{其实就是往里面加一个新的空数据作为新的数据。
总结 从源码分析完之后,和SharedPreferences相比,重新整理后可以总结为以下几点的突破:
mmap的使用:SharedPreferences
数据的更新方式: 局部更新的数据,通过尾部追加来进行完成,而不是像
SharedPreferences一样的直接文件重构。同样要注意这样的方式会造成冗余数据的增加。
多进程访问安全的设计: 详细见于
MMKV for Android 多进程设计与实现
[2] ,主要还是以
mmap作为突破口,来完成对其他进程对当前文件的操作的一个状态感知,主要就是分为三方面:
写指针增长、内存重整、内存增长 。
参考资料
参考资料
[1] MMKV 原理: https://github.com/Tencent/MMKV/wiki/design#mmkv-原理
[2] MMKV for Android 多进程设计与实现: https://github.com/Tencent/MMKV/wiki/android_ipc
[3] MMKV官方文档: https://github.com/Tencent/MMKV/wiki
 你能够发现是爆红的
你能够发现是爆红的
