前言:为什么要搭建集群?
通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取。Redis是一个很好的Cache工具。大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事儿。由于内存大小的限制,使用一台 Redis 实例显然无法满足需求,这时就需要使用多台 Redis作为缓存数据库。但是如何保证数据存储的一致性呢,这时就需要搭建redis集群.采用合理的机制,保证用户的正常的访问需求.采用redis集群,可以保证数据分散存储,同时保证数据存储的一致性.并且在内部实现高可用的机制.实现了服务故障的自动迁移.
---linux系统为dsCentOS-empty
1.Redis集群搭建
主从划分:
3台主机 3台从机共6台 端口划分7000-7005
1.1集群搭建
1.1准备集群文件夹
1.准备集群文件夹
Mkdir cluster
2.在cluster文件夹中分别创建7000-7005文件夹
cd cluster
mkdir 7000 7001 7002 7003 7004 7005
1.2复制配置文件
将redis根目录中的redis.conf文件复制到cluster/7000/ 并以原名保存
cp redis.conf cluster/7000/
1.3编辑配置文件
1.注释本地绑定IP地址
![在这里插入图片描述]()
2.关闭保护模式
![在这里插入图片描述]()
3.修改端口号
![在这里插入图片描述]()
4.启动后台
![在这里插入图片描述]()
5.修改pid文件
先保存退出,在7000文件目录下输入pwd,复制路径
![在这里插入图片描述]()
再次进入路径为上面7000文件的路径
![在这里插入图片描述]()
6.修改持久化文件路径(与5中的路径相同)
![在这里插入图片描述]()
7.设定内存优化策略(自定义)
![在这里插入图片描述]()
8.关闭AOF模式
![在这里插入图片描述]()
9.开启集群配置
![在这里插入图片描述]()
10.开启集群配置文件
![在这里插入图片描述]()
11.修改集群超时时间
![在这里插入图片描述]()
12.保存配置信息退出
1.4 复制修改后的配置文件
说明:将7000文件夹下的redis.conf文件分别复制到7001-7005中
[root@localhost cluster]# cp 7000/redis.conf 7001/
[root@localhost cluster]# cp 7000/redis.conf 7002/
[root@localhost cluster]# cp 7000/redis.conf 7003/
[root@localhost cluster]# cp 7000/redis.conf 7004/
[root@localhost cluster]# cp 7000/redis.conf 7005/
1.5 批量修改
分别将7001-7005文件中的7000改为对应的端口号的名称,修改时注意方向键的使用。
批量修改端口号:%s/7000/7001/g
![在这里插入图片描述]()
1.6通过脚本编辑启动/关闭指令
1.创建启动脚本 vim start.sh
![在这里插入图片描述]()
2.创建关闭脚本 vim stop.sh
![在这里插入图片描述]()
记住保存退出!!!
3.启动redis 节点
sh start.sh
4.检查redis节点启动是否正常
![在这里插入图片描述]()
1.7创建redis集群
#5.0版本执行
redis-cli --cluster create --cluster-replicas 1 192.168.126.166:7000 192.168.126.166:7001 192.168.126.166:7002 192.168.126.166:7003 192.168.126.166:7004 192.168.126.166:7005
在type 'yes' to accept 那里输入yes
![在这里插入图片描述]()
这张图采用于我的老师,因为我的已经搭建完全,不忍心充型搭建,请谅解啊!!!
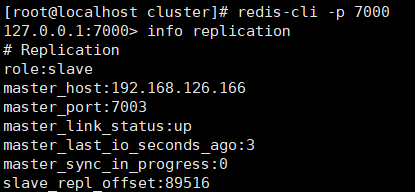
1.8 Redis集群高可用测试
- 1.关闭redis主机.检查是否自动实现故障迁移.
- 2.再次启动关闭的主机.检查是否能够实现自动的挂载.
一般情况下 能够实现主从挂载
个别情况: 宕机后的节点重启,可能挂载到其他主节点中(7001-7002) 都是正确的
![在这里插入图片描述]()