如果内存空间即将用完,Ignite可以水平扩展以存储应用和服务生成的更多数据,这是Ignite的基础功能之一,因此增加资源是最简单的处理方法。但是实际上多数情况都无法立即扩展集群,通常都是为应用配置了固定内存容量的Ignite集群,增加更多资源可能是一项艰巨而持续的工作。
下面会介绍几种功能,这样即使在内存成为稀缺资源的情况下也可以保持集群的稳定运行。
配置Ignite退出策略以避免内存不足问题
数据退出是防止内存过度使用的经典机制,它通过监控正在使用的内存空间并在内存占用超过阈值时删除多余的数据,从而避免内存不足的问题。
Ignite支持多种退出策略,这些策略最终会在达到最大数据区大小时从内存中清除最近最少使用的页面,下面的代码片段显示了如何为自定义数据区启用DataPageEvictionMode.RANDOM_2_LRU策略:
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
DataRegionConfiguration regionCfg = new DataRegionConfiguration();
regionCfg.setName("20GB_Region");
// 500 MB initial region size (RAM).
regionCfg.setInitialSize(500L * 1024 * 1024);
// 20 GB maximum region size (RAM).
regionCfg.setMaxSize(20L * 1024 * 1024 * 1024);
// Enabling RANDOM_2_LRU eviction for this region.
regionCfg.setPageEvictionMode(DataPageEvictionMode.RANDOM_2_LRU);
可以为纯内存集群以及将数据保存在外部数据库(例如Oracle或MySQL)中的集群配置退出策略,开启Ignite原生持久化的集群会忽略退出策略的配置,而是使用页面替换算法来控制内存空间的使用。
如果将Ignite退出策略用作内存不足场景的预防措施,则只有在以下情况下,Ignite才会自动恢复退出的数据:a)通过CacheStore接口连接的外部数据库具有该数据的副本,b)应用使用Ignite的键-值API读取数据,其他情况开发者都需要自行进行数据的重新加载。
使用Ignite的原生持久化读取仅在磁盘上的数据
Ignite的多层存储可以将原生持久化配置为磁盘层。启用原生持久化后,它会将所有数据包括索引存储在磁盘上,然后开发者可以决定在内存中缓存多少数据。即使数据不在内存中,应用也可以访问仅仅保存在磁盘上的数据。
原生持久化的配置很简单,将DataRegionConfiguration.persistenceEnabled属性配置为true时,Ignite就会在磁盘上保存与该数据区有关的所有数据:
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
DataRegionConfiguration regionCfg = new DataRegionConfiguration();
regionCfg.setName("20GB_Region");
// 500 MB initial region size (RAM).
regionCfg.setInitialSize(500L * 1024 * 1024);
// 20 GB maximum region size (RAM).
regionCfg.setMaxSize(20L * 1024 * 1024 * 1024);
// Enable Ignite Native Persistence for all the data from this data region.
regionCfg.setPersistenceEnabled(true);
因为持久化是在数据区上配置的,因此只需为可能会溢出的缓存和表设置持久化即可。通常来说,应为所有数据区打开持久化,然后决定是否为一个或多个数据子集关闭持久化。
凭借原生持久化,Ignite不会对集群进行API限制。相反,如果在内存中找不到记录,则所有Ignite API(包括SQL和ScanQueries)都可以从磁盘查找记录。此功能消除了应用由于退出而需要重新加载数据的负担,而且Ignite通过页面替换还可以避免内存空间过度消耗。尽管该算法会自动从内存中删除记录,但它不会触及磁盘上的副本,只要应用需要,就可以将其拉回到内存层。
使用更大的堆和无暂停的垃圾收集器来消除Java堆的问题
Ignite将所有数据包括索引都存储在堆外内存中,该内存通常称为页面内存(由于其组织和管理方式)。Ignite像现代操作系统一样,将空间分成固定大小的页面,并将数据保存在这些页面中。如前所述,如果有可能耗尽堆外内存,则可以使用退出策略和原生持久化。
同时,与任何Java中间件一样,Ignite使用Java堆作为应用请求的对象和数据的临时存储。例如,当通过键-值或SQL调用检索数据时,所请求的堆外数据的副本将在Java堆中维护,并在将基于堆的结果集传输到应用端后进行垃圾回收。
如果开始用完Java堆空间,那么JVM很可能不会生成导致集群节点故障的内存溢出异常,而是会在集群节点上观察到长时间的垃圾回收暂停。暂停会影响集群的性能,并可能导致未响应的节点故障。
解决此问题的常规方法是分配一个足够大的Java堆,以在生产负载下处理应用的所有请求。堆大小是场景相关的,每个集群节点可以小至3GB或大至30GB。
高吞吐量和低延迟的应用通常需要更大的Java堆。对于此类应用,也可以考虑使用不暂停的Java垃圾收集器,例如Azul Zing JVM的C4,无论堆大小如何,该垃圾收集器均显示可靠且一致的性能结果。
通过SQL的内存配额使Java堆使用情况可预测
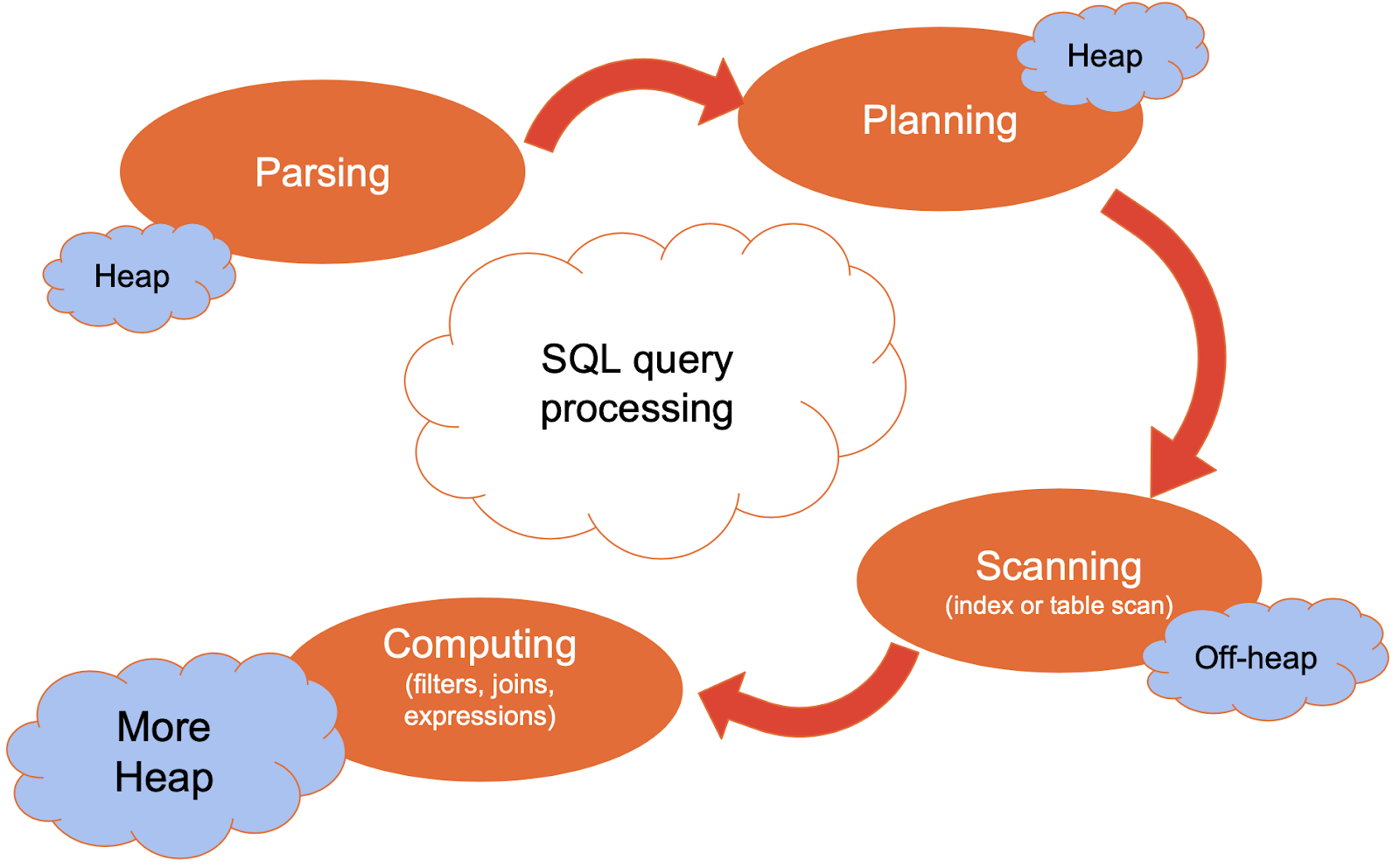
SQL查询是Ignite中最消耗Java堆的操作之一。单个查询可以扫描成千上万个表记录,对内存中的数百个记录进行分组和排序,以及关联保存在多个表中的数据。下图显示了查询执行过程的所有步骤,计算阶段使用Java堆最多: ![]()
通常来说,在许多Ignite环境中,最终Java堆大小受基于SQL的操作的需求影响,上一节中关于更大的Java堆的建议适用于SQL。但是也可以配置内存配额以更好地管理Java堆空间的使用。
内存配额专为SQL设计,可在GridGain社区版和GridGain的其他版本中使用,以下配置示例显示了如何为每个集群节点设置配额:
// Creating Ignite configuration.
IgniteConfiguration cfg = new IgniteConfiguration();
// Defining SQL configuration.
SqlConfiguration sqlCfg = new SqlConfiguration();
// Setting the global quota per cluster node.
// All the running SQL queries combined cannot use more memory as set here.
sqlCfg.setSqlGlobalMemoryQuota("500M");
// Setting per query quota per cluster node.
// A single running SQL query cannot use more memory as set below.
sqlCfg.setSqlQueryMemoryQuota("40MB");
// If any of the quotas is exceeded, Ignite will start offloading result sets to disk.
sqlCfg.setSqlOffloadingEnabled(true);
cfg.setSqlConfiguration(sqlCfg);
使用此配置,单个Ignite集群节点可以使用不超过500MB的堆空间来满足正在运行的SQL查询的需求。另外,SqlConfiguration.setSqlQueryMemoryQuota指定Ignite不允许任何单独的SQL查询消耗超过40MB的堆。最后,如果超出了每个查询或全局配额,则Ignite开始将查询的结果集卸载到磁盘层(如启用SqlConfiguration.setSqlOffloadingEnabled参数,则和任何关系数据库一样),如果禁用了磁盘卸载功能,则超过配额的查询将终止,并抛出异常。
因此,建议使用磁盘卸载功能来启用配额,尤其是在应用要对数据执行排序(SORT BY)或分组(DISTINCT,GROUP BY)或使用子查询或者关联运行复杂查询时。
总结
本文讨论的所有技术点都可以解决内存过度消耗的问题,但是要注意,这些功能一旦触发,就会影响应用的性能。集群会更积极地使用磁盘(原生持久化进行页面替换,以及将SQL结果集卸载到磁盘上),或者通过从集群中删除记录来使记录不可用(退出策略)。