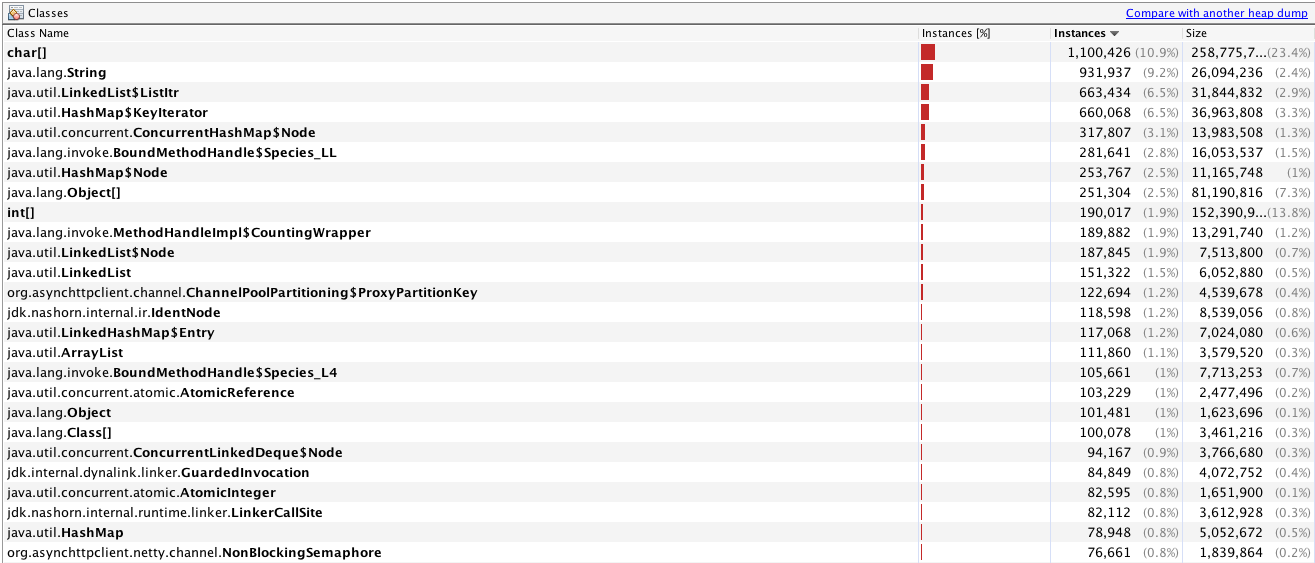
 。
。 。
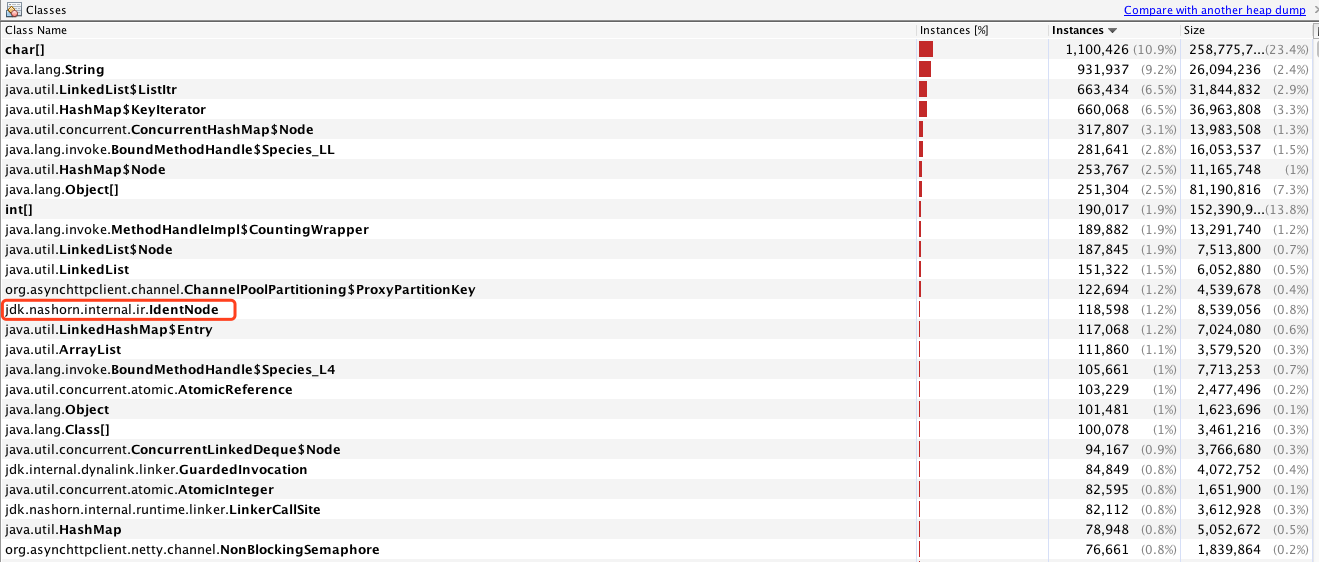
。
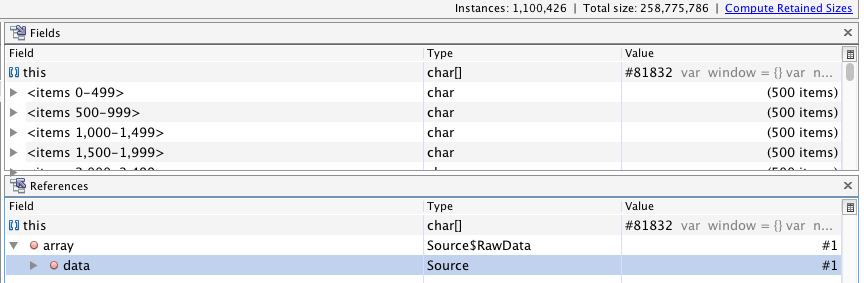
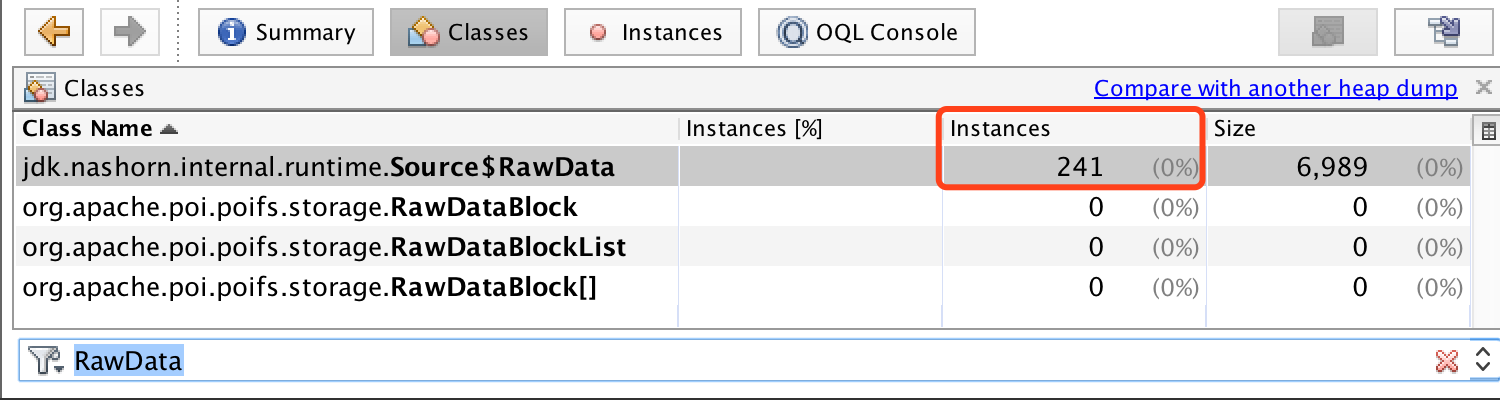 ,这241个,然后找了出现频率比较高的几个js脚本,然后看了对应脚本的调用方式,发现其中一个脚本每次执行都是通过
,这241个,然后找了出现频率比较高的几个js脚本,然后看了对应脚本的调用方式,发现其中一个脚本每次执行都是通过
 年轻代总容量才300多m(S0C+S1C+EC),而年老大总容量(OC)有3700多m,这种情况就直接导致了,直接分配对象空间的eden区域很容易就占满了,而直接触发ygc,而导致这个问题的原因呢,是忘记配置
年轻代总容量才300多m(S0C+S1C+EC),而年老大总容量(OC)有3700多m,这种情况就直接导致了,直接分配对象空间的eden区域很容易就占满了,而直接触发ygc,而导致这个问题的原因呢,是忘记配置

第1届全球学生开源年会 sosconf 将于 2019年8月在美国南加州大学举行
学生开源年会:Students Open Source Conference(简称 sosconf),是首个由学生组织、面向学生的非盈利全球性开源技术峰会。sosconf 2019 将于 8 月下旬在美国南加州大学举行。 2019年3月18日讯,美国洛杉矶 学生开源年会组委会今天正式宣布,第1届全球学生开源年会 sosconf 2019 将于今年8月在美国南加州大学举行,这是继去年第0届学生开源年会成功召开后,该会议第一次在美国举办。 学生开源年会(sosconf )是首个由学生组织面向学生的非盈利社区全球性开源技术峰会,峰会基于开放源代码的理念,鼓励学生享受开源、了解开源、参与开源、贡献开源,并能从开源中得到实践和乐趣。峰会每年在不同国家不同城市举办,从演讲者、组织者、志愿者到听众,绝大多数为在校学生,包括中学生、大学生硕士研究生和博士研究生,其中演讲者和志愿者仅限学生身份报名,听众不做任何限制。 南加州大学(University of Southern California ),简称南加大,位于加州洛杉矶市中心,由监理会于1880年创立,是加州最古老的私立研究型大学,亦是全球顶尖的...