![]()
前言
![]()
随着最近关注 cim 项目的人越发增多,导致提的问题以及 Bug 也在增加,在修复问题的过程中难免代码洁癖又上来了。
看着一两年前写的东西总是怀疑这真的是出自自己手里嘛?有些地方实在忍不住了便开始了漫漫重构之路。
前后对比
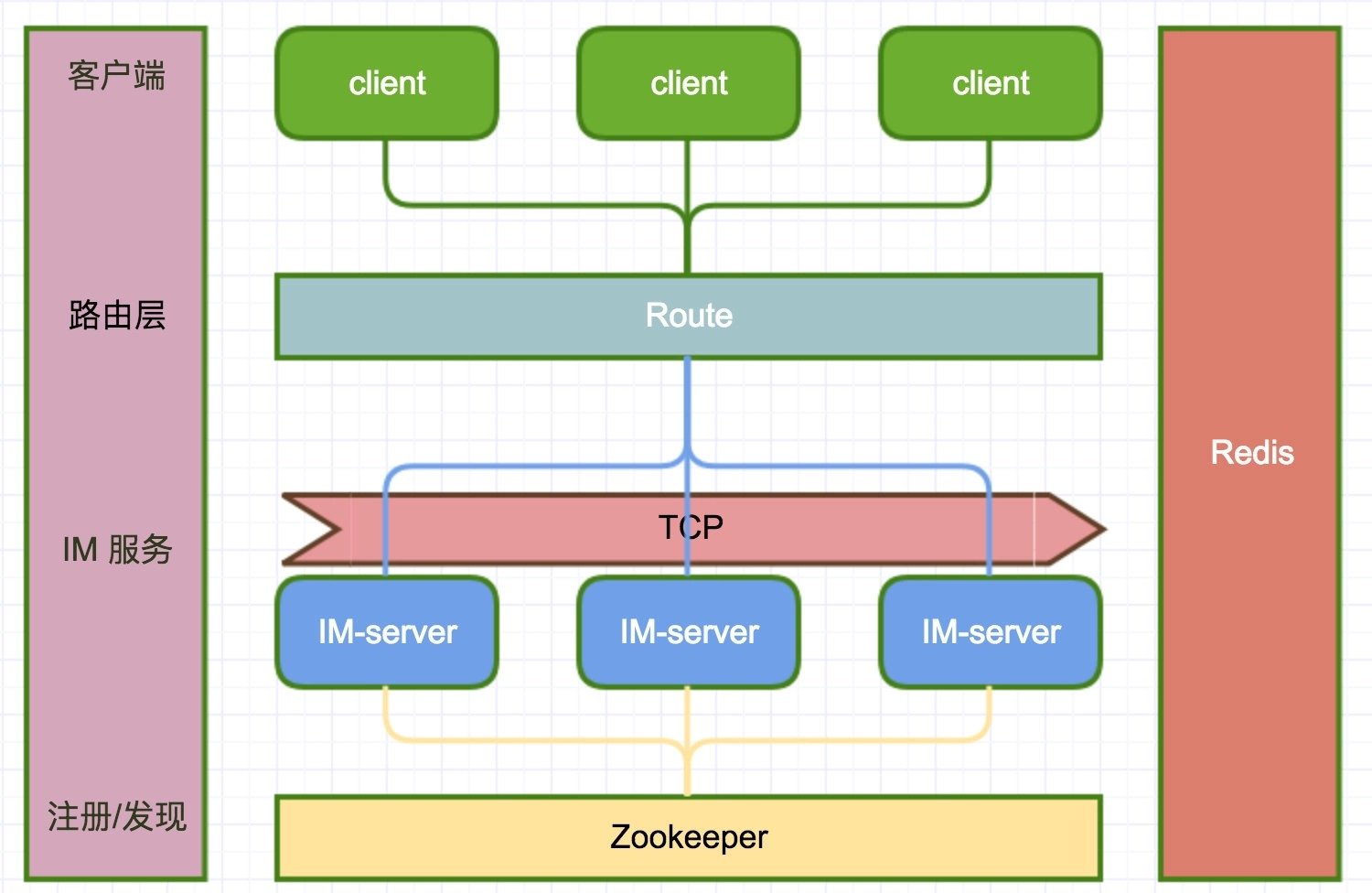
在开始之前先简单介绍一下 cim 这个项目,下面是它的架构图: ![]()
简单来说就是一个 IM 即时通讯系统,主要有以下部分组成:
IM-server 自然就是服务端了,用于和客户端保持长连接。IM-client 客户端,可以简单认为是类似于的 QQ 这样的客户端工具;当然功能肯定没那么丰富,只提供了一些简单消息发送、接收的功能。Route 路由服务,主要用于客户端鉴权、消息的转发等;提供一些 http 接口,可以用于查看系统状态、在线人数等功能。
当然服务端、路由都可以水平扩展。
![]()
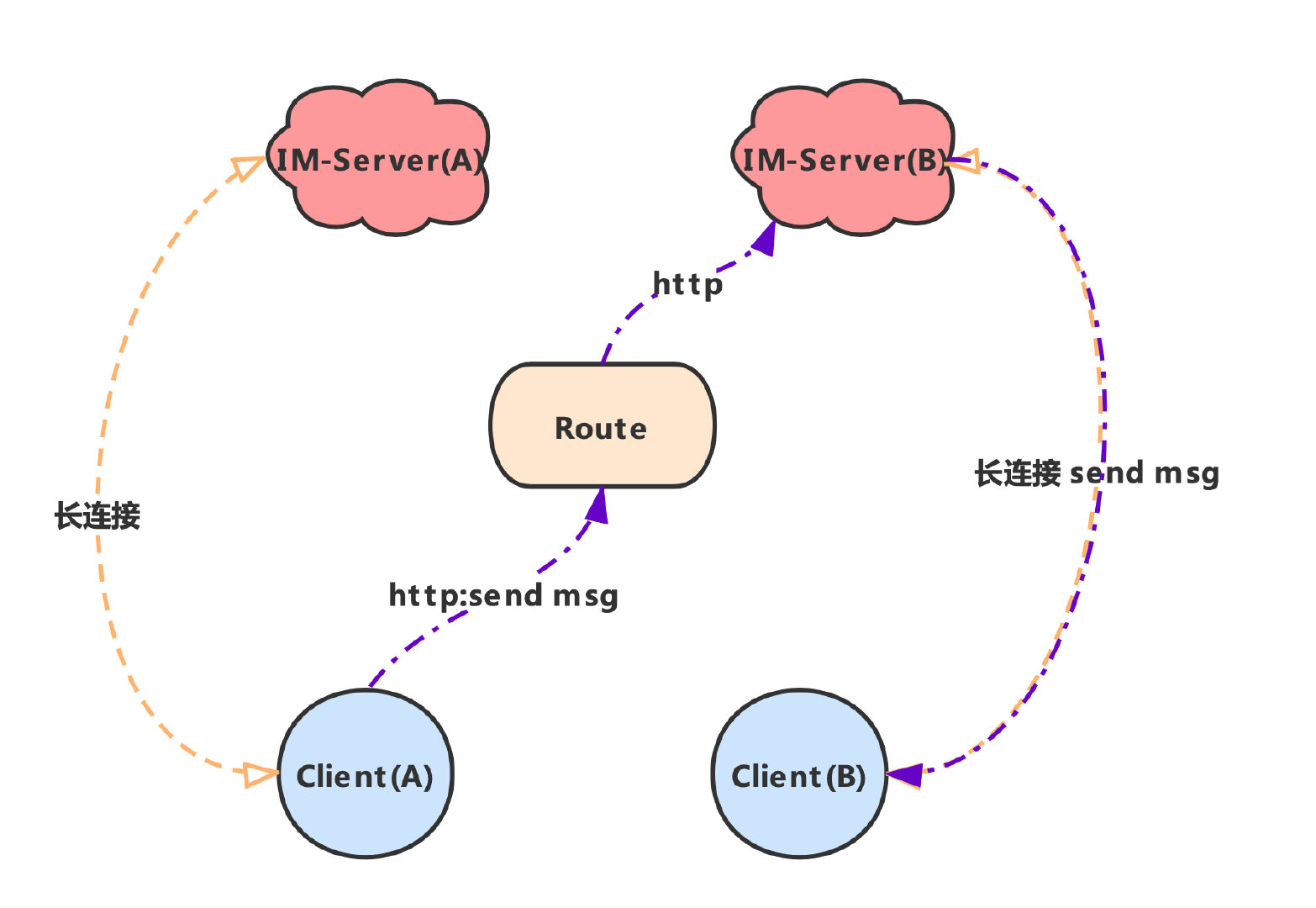
这是一个消息发送的流程图,假设现在部署了两个服务端 A、B 和一个路由服务;其中 ClientA 和 ClientB 分别和服务端 A、B 保持了长连接。
当 ClientA 向 ClientB 发送一个 hello world 时,整个的消息流转如图所示:
- 先通过
http 将消息发送到 Route 服务。
- 路由服务得知
ClientB 是连接在 ServerB 上;于是再通过 http 将消息发送给 ServerB。
- 最终
ServerB 将消息通过与 ClientB 的长连接通道 push 下去,至此消息发送成功。
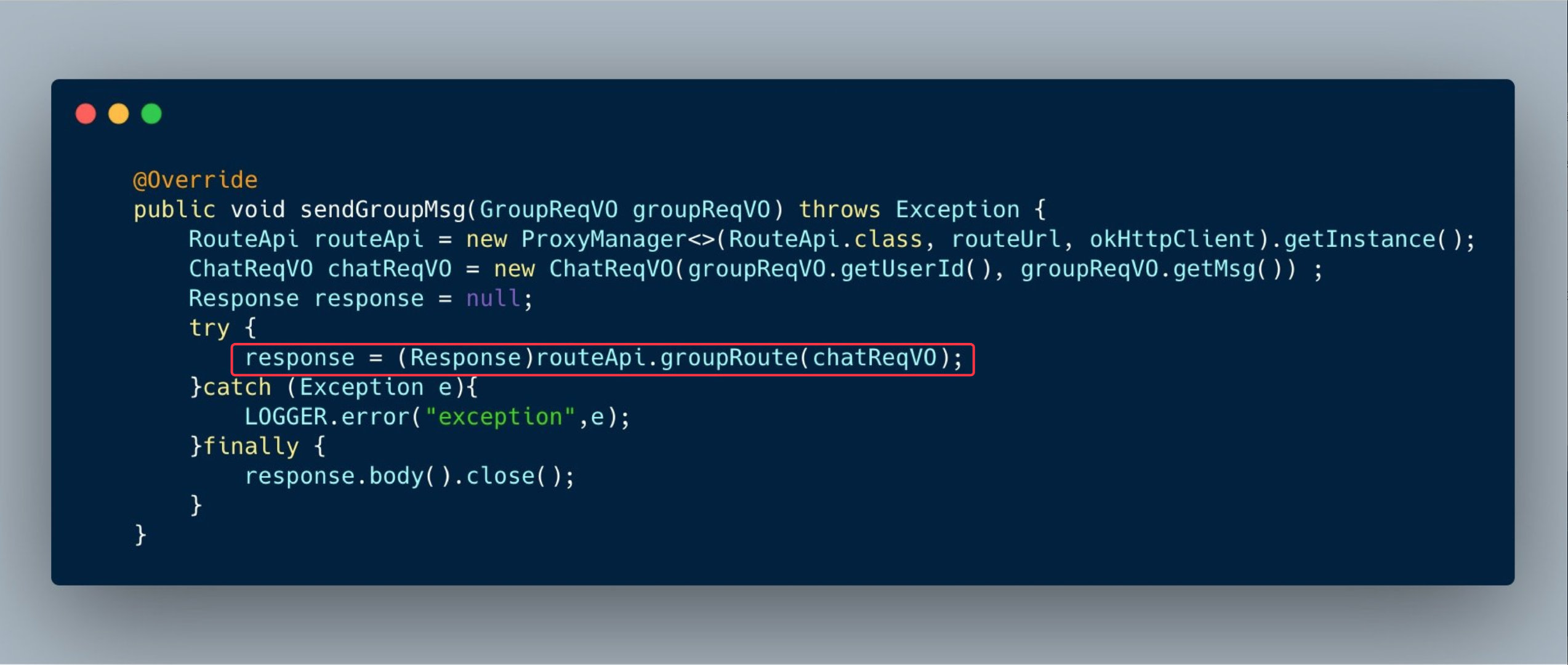
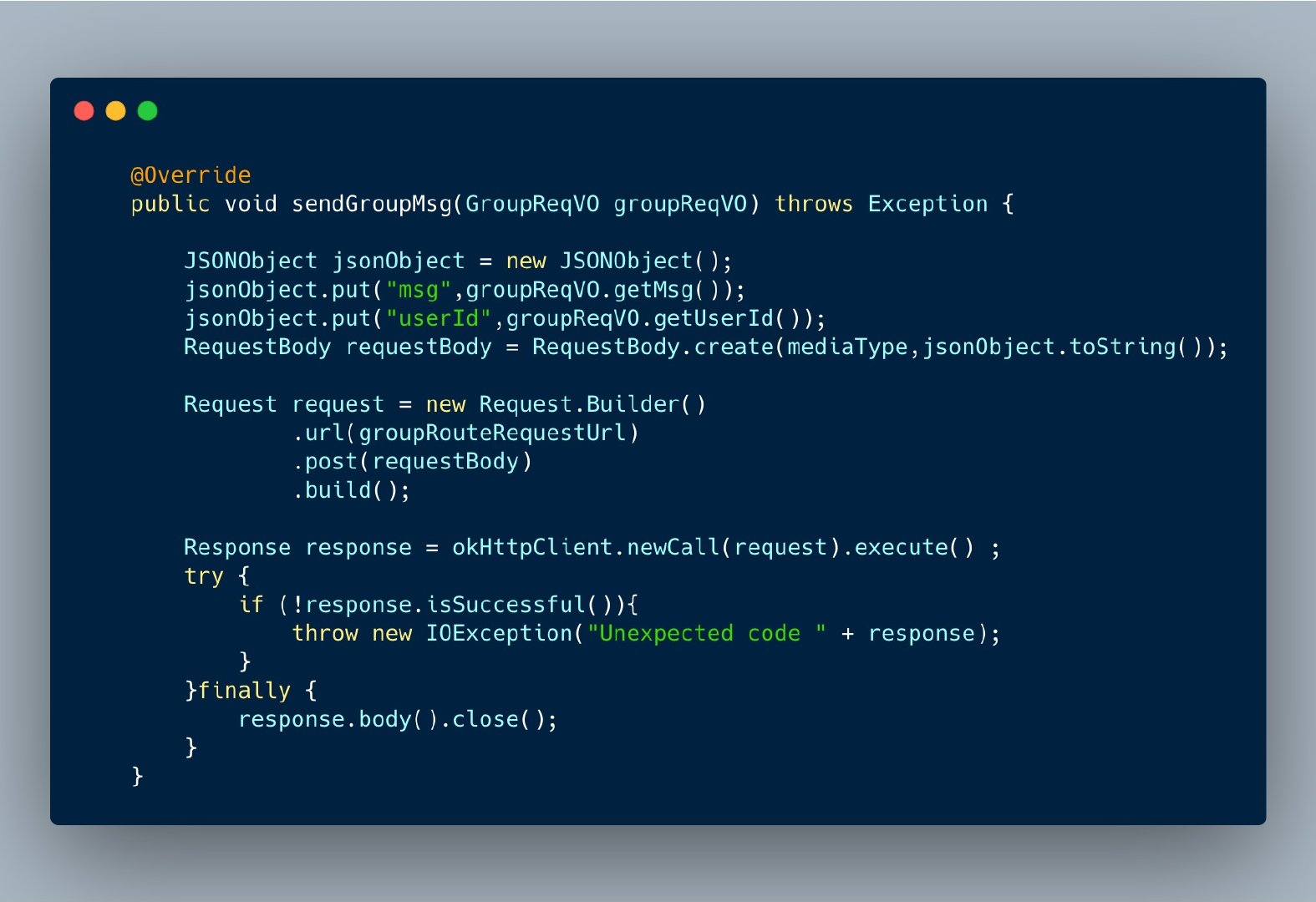
这里我截取了 ClientA 向 Route 发起请求的代码: ![]() 可以看到这就是利用
可以看到这就是利用 okhttp 发起了一个 http 请求,这样虽然能实现功能,但其实并不优雅。
举个例子:假设我们需要对接支付宝的接口,这里发送一个 http 请求自然是没问题;但对于支付宝内部各部门直接互相调用接口时那就不应该再使用原始的 http 请求了。
应该是由服务提供方提供一个 api 包,服务消费者只需要依赖这个包就可以实现接口调用。
当然最终使用的是 http、还是自定义私有协议都可以。
也类似于我们在使用 Dubbo 或者是 SpringCloud 时,通常是直接依赖一个 api 包,便可以像调用一个本地方法一样调用远程服务了,并且完全屏蔽了底层细节,不管是使用的 http 还是 其他私有协议都没关系,对于调用者来说完全不关心。
这么一说是不是有内味了,这不就是 RPC 的官方解释嘛。
对应到这里也是同样的道理,Client 、Route、Server 本质上都是一个系统,他们互相的接口调用也应当是走 RPC 才合理。
所以我重构之后的变成这样了:
![]()
是不是代码也简洁了许多,就和调用本地方法一样了,而且这样也有几个好处:
- 完全屏蔽了底层细节,可以更好的实现业务及维护代码。
- 即便是服务提供方修改了参数,在编译期间就能很快发现,而像之前那样调用是完全不知情的,所以也增加了风险。
绕不开的动态代理
下面来聊聊具体是如何实现的。
其实在上文《动态代理的实际应用》 中也有讲到,原理是类似的。
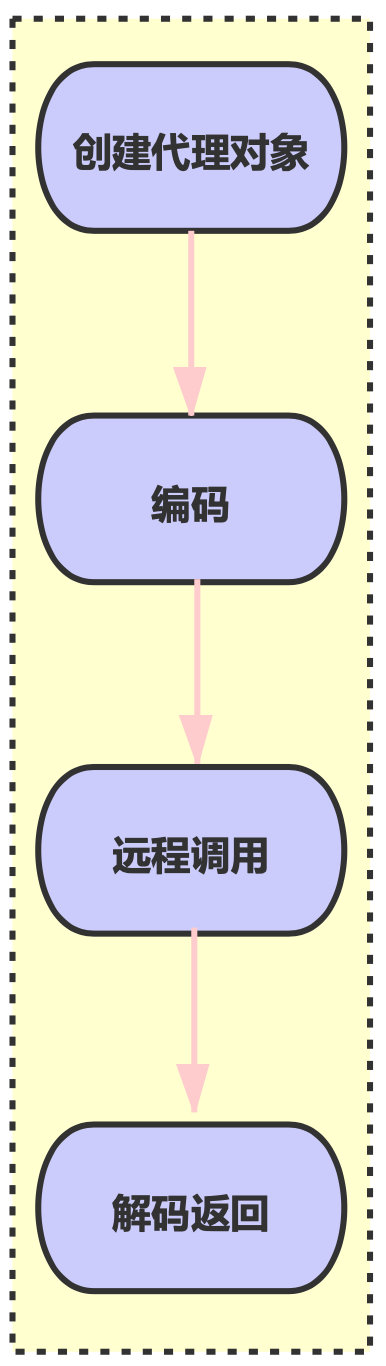
要想做到对调用者无感知,就得创建一个接口的代理对象;在这个代理对象中实现编码、调用、解码的过程。
![]()
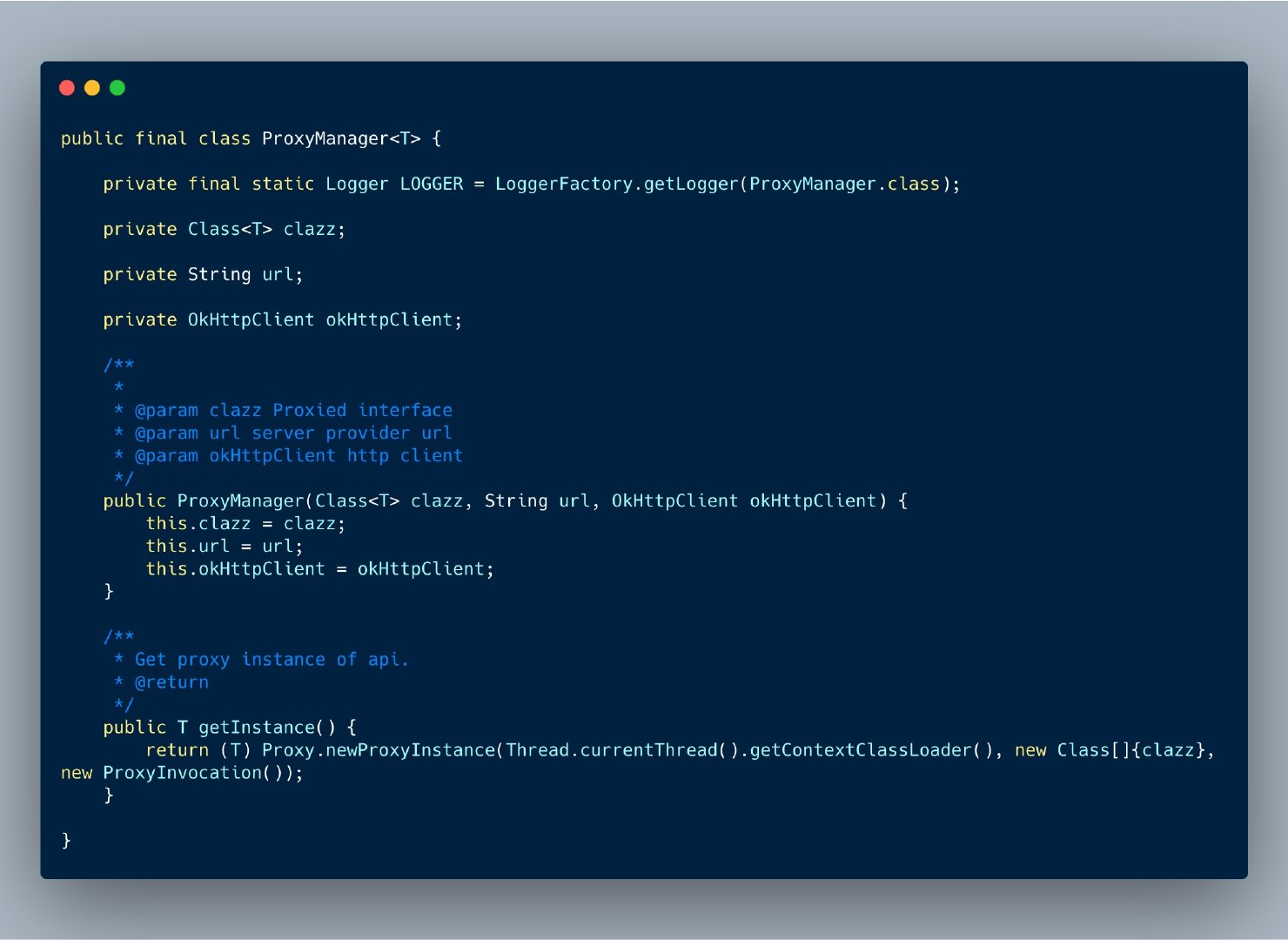
对应到此处其实就是创建一个 routeApi 的代理对象,关键就是这段代码:
RouteApi routeApi = new ProxyManager<>(RouteApi.class, routeUrl, okHttpClient).getInstance();
完整源码如下: ![]()
其中的 getInstance() 函数就是返回了需要被代理的接口对象;而其中的 ProxyInvocation 则是一个实现了 InvocationHandler 接口的类,这套代码就是利用 JDK 实现动态代理的三板斧。
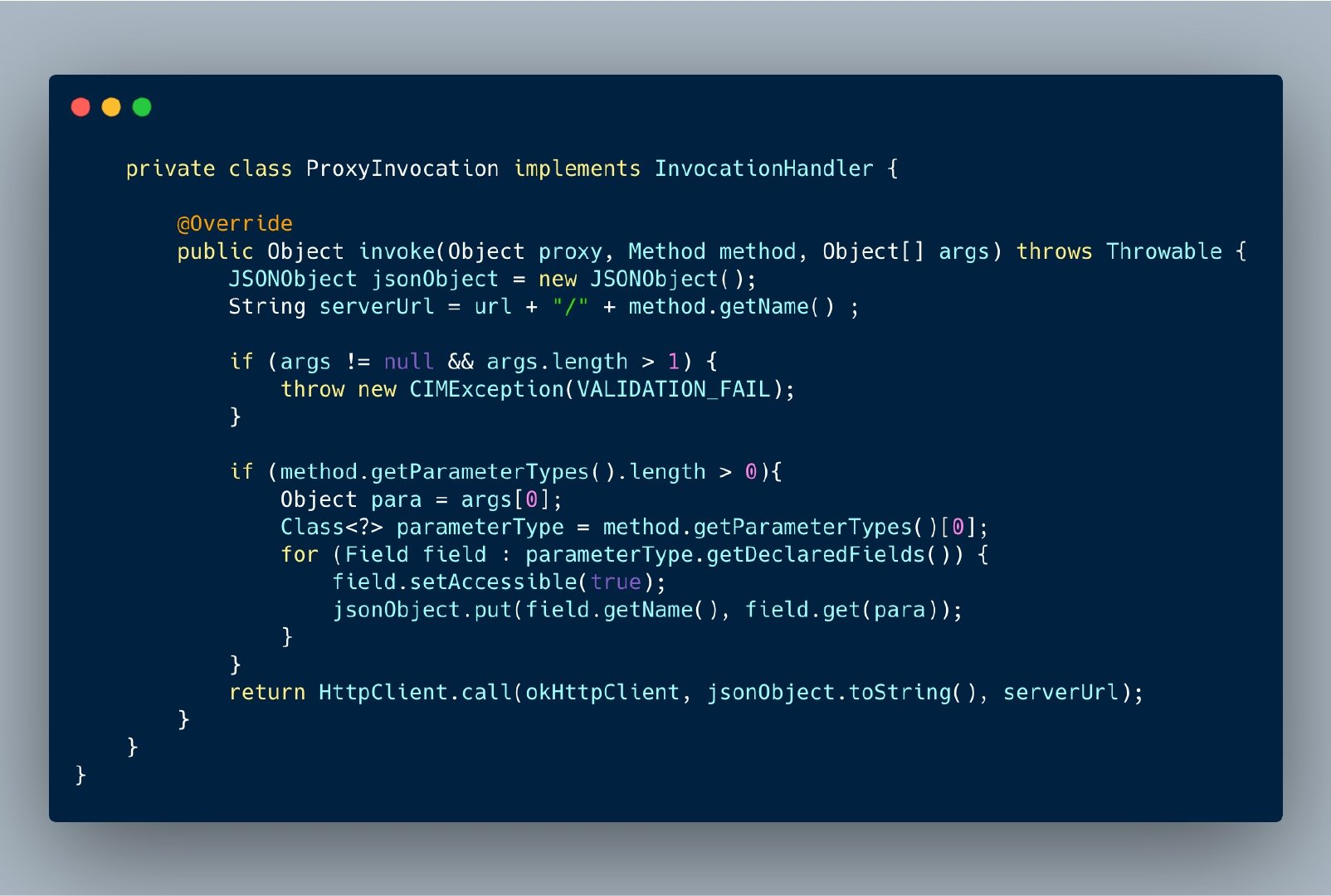
![]()
查看 ProxyInvocation 的源码会发现当我们调用被代理接口的任意一个方法时,都会执行这里的 invoke() 方法。
而 invoke() 方法自然就实现了上图中提到的:编码、远程调用、解码的过程;相信大家很容易看明白,由于不是本次探讨的重点就不过多介绍了。
总结
其实理解这些就也就很容易看懂 Dubbo 这类 RPC 框架的核心源码了,总体的思路也是类似的,只不过使用的私有协议,所以在编解码时会有所不同。
所以大家要是想自己动手实现一个 RPC 框架,不妨参考这个思路试试,当用自己写的代码跑通一个 RPC 的 helloworld 时的感觉是和自己整合了一个 Dubbo、SpringCloud 这样的第三方框架的感觉是完全不同的。
本文的所有源码:
https://github.com/crossoverJie/cim
你的点赞与分享是对我最大的支持

 可以看到这就是利用
可以看到这就是利用