![]()
还记得3月份的时候我给大家介绍了PaddleDetection的环境部署、训练及可视化、模型导出。但那只是一个算法程序,一个完整的项目需要在算法的基础上将可视化操作开发成型。今天我给大家带来如何利用Py-Qt编一个显示界面,并结合工业相机实时采集并进行目标检测。
下载安装命令
## CPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle
## GPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
本文用到的软件有PyQt5、Pycharm、Hikvision工业相机。
本文内容如下:
1、在Pycharm下搭建pyqt环境
2、介绍通过飞桨进行模型保存和模型加载
3、如何利用飞桨检测单帧图像
4、PyQt5效果展示
Pycharm下搭建PyQt5的环境
该过程见此链接https://zhuanlan.zhihu.com/p/110224202,作者将飞桨和PyQt5安装在了同一个虚拟环境下面。
通过飞桨保存模型和加载模型
介绍模型的保存和加载,目的是更好地了解飞桨预测过程。本文主要介绍模型保存函数:fluid.io.save_params;fluid.io.save_inference_model和模型加载函数 ;fluid.io.save_params ;fluid.io.load_inference_model。
1. 模型的保存
1)fluid.io.save_params
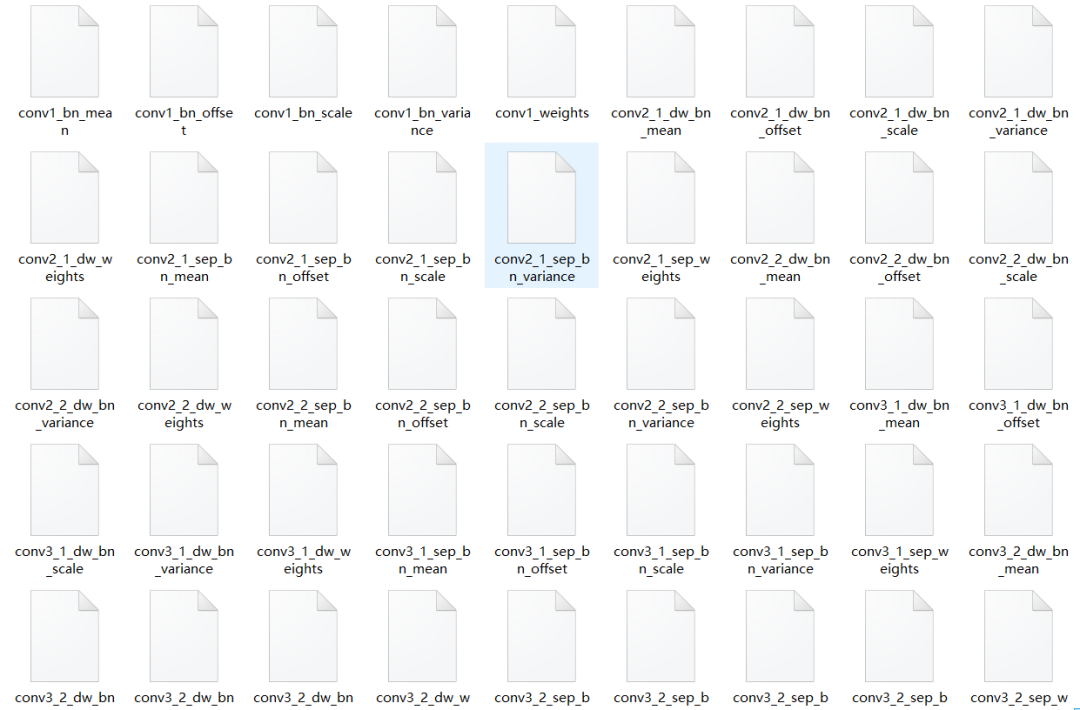
fluid.io.save_params:从字面意思来理解,表示保存参数。而该函数的主要目的也确实是保存训练过程中生成的各个节点之间的参数(权重、偏置等),使用fluid.io.save_params进行模型的保存,其保存的内容如下图所示:
![]()
2)fluid.io.save_inference_model
fluid.io.save_inference_model:从字面上理解,表示保存可进行后续预测的模型。而该函数的主要目的也确实是保存可进行预测的模型。即调用save_inference_model函数,可在save_params所保存的参数基础上融合网络结构生成的可进行预测的模型。这一点类似于tensorflow将训练出来的ckpt文件固化成pb文件。从我们git中下载的PaddleDetection代码,在PaddleDetection-release/tools/export_model中就是利用save_inference_model导出结合后的模型。
利用export_model.py保存下来的文件如下所示:生成了两个文件,__model__和__params__文件,其中__model__表示网络结构,__params__表示训过程产生的参数。
![]()
2. 模型的加载
1) fluid.io.load_params
fluid.io.load_params:根据上文得知,该函数表示加载训练过程中的参数进行预测,如果要加载参数进行预测,则需要将网络结构也加载进来,PaddleDetection给出的官方预测示例就是利用该方式进行预测。
2) fluid.io.load_inference_model
fluid.io.load_inference_model:根据上文得知,该函数表示加载参数和网络结构的融合体进行预测。作者在如下的内容中就是使用该方式进行预测。
3. 备注
1) 备注一
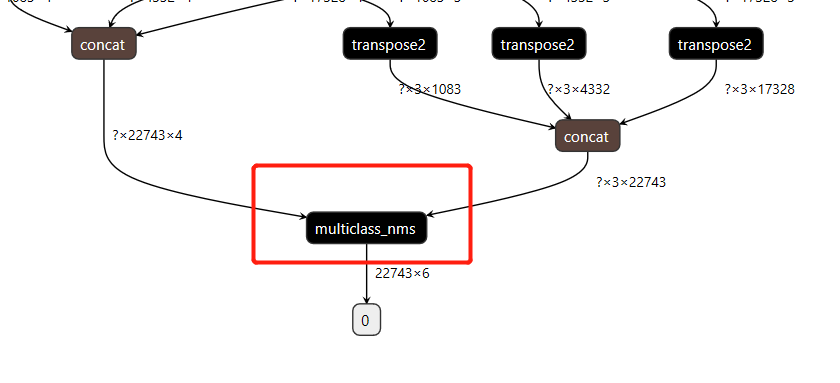
前面生成的模型文件中,__model__文件包含了NMS部分(这一点和tensorflow的pb文件不同,pb文件是没有NMS节点的)。关于__model__文件,我们可以使用Netron进行展开。Netron使用地址https://lutzroeder.github.io/netron/。打开以后可看到网络结构,在最下端发现有NMS节点。
![]()
2) 备注二
除了上述谈到的模型加载和保存的方式,还有另外一组即fluid.io.save_persistables和fluid.io.load_persistables。
如何利用飞桨进行预测?
PaddleDetection里面已经有了相应的预测代码infer.py,该代码利用paddle的reader机制进行图像的预测,同时该代码使用的加载模型的方式是fluid.io.load_params。作者个人为了能配合后续在qt下运行检测,使用fluid.io.load_inference_model作为模型的加载方式,从paddle的AI Studio上截取一部分代码重新构造了预测代码。本段预测代码加载的模型是yolov3(主干网络MobileNet)训练出来的模型。
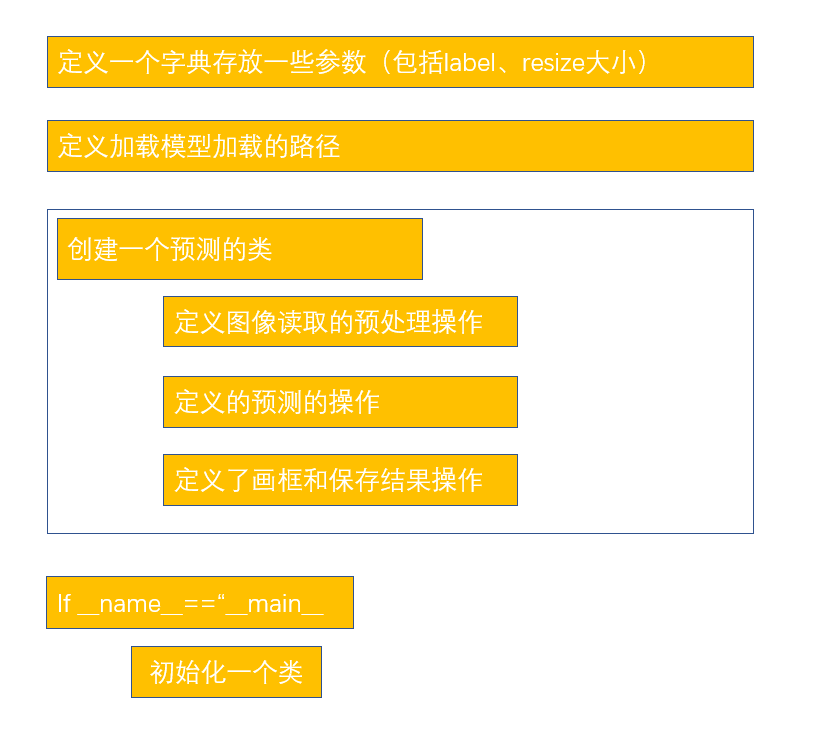
作者构造自身的预测代码思路如下图所示:
![]()
代码如下:
说明:
1. 该代码由于使用参数和网络结构融合的模型,因此对于其他库的依赖比较少,只需要将飞桨导入即可,
2. 该代码由于使用的模型文件是《__model__和__params__》,因此在使用load_inference__model时候,必须在该函数的参数中指明这两个名字。
![]()
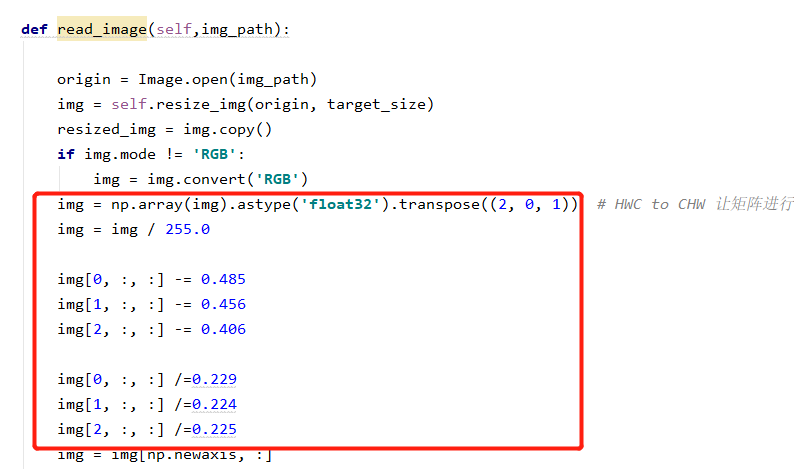
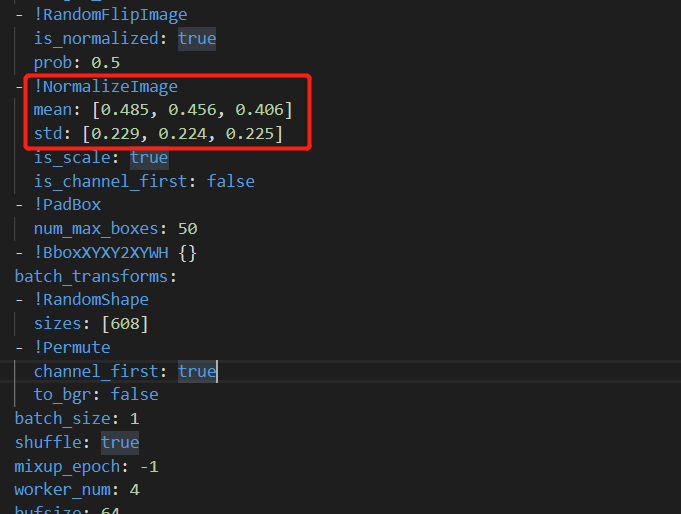
3. 该代码中需要着重注意一下一点:由于预测加载的模型是使用yolov3训练出来的模型,因此在进行预测时要考虑图像归一化的操作,数据归一化的操作来源训练该模型的config文件,输入图像大小需要和export model时设置的图像大小保持一致
![]()
![]()
iimport numpy as np
import time
import paddle.fluid as fluid
from PIL import Image
from PIL import ImageDraw
train_parameters = {
"label_dict": {0:"apple",1:"banana",2:"orange"},
"use_gpu": True,
"input_size": [3, 608, 608], # 原版的边长大小为608,为了提高训练速度和预测速度,此处压缩为448
}
target_size = train_parameters['input_size']
anchors = train_parameters['anchors']
anchor_mask = train_parameters['anchor_mask']
label_dict = train_parameters['label_dict']
print(label_dict[1])
# class_dim = train_parameters['class_dim']
# print("label_dict:{} class dim:{}".format(label_dict, class_dim))
place = fluid.CUDAPlace(0) if train_parameters['use_gpu'] else fluid.CPUPlace()
exe = fluid.Executor(place)
path="C:\\Users\\zhili\\Desktop\\2"#_mobilenet_v1
[inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(dirname=path, executor=exe,model_filename='__model__', params_filename='__params__')
class inference():
def __init__(self):
print("8888888888")
def draw_bbox_image(self,img, boxes, labels,scores, save_name):
"""
给图片画上外接矩形框
:param img:
:param boxes:
:param save_name:
:param labels
:return:
"""
draw = ImageDraw.Draw(img)
for box, label,score in zip(boxes, labels,scores):
print(box, label, score)
if(score >0.9):
xmin, ymin, xmax, ymax = box[0], box[1], box[2], box[3]
draw.rectangle((xmin, ymin, xmax, ymax), 3, 'red')
draw.text((xmin, ymin), label_dict[label], (255, 255, 0))
img.save(save_name)
def resize_img(self,img, target_size):#将图片resize到target_size
"""
保持比例的缩放图片
:param img:
:param target_size:
:return:
"""
img = img.resize(target_size[1:], Image.BILINEAR)
return img
def read_image(self,img_path):
origin = Image.open(img_path)
img = self.resize_img(origin, target_size)
resized_img = img.copy()
if img.mode != 'RGB':
img = img.convert('RGB')
img = np.array(img).astype('float32').transpose((2, 0, 1)) # HWC to CHW 让矩阵进行方向的转置
img = img / 255.0
img[0, :, :] -= 0.485
img[1, :, :] -= 0.456
img[2, :, :] -= 0.406
img[0, :, :] /=0.229
img[1, :, :] /=0.224
img[2, :, :] /=0.225
img = img[np.newaxis, :]
return origin, img, resized_img
def infer(self,image_path):
"""
预测,将结果保存到一副新的图片中
:param image_path:
:return:
"""
origin, tensor_img, resized_img = self.read_image(image_path)
input_w, input_h = origin.size[0], origin.size[1]
image_shape = np.array([input_h, input_w], dtype='int32')
t1 = time.time()
batch_outputs = exe.run(inference_program,
feed={feed_target_names[0]: tensor_img,
feed_target_names[1]: image_shape[np.newaxis, :]},备注:此时送入网络进行预测的图像大小是原图的尺寸大小。 fetch_list=fetch_targets,
return_numpy=False)
period = time.time() - t1
print("predict cost time:{0}".format("%2.2f sec" % period))
bboxes = np.array(batch_outputs[0])
if bboxes.shape[1] != 6:
print("No object found in {}".format(image_path))
return
labels = bboxes[:, 0].astype('int32')
scores = bboxes[:, 1].astype('float32')
boxes = bboxes[:, 2:].astype('float32')
last_dot_index = image_path.rfind('.')
out_path = image_path[:last_dot_index]
out_path += '-result.jpg'
self.draw_bbox_image(origin, boxes, labels,scores, out_path)
if __name__ == '__main__':
image_path= "C:\\Users\\zhili\\Desktop\\123\\2.jpg"
a=inference()
a.infer(image_path)
PyQt5检测效果
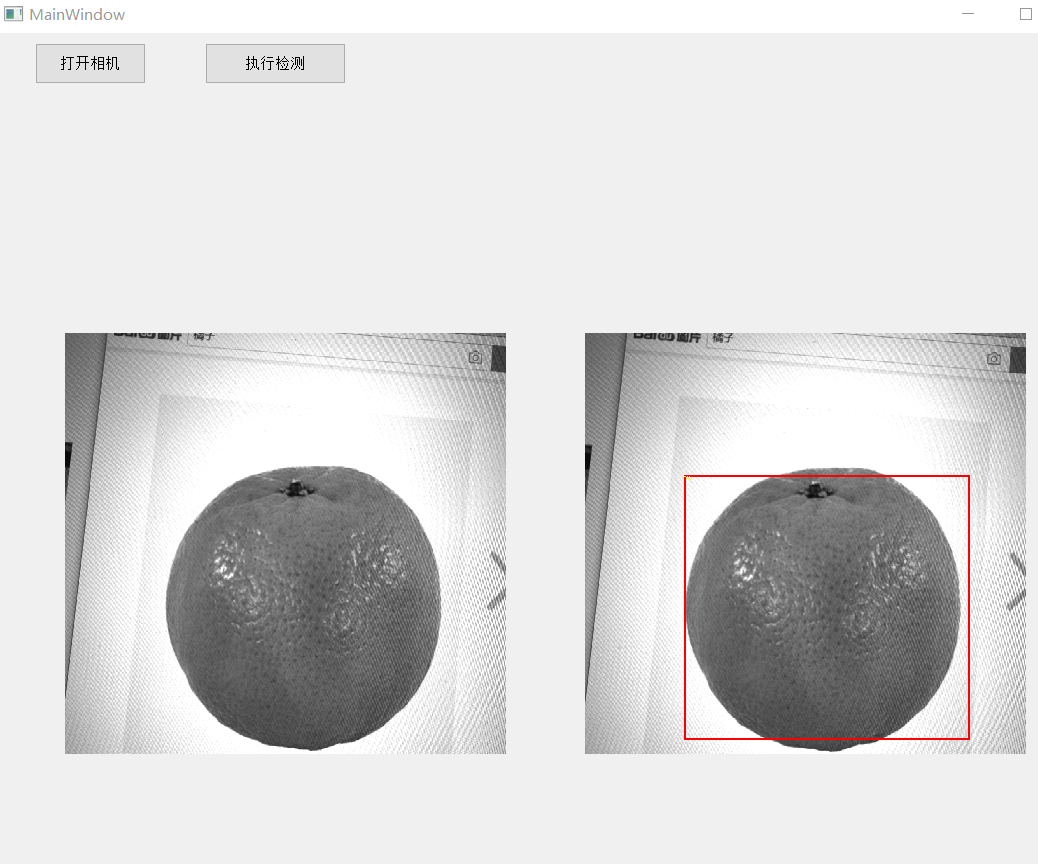
1. 首先通过步骤1配置好的PyQt中QT Designer,创建两个Button对象,分别为“打开相机”、“开始检测”,然后创建两个Label对象,分别用于显示相机原图和显示检测后图像。
2. 创建多线程检测机制,分别给两个Button设置不同的槽函数,分别用于触发相机拍照和调用检测函数。运行infe_video.py可得到如下结果。由于作者使用的是黑白相机拍摄电脑屏幕上百度搜索出来的橘子照片,检测效果质量不高。
![]()
特别说明:该文章受到了高松鹤同学和百度飞桨团队的大力支持,表示感谢。
该项目Github地址:
https://github.com/yzl19940819/Paddle_infer_python
如果您加入官方QQ群,您将遇上大批志同道合的深度学习同学。官方QQ群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
下载安装命令
## CPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle
## GPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
官网地址:https://www.paddlepaddle.org.cn
飞桨开源框架项目地址:
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle